数据抓取方式选择:
要编写爬虫程序,首先需要选择数据抓取的方式,一般来说有如下两种:
-
对服务器发送Http请求,获取响应信息
-
利用浏览器发送请求,获取渲染完成后的数据
这里我选择方式2,具体原因我在之前的Blog文章使用Chrome快速实现数据的抓取(四)——优点中已经做过对比分析,简单来说就是使用浏览器除了性能开销较大外,其它方面基本上秒杀发送HTTP请求的原始方式。
浏览器接口:
对于浏览器的选择,我这里支持的是Chrome。Chrome提供了比较完善的开发接口Devtool Protocol,这个接口非常强大,基本可以实现自带的DevTool能实现的任何功能。该协议本身也有各种开源的实现,要想使用这个协议驱动Chrome实现蜘蛛程序,可以有如下方式:
-
直接编写协议解析程序,然后再封装为蜘蛛类库
-
使用其他的开源协议解析程序,然后再封装为蜘蛛类库
-
在别人封装好的蜘蛛类库(如puppeteer-sharp)上二次封装
由于该协议比较简单,实现起来不难,加上只需要实现需要的部分接口即可,工作量也不大。自己实现所需要的时间并不比理解别人的实现和踩坑的需要的多,因此我采用了自己实现的方式,也更加具有可控性。
Devtool Protocol:
Devtool Protocol的协议定义可以在Github上查看,我之前也写了几篇文章介绍过它,
主要是一个基于Websocket的协议,具体就不多介绍了,感兴趣的朋友可以看看我上面的文章或Chrome的官方文档。
辅助工具:
之前开发Devtool Protocol一个主要的问题是,官网描述了一大堆api,往往不知道怎么组合这些api实现我们需要的功能,需要查阅大量文档。现在Chrome提供了一个辅助工具Protocol Monitor帮助我们简化这一过程
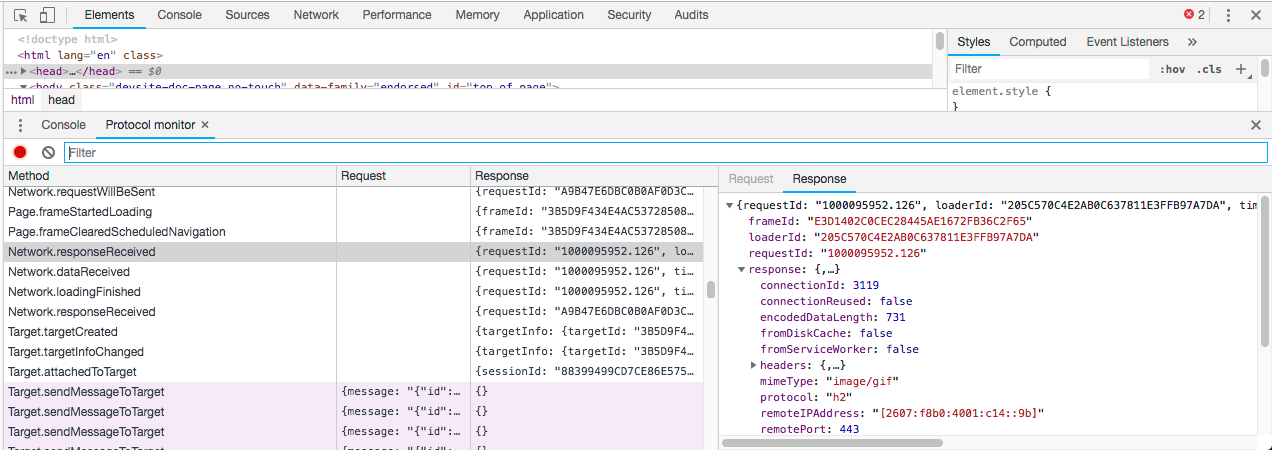
当我们操作开发者工具时,相关的操作都转化成了可以通过Devtool Protocol的接口实现的脚本,类似于开发者工具的操作日志。只要我们先用开发者工具进行操作,然后分析Protocol Monitor记录的日志,就可以通过代码回放实现同样的效果,非常给力。

这个工具目前还是预览版,默认是没有开放的,可以通过如下步骤开启它。