一、视频学习心得及问题总结
1. 学习心得
王嘉毅:
在人工智能高速发展的21世纪,机器学习的相关技术不断革新,人类距离机器认知智能的终极目标更进一步。
深度学习,是一种特殊的机器学习方法,它应用了深度神经网络,通过在输入中先提取出简单的特征,再计算出更为复杂的特征,最后映射出输出结果。然而深度学习仍有一些问题亟待解决,如深度学习的算法输出不稳定,容易受到攻击;复杂度高难以调试,参数不透明,模型增量型差;容易产生机器偏见等。此外,深度学习与知识图谱逐渐从对立走向协同发展的方向。
神经网络,最早源于生物学概念,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。三层前馈神经网络能以任意精度逼近任意预定的连续函数。神经网络学习如何利用矩阵的线性变换和激活函数的的非线性变换,将原始输入空间投影到线性可分空间,从而进行分类或回归。
王泓元:
目前,越来越多的行业可以通过深度学习技术来进行革新,深度学习方面的人才也处于紧缺的状态。视频对深度学习进行了介绍,讲解了一些神经网络基础的概念、定理和算法,让我们了解了一些深度学习的基本知识。为之后的学习打下基础。
范新东:
第一个视频主要是介绍了深度学习、机器学习以及人工智能三者的关系,以及各个技术的发展历程。第二个视频则从时间的角度逐步分析神经网络的发展。
过程笔记:
◆ 学习神经网络笔记
万文龙:
此前经常有听到人工智能、机器学习和深度学习的概念,但是对这些概念只有一点简单的认识,今年暑假开始学习了一些深度学习的内容,也是稍微对这些概念有了一点了解,自己也上网搜过过,不过还是对人工智能和机器学习、机器学习和深度学习之间的关系,他们的区别在哪里还不是很理解。第一个视频中对这方面的历史和发展的讲解,以及谈了它们之间的区别,尤其是下面这张图,应该是解决了我的一个问题。
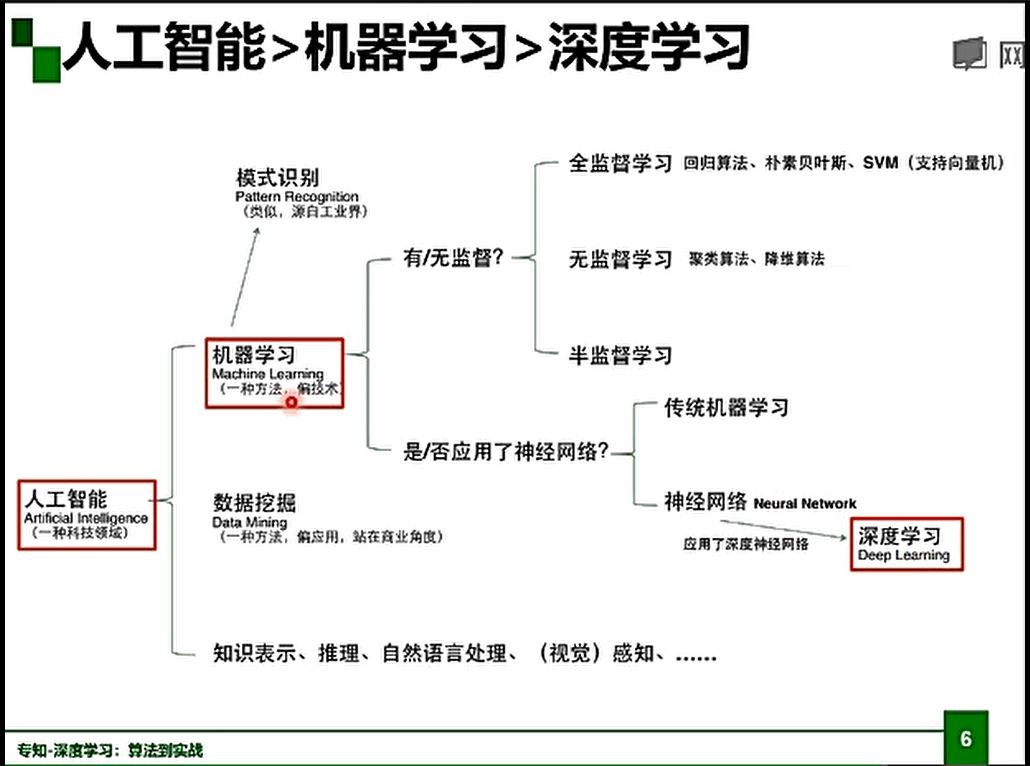
第二个点就是对机器学习适合应用的领域,从规则的复杂程度和计算上的复杂程度把问题划分为四种,在规则和计算都比较复杂的情况下,机器学习就可以发挥其优势,通过计算机对数据集的训练,让计算机自己去学习出规则。顺带一提,视频里的很多图片很多都总结得很好。
虽然我对深度学习的了解不深,但是对深度学习结果难理解还是表示赞同,比如CNN学习出来的那么多参数,到靠后的层数时它们就很难理解了;另外个人观点,机器学习学出来的东西还是通过数据,即使能够用来解决问题,还只是一些类似的问题,机器不能完全的凭空创造,机器自己创造的可能也还是一个东拼西凑出来的东西,所以感觉今天的人工智能仍然算不上真的人工智能。
单岳超:
绪论讲述了什么是人工智能、人工智能的起源、人工智能发展标志性事件、人工智能发展阶段及其三个层面。人工智能的定义可以分为两部分,即“人工”和“智能”(更重要),“智能”涉及到如意识、自我、思维(包括无意识的思维)等多钟问题。其中,三个层面:计算智能(快速计算和记忆存储能力 )、感知智能(视觉、听觉、触觉等感知能力)、认知智能(能理解会思考)极其重要。
机器学习(涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等),其研究对象为人工智能。其研究方向包含决策树、随机森林、人工神经网络、贝叶斯学习等方面。机器学习可以根据学习方法、学习方式、数据形式等等会有不同的分类,并且随着大数据时代对数据分析需求的持续增加,通过机器学习高效地获取知识,已慢慢成为当今机器学习技术发展的主要推动力。
深度学习概论:深度学习作为机器学习领域中的一个新研究方向,在语音和图像识别方面取得了卓越的效果,其在机器翻译,自然语言处理,多媒体学习等方面研究成果颇丰。深度学习的本质是深度网络能够发现并刻画问题内部复杂的结构特征,进而较大地提高性能。优点也很明显:在计算机视觉和语音识别方面成果比传统机器学习方法更优越;具有较好的transferl earning性质,训练好的模型可以在多个个问题上做一些简单的应用。而其缺点也凸显出来:训练耗时,模型正确性验证复杂并且麻烦;算法输出不稳定,容易被攻击。
神经网络(人工神经网络):一种进行分布式并行信息处理的算法数学模型。其通常表现为相互连接的“神经元”,通过输入的计算值,来进行机器学习以及模式识别它们的自适应性质的系统。神经网络的层数并不是越多越好(层数越多,可能会导致梯度消失)。二层神经网络(理论上可以拟和任何函数),可以分为输入层、激活层、输出的正规化、衡量输出的好坏、反向传播与参数优化、迭代六个过程,但在实际中,三层神经网络效果最优。
2. 问题总结:
王嘉毅:
在视频学习过程中,我对神经网络的原理有了初步了解,但对其相关公式的数学证明过程仍有疑惑;此外,我对支持向量机、梯度消失问题的解决方法、凸二次规划等问题仍有疑惑,需要具体深入学习。
王泓元:
误差反向传播的三层前馈神经网络的BP算法很难理解,同时对梯度消失的理论不是很懂。
范新东:
无法理解梯度的概念,对深度学习的机理仍感到模糊。不知道我这样想对不对:训练的过程其实就是在寻找最小梯度的过程,而整个数据的最小梯度是很难找的,尤其是有多个极小梯度的时候。而神经网络的发展就是在研究如何找到最小梯度的过程。
万文龙:
视频对机器学习、深度学习的很多方面都进行讲述,但是到一些比较细节的地方我就感觉听不大懂了,以及一些技术突然就提到感觉比较茫然。没有听懂的点有:误差反向传播、受限波尔茨曼机和自编码器、贝叶斯分类(先验概率和后验概率在机器学习里面的作用)。
单岳超:
1. 神经网络为什么可以在理论上拟合任何函数?其可以无限逼近任何连续函数吗?
2. 深度学习和深度强化学习之间的差别有多大?
3. 怎么看待物理学家John Martinis所说的十年后机器学习将全部量子化?
二、代码练习(关键步骤截图、想法和解读)
1. pytorch基础练习:
这一部分主要是PyTorch和它的一些功能介绍。
首先,定义数据:
然后定义操作:
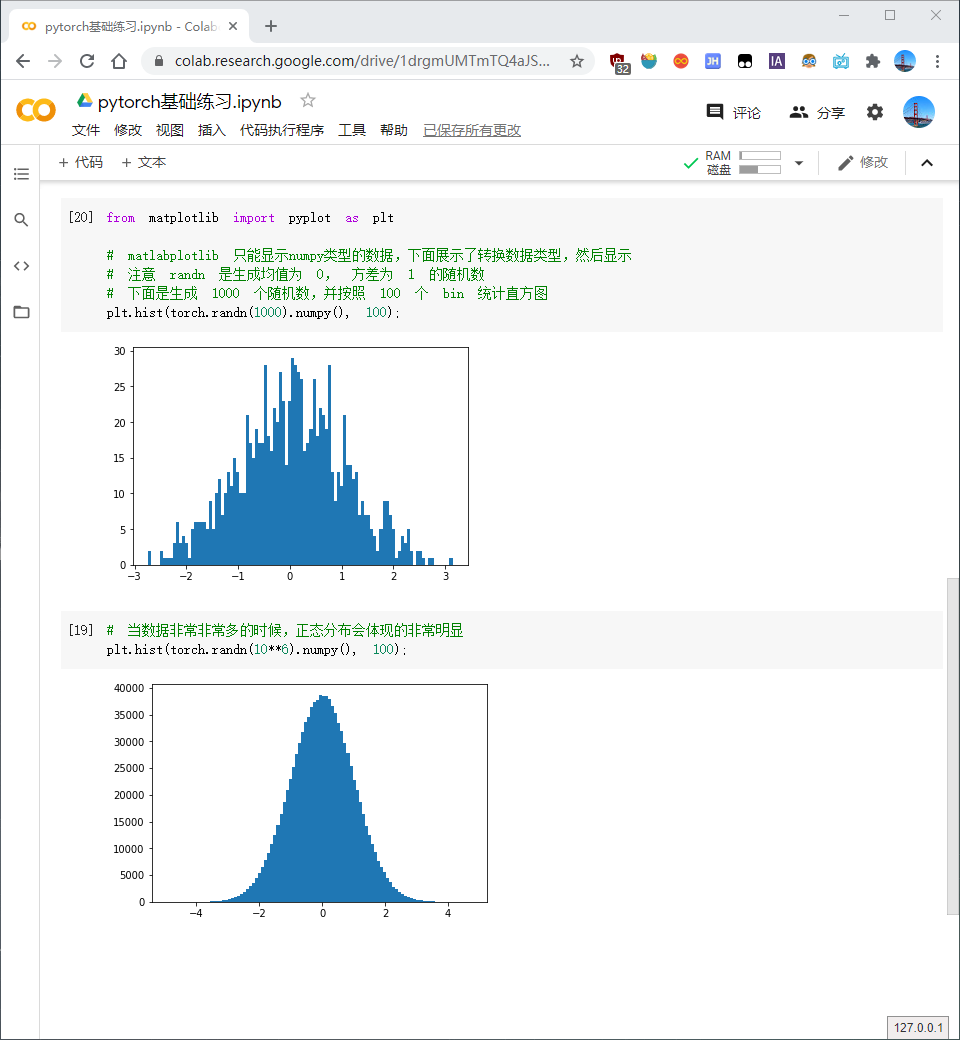
生成 1000 个随机数,并按照 100 个 bin 统计直方图,当数据非常非常多的时候,正态分布会体现的非常明显:
想法:
- 通过这个程序简单地了解pytorch,它是基于Python的可续计算包,拥有两个高级功能:具有强大的GPU加速的张量计算(如NumPy)和包含自动求导系统的的深度神经网络,相当简洁并且高效快速。其次,tensor是特有的数据类型,可以由多种数据类型创建。经过查阅资料了解:在深度学习中,Tensor实际上就是一个多维数组,其目的是能够创造更高维度的矩阵、向量。
2. 螺旋数据分类
首先引入基本的库,然后初始化重要参数。
构建线性模型分类:
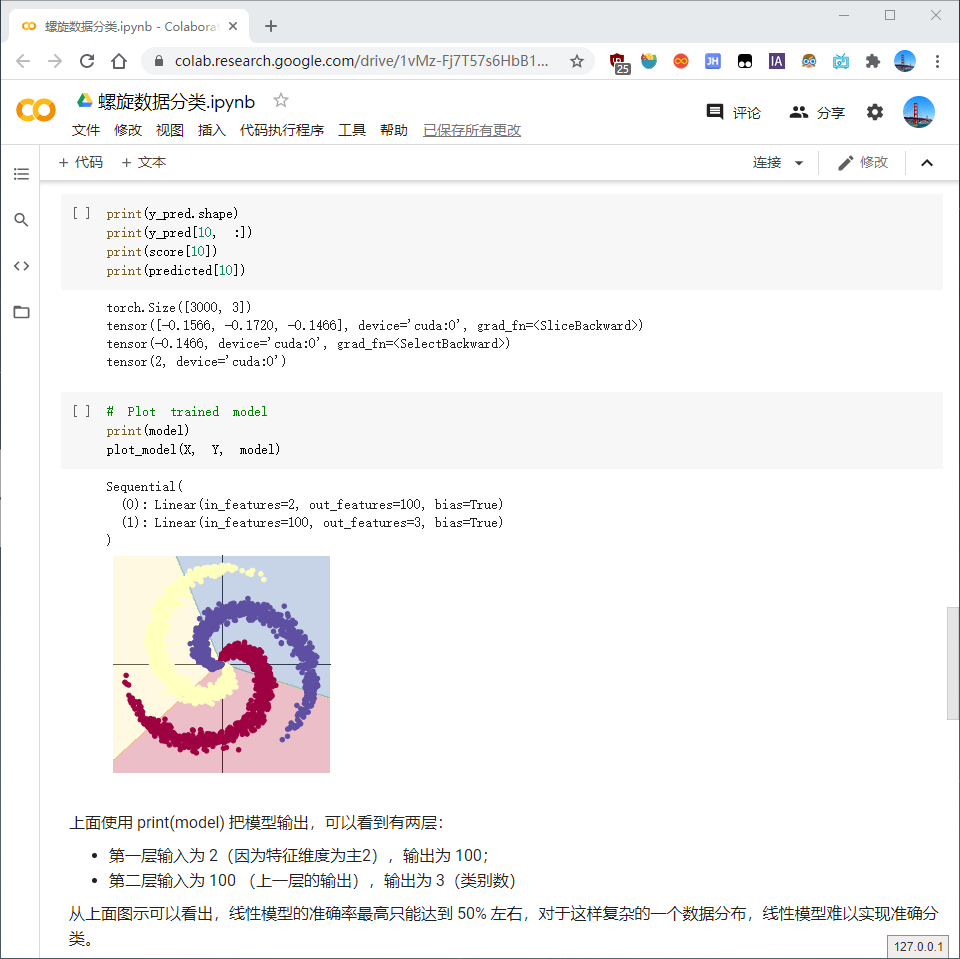
使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。每一次反向传播前,都要把梯度清零。
构建两层神经网络分类:
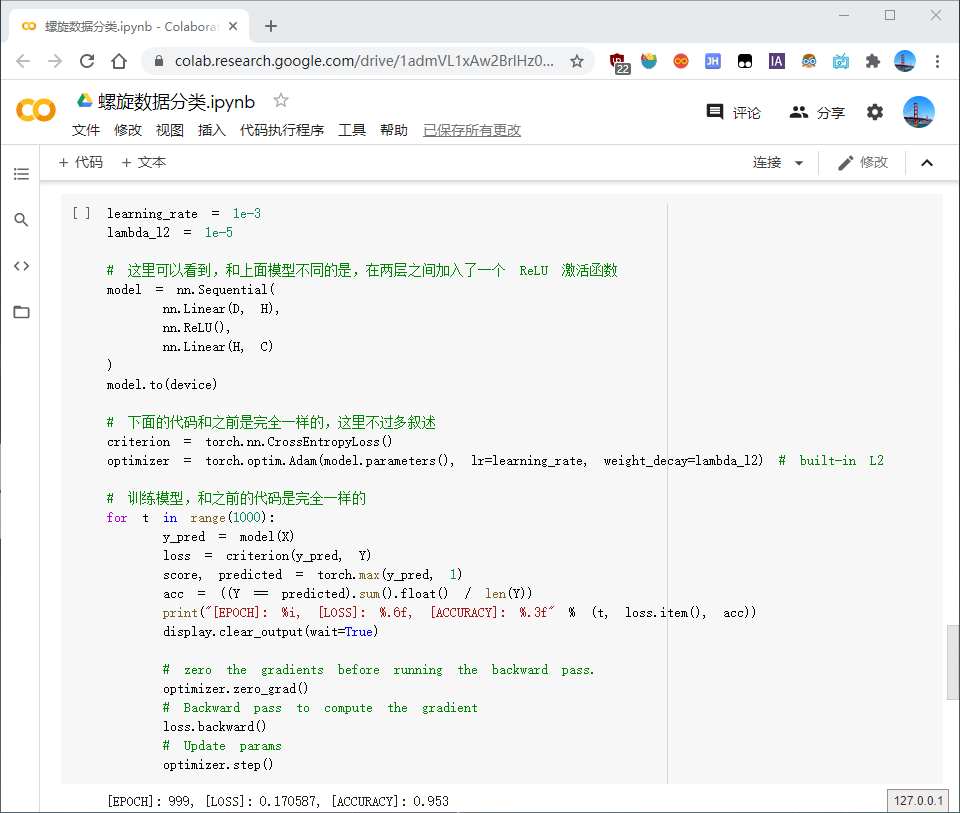
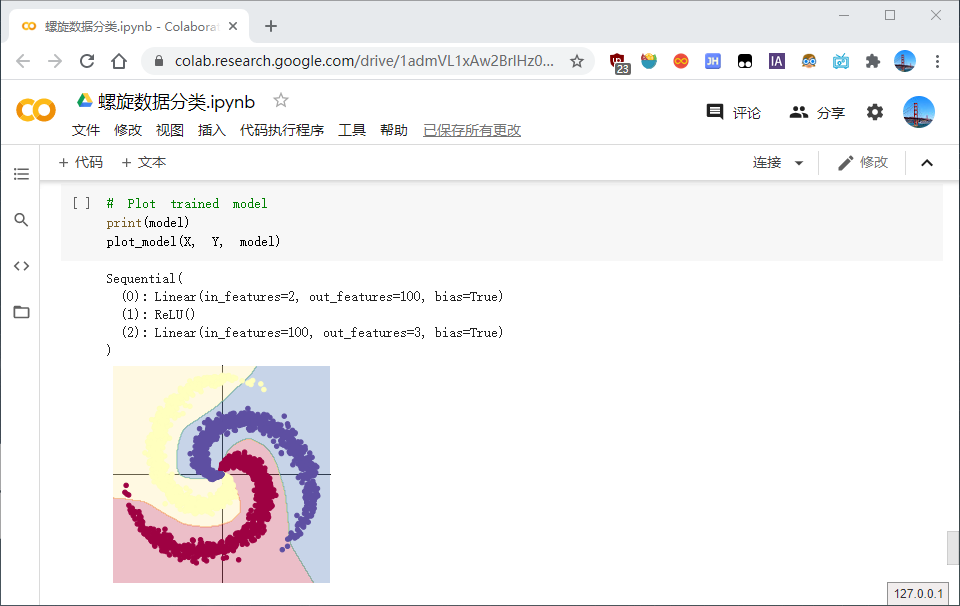
在两层神经网络里加入 ReLU 激活函数以后,分类的准确率得到了显著提高。
想法:
- 简单浏览代码及注释,训练模型是将数据传入进模型产生对应的结果,进而得到误差,通过误差反向传播来优化参数。但如果仅仅用线性模型(sigmoid函数)来做螺旋数据的分类,其准确率最高只能达到50% 左右(因为sigmoid函数梯度弥散),相反,测试ReLU、Tanh,发现其都比sigmoid好。
- 用随机梯度下降使结果不断朝更好处逼近;使用损失函数来衡量模型预测的质量;用反向传播(利用链式法)计算中间的参数;Relu函数使输入的负数部分为0,获得非线性的结果。
- 不太理解的内容:这些东西在内部究竟是如何起作用的,比较线性模型nn.Linear具体是如何工作的,为什么能达到如此神奇的效果,上网搜索了关于此的源码,将输入到输出做一个线性变换加偏移( ext{y}= ext{xA}^{ ext{T}}+ ext{b}) 的操作,对从这一步如何跳到最后将每个点预测分类的步骤仍有疑惑。