一、什么是pb协议?
ProtoBuff是一种将结构化数据进行序列化和反序列化的方法。它的作用类似XML,它的优势主要体现在序列化后的数据小以及数据解析速度快。
适用于对数据序列化后体积以及速度要求严格的场景,如在即时通信领域,移动端与服务器的交互比桌面端与服务器的交互更适合使用pb协议。
二、pb与其他序列化机制对比
同为序列化机制,pb相比于更加常见的用户数据交互的XML 、json各自有啥特点呢?
1、json: 是一种轻量级的数据交换格式。使用键值对的方式对数据进行封装。使用简单,可读性较高,但不能表达复杂数据类型。一般的web项目中,最流行的主要还是json。因为浏览器对于json数据支持非常好,有很多内建的函数支持。
2、xml: 使用闭合标签对数据进行封装。在webservice中应用最为广泛,但是相比于json,它的数据更加冗余,因为需要成对的闭合标签。json使用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。
3、protobuf:是后起之秀,是谷歌开源的一种数据格式,适合高性能,对响应速度有要求的数据传输场景。因为profobuf是二进制数据格式,需要编码和解码,编码和解码双方必须有共同的proto文件。数据本身不具有可读性。因此只能反序列化之后得到真正可读的数据。
---------------------
以上参考:https://blog.csdn.net/u014043213/article/details/80336805
如果已经决定使用pb,那么pb该怎么用呢?
三、怎么使用pb?
序列化基本步骤:
定义proto文件 --> 编译proto文件 --> 导入编译后文件 --> 对消息中各个字段复制 -->序列化(即, 调用SeriotoString()得到二进制字符串)
反序列化基本步骤:
获取与序列化过程一致的proto文件 -->
下面以python语言下的序列化过程为例介绍:
1、按照pb格式要求编写proto文件;
一个简单的message格式:
Message 消息名{ 字段规则 字段类型 字段名 = 分配标识号; } 字段规则:required(必须设置) 、 optional(可以有0或1个) 、repeated(可以有0或多个) 字段类型:可以是标准类型、枚举类型、自定义message类型 分配标识名:1、2、3……
2、使用pb编译器对proto文件进行编译:
protoc -I=$SRC_DIR --python_out=$DST_DIR $SRC_DIR/你的.proto文件名
需要指定源目录(应用程序源码目录——如果不提供这个目录,默认就是当前目录),目标目录(你的应用程序编译后生成的代码的目录;通常用$SRC_DIR), 还有.proto文件的目录路径.此时对应的.py文件就会生成在指定的目标目录中.因为我们case的编写框架为python,我们想生成Python的类,所以用–python_out选项,也有类似的选项支持其它语言,例如生成C++的类,用–cpp_out选项
3、在项目中导入pb编译生成的类文件:
4、创建类对象,并为对象的对各个字段进行赋值
5、调用SerializeToString()方法进行序列化。
---------------------
参考:
https://developers.google.cn/protocol-buffers/docs/overview
https://www.sohu.com/a/168549441_216613
https://www.cnblogs.com/tohxyblog/p/8974763.html
https://www.jianshu.com/p/2265f56805fa
四、使用pb中的坑
1、pb在进行编码和解码时必须使用相同的.proto文件,之前一次工作中,仅仅更新了编码端的协议文件,服务器上文件未更新,总是出错,又是重新编译,又是反复看在编码端编译出来的类文件 ,折腾了好久,最后才意识到是两边的文件不一致,导致无法正常解析。其实这也体现了pb文件在使用过程中的一个缺点。普通序列化方式,只要在服务器端打出日志,传输的字段有没有错误就很显而易见,但是由于pb序列化的数据都是二进制格式的,日志打印出来都是乱码,如果真的遇到业务错误,也不太直接看出来是传输字段有错误还是其他哪里的错误。不过,一般情况下严格按照步骤使用,出错倒是不多。
2、repeated修饰符修饰的字段在使用时候的有一个注意点。在工作中,遇到过一个情况是,message中某个字段的字段规则是repeated,字段类型是自定义message类型。在这种场景下,对字段进行赋值的时候,需要先对自定义类型message的字段调用add方法,初始化新实例;然后对新实例中的每个元素进行赋值。例如:
message格式--
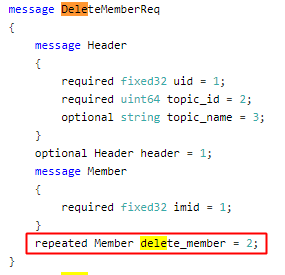
字段赋值过程--
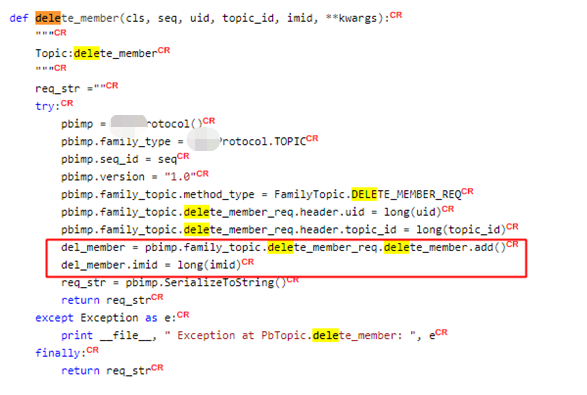
Repeated修饰字段赋值注意:
对基本message类型,直接赋值;
对自定义message类型,调用add方法初始化新实例,再对实例中每个元素赋值