0.PTA得分截图

1.本周学习总结
1.1 总结线性表内容
* 一.顺序表:

-
顺序表存储结构:把线性表中的所有元素按照顺序存储方式进行存储的结构成为顺序表。
-
顺序存储的优缺点:
优点:
1.逻辑相邻,物理相邻
2.无须为表示表中元素之间的顺序关系增加额外的存储空间
3.可随机存取任一元素
4.存储空间使用紧凑
缺点:
1.插入、删除操作需要移动大量的元素(除操作在表尾的位置进行外)
2.预先分配空间需按最大空间分配,利用不充分
3.表容量难以扩充
-
顺序表的特点:1.实现数据元素逻辑上相邻即物理地址相邻;
2.可以实现数据元素的随机存取;(以数组的形式存储)
图示如下:

-
顺序表的结构体定义:
栈区例子:
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize]; //存放顺序表元素
int length ; //存放顺序表的长度
} List;
typedef List *SqList;
堆区例子:
#define MAXSIZE 100//最大长度
typedef struct
{
ElemType* elem;//指向数组元素的基地址
int length;//线性表当前长度
}SqList;
* 顺序表基本操作
- 顺序表的初始化:(创建一个新链表)
void CreateList(SqList& L, int n)
{
int index = 0;
//初始化顺序表
L = new List;
L->length = n;
//给表中数据元素赋值
while (n--)
cin >> L->data[index++];
}

- 顺序表的删除:(时间复杂度O(1))
void DeleteList(SqList* &L)
{
delete L;
}
- 判断是否为空表:
bool ListEmpty(List L)
{
return(L->length == 0);
}
- 计算表的长度:
int ListLength(List L)
{
return(L->length);
}
- 顺序表输出数据:(时间复杂度O(n))
void DispList(List L)
{
int i;
if (L->length == 0)
{
cout << "NULL";
}
else
{
for (i = 0; i < L->length; i++)
cout << L->data[i] << " ";
}
}
- 顺序表查找数据:
查找第i个元素:(时间复杂度O(1))
返回L中第i个元素的值,存放在e中。1≤i≤ListLength(L)
bool GetElem(List L,int i,ElemType &e){
if (i<1 || i>L->length)
return false;
e=L->data[i-1];
return true;
}
按元素值查找:(时间复杂度O(n))
将顺序表中的元素逐个和给定值 e 相比较。
int LocateElem(List L, ElemType e){
for(int i=0; i<L->length;i++)
if(L->data[i]==e)
return i+1; //返回元素的逻辑位序
return 0;
}
- 顺序表插入数据(时间复杂度O(n))
*插入做法步骤:
1.找插入位置;
2.数组元素a[i]到a[n]后移一位;
3.a[i]插入数,length加一;
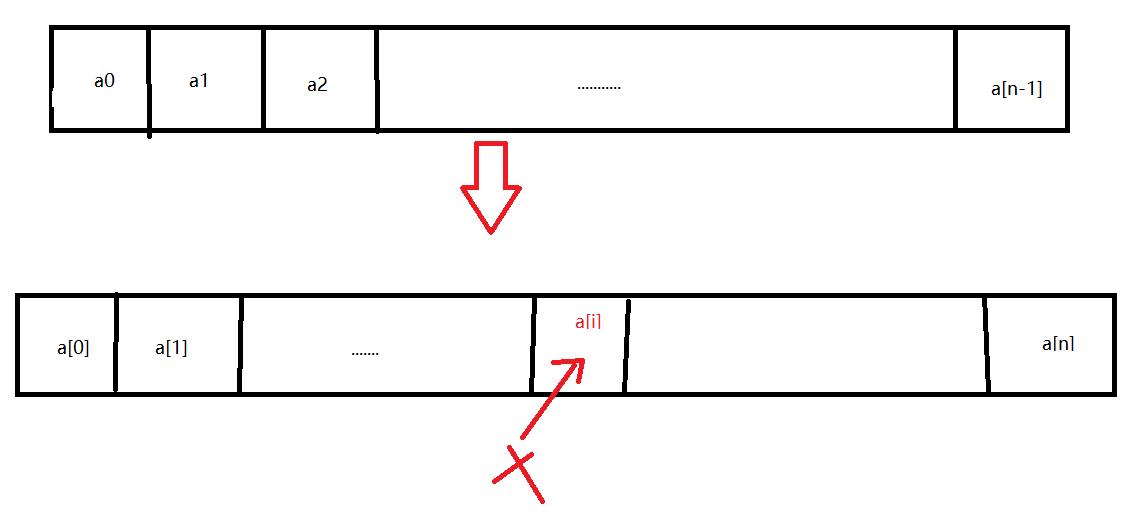
插入数据代码:
bool ListInsert(List &L,int i,ElemType e)
{ int j;
if (i<1 || i>L->length+1)
return false; //参数错误时返回false
i--; //将顺序表逻辑序号转化为物理序号
for (j=L->length;j>i;j--) //将data[i..n]元素后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e; //插入元素e
L->length++; //顺序表长度增1
return true; //成功插入返回true
}
插入数据注意点:
元素移动的次数:
-
当i=n+1,移动次数为0;
-
i,移动次数n-i+1
-
当i=1,移动次数为n,达到最大值。
-
共有n+1个插入位置,概率pi=1/n+1
-
移动元素的平均次数为:
n/2 O(n) -
顺序表中元素的删除

相关代码:
bool ListDelete(List &L,int i,ElemType &e)
{
if (i<1 || i>L->length) //删除位置不合法
return false;
i--; //将顺序表逻辑序号转化为物理序号
e=L->data[i];
for (int j=i;j<L->length-1;j++)
L->data[j]=L->data[j+1];
L->length--; //顺序表长度减1
return true;
}
删除元素时间复杂度:
- 当i=n时,移动次数为0;
- 当i=1时,移动次数为n-1。
- 假设pi是删除第i个位置上元素的概率:1/n
- 则在长度为n的线性表中删除一个元素时所需移动元素的平均次数为:
(n-1)/2 O(n)
* 二.单链表:
链表是线性表的链式存储
-
结构:
节点 = 数据元素 + 指针(节点的地址不是连续的)
1.数据元素:存放数据
2.指针:存放该节点下一个元素的存储位置
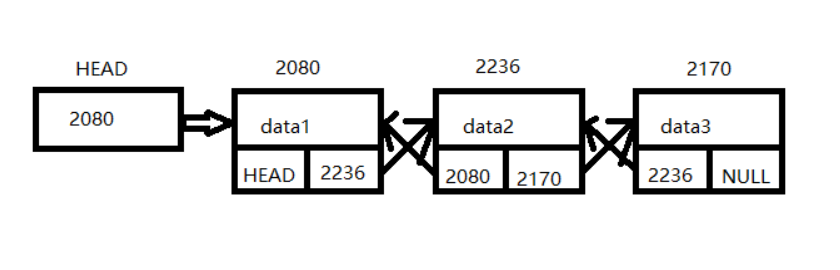
链表的图示为:
-
链表的结构体定义:
typedef struct LNode
{
ElemType data;//数据域
struct LNode* next;//指针域
}LinkList;
LiskList* L;//L为单链表头指针
- 带头结点的指针:
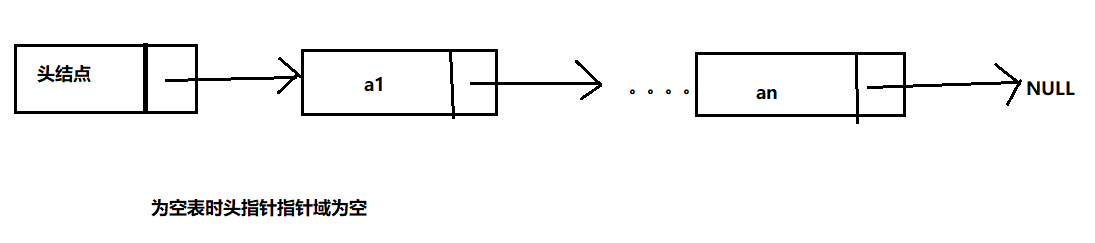
以线性表中第一个数据元素 a1 的存储地址作为线性表的地址,称作线性链表的头指针。
有时为了操作方便,在第一个结点之前虚加一个“头结点”,以指向头结点的指针为链表的头指针。
*设置头结点的好处:
⒈便于首元结点的处理:
首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其它位置一致,无须进行特殊处理;
⒉便于空表和非空表的统一处理:
无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就统一了。
即:
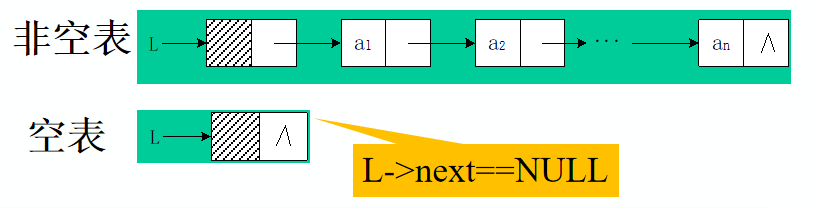
*单链表是由表头唯一确定,因此单链表可以用头指针的名字来命名,若头指针名是L,则把链表称为表L 。
- 链表的初始化:
typedef struct LNode{
ElemType data; //数据域
struct LNode *next; //指针域
}LNode,*LinkList;
Status InitList_L(LinkList &L){
L=new LNode; 此处若写为L=new LinkList 错误,L要申请LNode大小的内存空间
L->next=NULL;
return OK;
}
- 创建新链表:
1.头插法建链表(新增节点从链表头部插入):

插入新节点s时的代码为:
s->next=L->next;
L->next=s;
*头插法建链表的代码:
void CreateListF(LinkList &L,ElemType a[],int n){
int i;
L=new LNode;
L->next=NULL;
LinkList nodePtr;
for(i=0;i<n;i++){
nodePtr=new LNode;//每个节点都要动态申请空间
nodePtr->data=a[i];
nodePtr->next=L->next;
L->next= nodePtr;
}
}
2.尾插法建链表(新增节点从链表尾部插入):
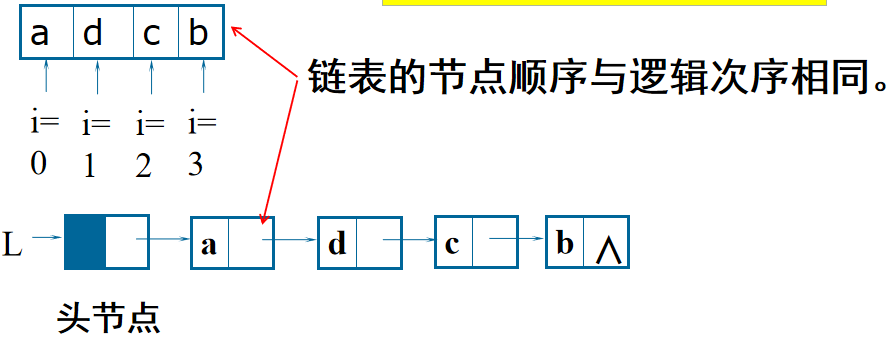
*新节点插到当前链表的表尾上,必须增加一个尾指针r,使其始终指向当前链表的尾节点。
eg:尾指针:r
r->next=s;
r=s
*添加尾指针的好处:输出时输出一整条链而不是某一节点内容,可以保护头节点,添加新节点不用每次都遍历链表寻找最后一个节点。
*尾插法代码:
void CreateListR(LinkList &L,ElemType a[],int n){
int i;
LinkList nodePtr,tailPtr;
L=new LNode;
L->next=NULL;
tailPtr=L;//尾指针
for(i=0;i<n;i++) {
nodePtr=new LNode;
nodePtr->data=a[i];
rearPtr->next=s;//尾部插入新结点
rearPtr=s; }
nodePtr->next=NULL;
}
- 链表销毁:
链表销毁与顺序表不同,不能根据头节点地址来删除整条链,因为链中每个节点的地址不一定是连续的,所以要一个个的删除每一个节点。
void DestroyList(LinkList &L){
LinkList p;
while(L){
p=L;
L=L->next;
delete p;
}
}
- 判断空表:
bool ListEmpty(LinkList *L)
{
return(L->next==NULL);
}
- 计算表的长度:
int ListLength(LinkList L)
{ int n=0;
LinkList p=L->next;
while (p)
{ n++;
p=p->next;
}
return(n); //p指向尾节点,n为节点个数
}
- 输出链表:
void DispList(LinkList L)
{
int flag = 1;
LinkList p = L->next;
while (p)
{
if (flag)
{
cout << p->data;
flag = 0;
}
else
{
cout << " " << p->data;
}
p = p->next;
}
}
- 查找数据元素:
链表中的数据元素不能像线性表一样随机存取,需要遍历链表
bool GetElem(LinkList L,int i,ElemType &e)
{ int j=0;
LinkList p=L; //p指向头节点,j置为0(即头节点的序号为0)
while (j<i && p!=NULL) //找第i个节点
{ j++;
p=p->next;
}
if (p==NULL) //不存在第i个数据节点,返回false
return false;
else //存在第i个数据节点,返回true
{ e=p->data;
return true;
}
}
- 插入数据元素:
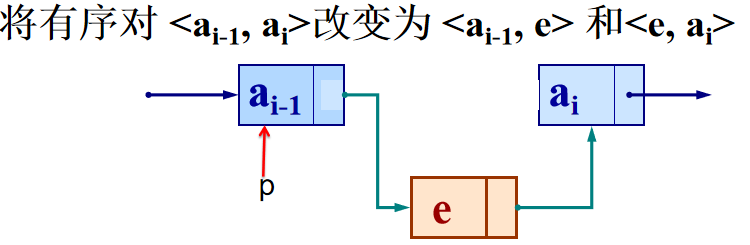
假设p指向ai-1 ,s指向e,则插入代码为:
s=new LNode;
s->data=e;
s->next=p->next;
p->next=s;
*在L中第i个元素之前插入数据元素e:
bool ListInsert(LinkList &L,int i,ElemType e){
int j=0;
LinkList p=L,s;
while(p&&j<i-1){
j++;p=p->next;
}//查找第i-1个节点
if(p==NULL) return false; //未找到第i-1个结点
s=new LNode;
s->data=e;
s->next=p->next; //插入p后面
p->next=s;
return true;
}
- 删除数据元素:
在单链表中删除第 i 个结点的基本操作为:找到线性表中第i-1个结点,修改其指向后继的指针。


删除数据元素q节点:
q = p->next;
p->next = q->next;
e = q->data;
delete q;
*删除数据元素的代码:
bool ListDelete_L(LinkList &L,int i,ElemType &e)
{
int j=0;
LinkList p=L,s,q;
while(p&&j<i-1){
p=p->next;j++;//指针每次next前都要判断是否空指针
}
if(p==NULL) return false;
q=p->next; //第i个位置
if(q==NULL) return false;
e=q->data;
p->next=q->next;//改变指针关系,删除
delete q;
return true;
}
-
链表小结:
1.遍历链表过程中务必考虑指针是否为空,尤其p->next或p->data前务必考虑p是否为空
2.链表变化,经常要重构。重构做法:
p=L->next;L->next=NULL;
3.链表做删除时候,要注意考虑链表已经空的情况
4.链表做插入时候,注意要知道插入点的前驱指针在哪里,可以通过pre->next来获取。
5.要保留指针后继,可设计nextptr=p->next,中间p变化,再p=nextptr。
6。链表设计,画图来了解指针目前状态。
* 三.有序表
-
有序表和顺序表不同,顺序表是物理逻辑相邻,即数据元素地址相邻。而有序表是指数据元素的值呈递增或递减形式排列。
-
有序表和线性表中元素之间的逻辑关系相同,其区别是运算实现的不同。
-
有序表插入数据:
根据不同的查找顺序可以分为两种插入方法:
*方法1:先找后移:
void ListInsert(SqList &L,ElemType e)
{ int i=0,j;
while (i<L->length && L->data[i]<e)
i++; //查找值为e的元素
for (j=ListLength(L);j>i;j--) //将data[i..n]后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e;
L->length++; //有序顺序表长度增1
}
*方法2:边找边移:
void InsertSq(SqList &L,int x)
{
for(int j = L->length; j > 0; j--)
{
if (x >= L->data[j-1]) //找
{
L->data[j] = x;
break;
}
L->data[j] = L->data[j-1];//移动,边移边找
L->data[j-1] = x;//保证第一个数据插入
}
L->length++;
}
根据结构体定义的不同还有方法3:
void ListInsert(LinkNode &L,ElemType e)
{ LinkNode pre=L,p;
while (pre->next!=NULL && pre->next->data<e)
pre=pre->next; //查找插入结点的前驱结点*pre
p=new LinkNode;
p->data=e; //创建存放e的数据结点*p
p->next=pre->next; //在*pre结点之后插入*p结点
pre->next=p;
}
-
有序表合并
1.有序表LA(m个元素)和LB(n个元素)合并为有序表LC:
思路》》同时扫描2个有序表LA,LB,比较LA,LB中元素,较小元素插入合并链表LC,重复这个过程直到一个有序表扫描完毕。剩下的有序表元素都插入LC。
此种算法的时间复杂度为O(m+n),空间复杂度为O(m+n)。
新建顺序表LC
i表示LA的下标,j表示LB的下标
while(i<LA.length&&j<LB.length)
{
if (LA->data[i]<LB->data[j]) 则LC中插入元素LA->data[i],i++
else 插入元素LB->data[j],j++
LC数组长度增1.
}
查看LA或LB是否为扫描完毕,没扫描完的把剩余元素复制并插入LC
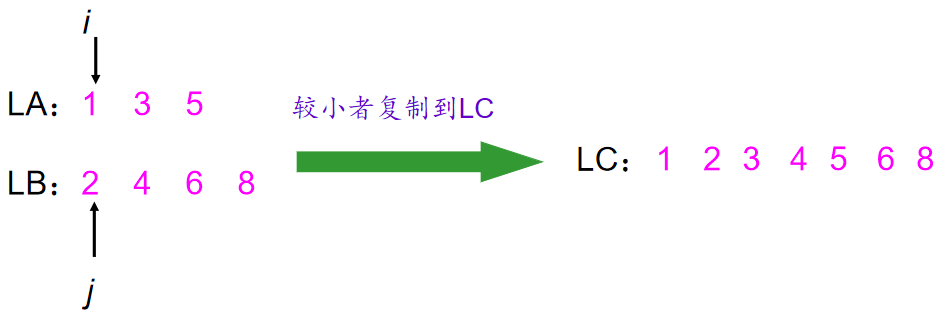
*有序表合并相关代码:
void UnionList(SqList LA,SqList LB,SqList &LC)
{ int i=0,j=0,k=0;//i、j分别为LA、LB的下标,k为LC中元素个数
LC=new SqList; //建立有序顺序表LC
while (i<LA->length && j<LB->length)
{ if (LA->data[i]<LB->data[j])
{ LC->data[k]=LA->data[i];
i++;k++;
}
else //LA->data[i]>LB->data[j]
{ LC->data[k]=LB->data[j];
j++;k++;
}
}
while (i<LA->length) //LA尚未扫描完,将其余元素插入LC中
{ LC->data[k]=LA->data[i];
i++;k++;
}
while (j<LB->length) //LB尚未扫描完,将其余元素插入LC中
{ LC->data[k]=LB->data[j];
j++;k++;
}
LC->length=k;
}
!!一定要注意有序表是否遍历完全的情况
2.有序表L1和L2合并到有序表L1中:
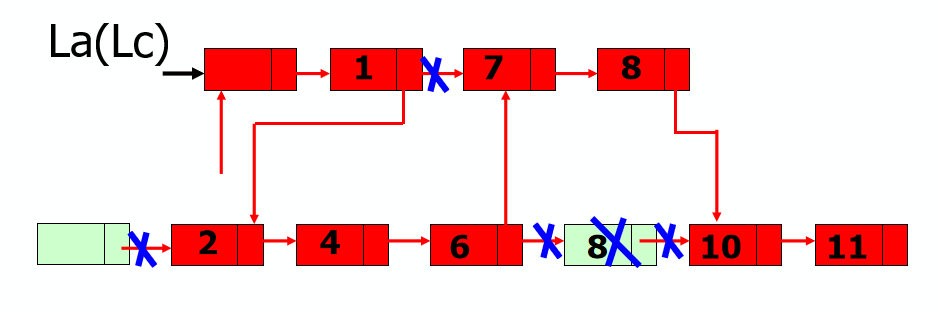
*链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。
思路:重建L1链表,p指针保存L1原始链表。
同时遍历L1,L2链表,较小元素插入链表L1。直到某个链表扫描完毕。链表有剩元素继续插入L1中。
相关代码为:
void MergeList(LinkList& L1, LinkList L2)
{
LinkList p,q,tail,temp;
p = L1->next;
q = L2->next;
L1 = new LNode;
L1->next = NULL;
tail=L1;
while (p && q)
{
if (p->data < q->data)
{
temp = p;
p = p->next;
}
else if (p->data > q->data)
{
temp = q;
q = q->next;
}
else
{
temp = p;
p = p->next;
q = q->next;
}
tail->next=temp;
tail=temp;
}
while (p)
{
tail->next = p;
tail=p;
p = p->next;
}
while (q)
{
tail->next = q;
tail=q;
q=q->next;
}
tail->next=NULL;
}
-
有序表数据删除:
先遍历链表找到要删除的元素e,查看它为第几个元素,假设e为第i个元素
then 找到第i-1个节点
将第i-1个节点的后继改为第i+1个节点
删除第i个节点
和链表的删除结构类似
* 四.双链表:
双链表每个节点有2个指针域,一个指向后继节点,一个指向前驱节点。
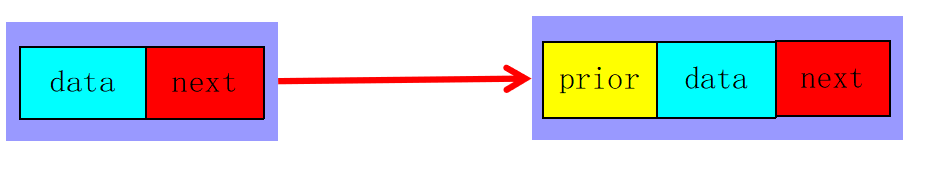
类型定义如下:
typedef struct DNode //声明双链表节点类型
{ ElemType data;
struct DNode *prior; //指向前驱节点
struct DNode *next; //指向后继节点
} DLinkList;
-
带头节点的双链表:
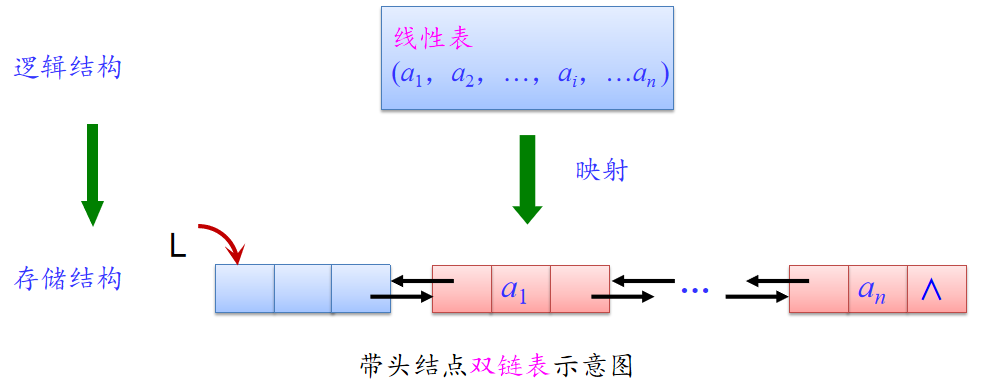
-
双链表的优点:
1.从任一结点出发可以快速找到其前驱结点和后继结点;
2.从任一结点出发可以访问其他结点。 -
双链表插入节点:
比如在p结点之后插入结点s
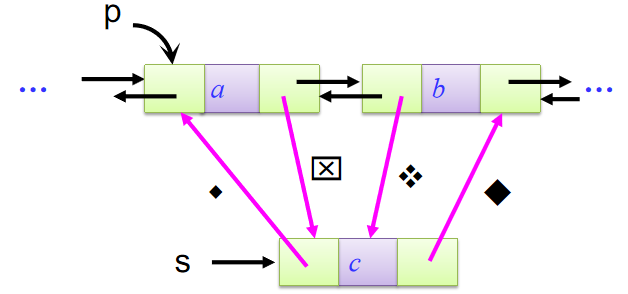
相关操作语句:
s->next = p->next
p->next->prior = s
s->prior = p
p->next = s
- 双链表删除节点:
比如删除*p结点之后的一个结点
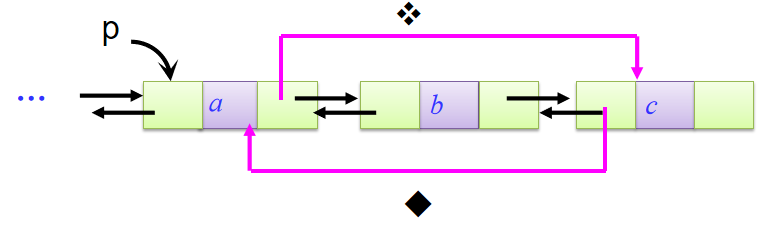
相关操作语句:
p->next->next->prior = p
p->next = p->next->next

- 头插法建立双链表:
由含有n个元素的数组a创建带头结点的双链表L。

头插法建链表代码:
void CreateListF(DLinkNode *&L,ElemType a[],int n)
{ DLinkNode *s; int i;
L=(DLinkNode *)malloc(sizeof(DLinkNode)); //创建头结点
L->prior=L->next=NULL; //前后指针域置为NULL
for (i=0;i<n;i++) //循环建立数据结点
{ s=(DLinkNode *)malloc(sizeof(DLinkNode));
s->data=a[i]; //创建数据结点*s
s->next=L->next; //将*s插入到头结点之后
if (L->next!=NULL) //若L存在数据结点,修改前驱指针
L->next->prior=s;
L->next=s;
s->prior=L;
}
}
- 尾插法建立双链表:
由含有n个元素的数组a创建带头结点的双链表L。
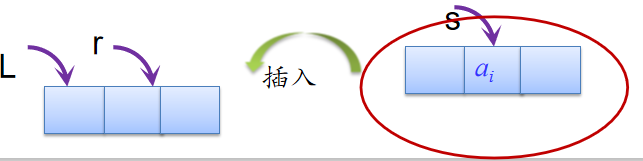
尾插法建链表代码:
void CreateListR(DLinkNode *&L,ElemType a[],int n)
{ DLinkNode *s,*r;
int i;
L=(DLinkNode *)malloc(sizeof(DLinkNode)); //创建头结点
L->prior=L->next=NULL; //前后指针域置为NULL
r=L; //r始终指向尾结点,开始时指向头结点
for (i=0;i<n;i++) //循环建立数据结点
{ s=(DLinkNode *)malloc(sizeof(DLinkNode));
s->data=a[i]; //创建数据结点*s
r->next=s;
s->prior=r; //将*s插入*r之后
r=s; //r指向尾结点
}
r->next=NULL; //尾结点next域置为NULL
}
* 五.循环链表
循环链表是另一种形式的链式存储结构形式。
将表中尾节点的指针域改为指向表头节点,整个链表形成一个环。所以从表中任一节点出发都可以找到链表中其他节点;
节点类型与非循环节点类型相同;
循环单链表:
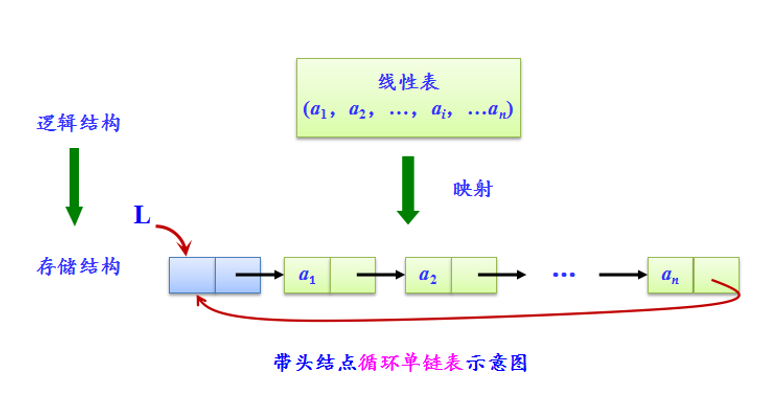
- 与单链表的区别:
1、从循环链表中的任何一个结点的位置都可以找到其他所有结点,而单链表做不到;
2.循环链表中没有明显的尾端,循环条件:
| 单链表 | 循环链表 | |
|---|---|---|
| 带头结点 | p->next!=NULL | p->next!=L |
| 不带头结点 | p!=NULL | p!=L |
-
循环单链表和循环双链表:

-
循环双链表和非循环双链表的区别:
1.链表中没有空指针域
2.p所指节点为尾结点的条件是:p->next==L;
3.用L->prior就可以找到尾结点
1.2.对线性表的认识及学习体会:
线性表是数据的逻辑结构中线性结构的一种,根据它不同的存储结构可以类化分出数组和链表两种,数据分装之后进行一些基本操作运算。线性表是具有相同特性的数据元素的一个有限序列。
-
线性表一般表示为:
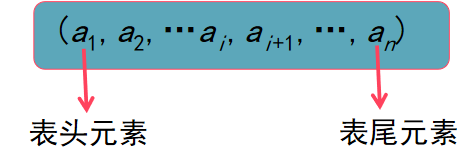
-
线性表的特征是:

学习体会:感觉链表这每个节点之间的关系设置,根据不同的算法复杂度会有很大不同,有的时候兜来转去也不明白到底什么时候该指向下一个节点;感觉很多代码就是要根据栈区和堆区的算法来套结构,把初始化和其他基本操作的套路记住了就会简单一点。
2.PTA实验作业
2.1 线性表-6-1 jmu-ds-区间删除数据
实现在顺序表中删除某个区间数据。需要实现下述的三个函数完成该功能。
void CreateList(SqList &L,int n);//建顺序表,L表示顺序表指针,n表示输入数据个数。
void DelNode(SqList &L,int min,int max);//删除区间元素。min,max表示删除的区间
void DispList(SqList L); //输出顺序表内容 ,数据间空格隔开,尾部不能有空格。
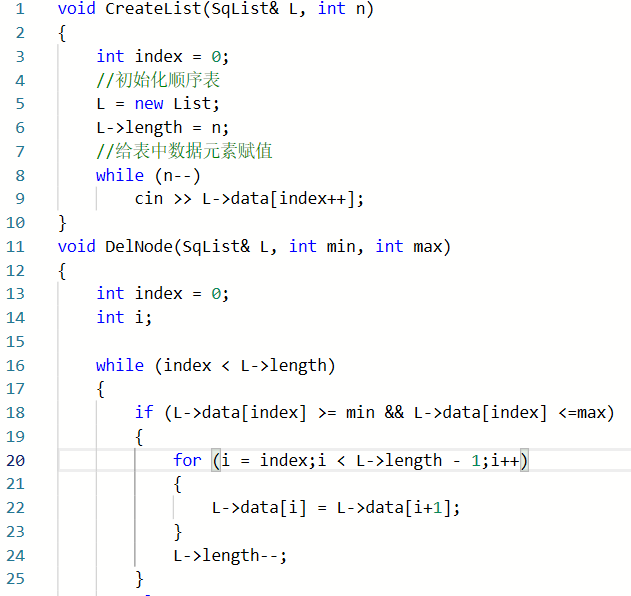
2.1.1代码截图



2.1.2本题PTA提交列表说明

Q1:运行超时:在建链表输入数据时将循环条件写成了n>0;导致无限循环
A1:将n>0修改为正确的n--
Q2:部分正确:在控制区间时,查找在区间的元素没有考虑相等的情况
A2:将查找条件改为L->data[index] >= min && L->data[index] <= max
2.2 ds-test-7-1 两个有序链表序列的交集
已知两个非降序链表序列S1与S2,设计函数构造出S1与S2的交集新链表S3。
输入分两行,分别在每行给出由若干个正整数构成的非降序序列,用−1表示序列的结尾(−1不属于这个序列)。数字用空格间隔。
在一行中输出两个输入序列的交集序列,数字间用空格分开,结尾不能有多余空格;若新链表为空,输出NULL。
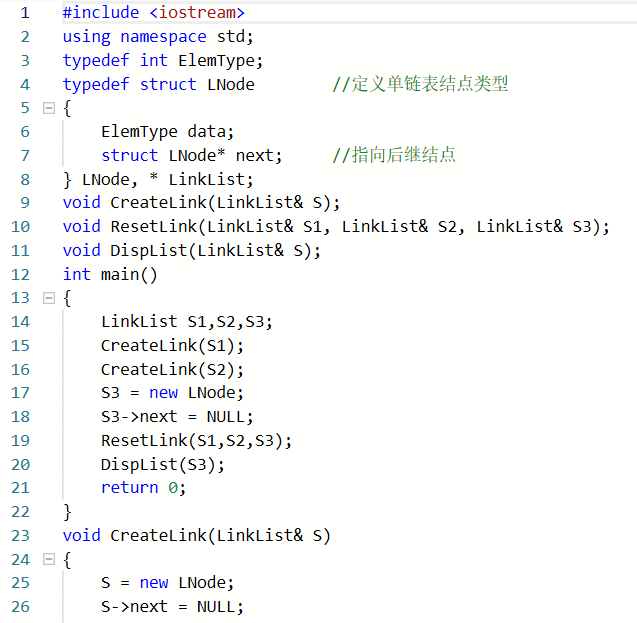
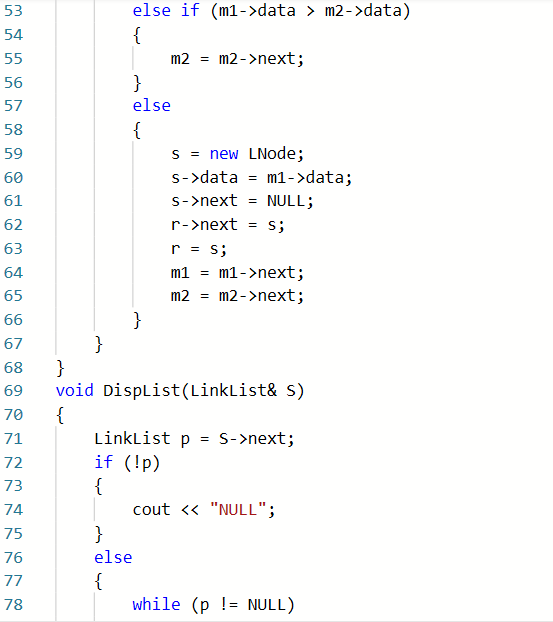
2.2.1代码截图


2.2.2本题PTA提交列表说明

!!:此次提交是在另一个题集做错之后再修改的内容,在提交时也出现了很多问题。
Q1:编译错误:在将两个列表的交集存入新链表S3时,有个别表头名称弄混造成编译错误
A1:把写错的L改成了正确的S3,因为惯性就写成L了
Q2:部分正确:输出时忘记考虑表S为空表的情况
A2:在DispLinkList()函数中添加上题干要求的if (!p) cout << "NULL";的语句来表示S为空表的情况。
2.3 线性表-6-3 jmu-ds- 顺序表删除重复元素
设计一个算法,从顺序表中删除重复的元素,并使剩余元素间的相对次序保存不变。
输入格式: 第一行输入顺序表长度。 第二行输入顺序表数据元素。中间空格隔开。
输出格式:数据之间空格隔开,最后一项尾部不带空格。
输出删除重复元素后的顺序表。
2.3.1代码截图


2.3.2本题PTA提交列表说明

Q1:部分正确:没考虑到表中元素全部重复的情况
A1:把循环条件next<L->length改为next<=L->length,如果全部重复,只留下第一个元素。
Q2:输出错误:输出空格时将flag初始成了0;造成编译错误
A2:把条件改为(flag=1)时不输出前置空格,再在循环中将后面的flag改为0,都输出前置空格;
3.阅读代码
3.1 题目及解题代码
-
题目:
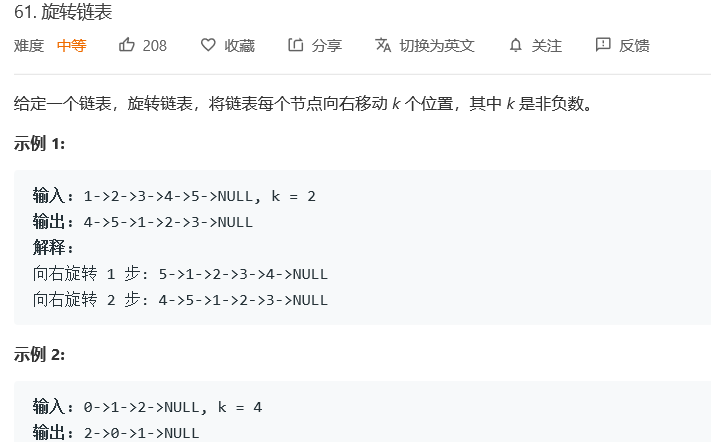
-
解题代码:
class Solution {
public ListNode rotateRight(ListNode head, int k) {
// base cases
if (head == null) return null;
if (head.next == null) return head;
// close the linked list into the ring
ListNode old_tail = head;
int n;
for(n = 1; old_tail.next != null; n++)
old_tail = old_tail.next;
old_tail.next = head;
// find new tail : (n - k % n - 1)th node
// and new head : (n - k % n)th node
ListNode new_tail = head;
for (int i = 0; i < n - k % n - 1; i++)
new_tail = new_tail.next;
ListNode new_head = new_tail.next;
// break the ring
new_tail.next = null;
return new_head;
}
}
3.1.1 该题的设计思路

- 时间复杂度:O(n)
- 空间复杂度:O(1)
3.1.2 该题的伪代码
和链表逆置的算法相似:
将数据元素连接在一起,使得可以随意定义移动次数;
找到相应的位置断开这个环,确定新的链表头和链表尾
找到旧的尾部并将其与链表头相连 old_tail.next = head,整个链表闭合成环,同时计算出链表的长度 n。
找到新的尾部,第 (n - k % n - 1) 个节点 ,新的链表头是第 (n - k % n) 个节点。
断开环 new_tail.next = None,并返回新的链表头 new_head。
public ListNode rotateRight(ListNode head, int k) {
if (为空表) return NULL
if (旋转结束) return 表头
定义头结点
int n;
for (n = 1; 没走到目的节点; n++)
当前指针后移一位
当前指针的后继成为首节点
end for
ListNode new_tail = head;
for (int i = 0; i < n - k % n - 1; i++)//旋转次数超过表中元素个数开始循环
new_tail = new_tail.next;
ListNode new_head = new_tail.next;
end for
结束循环
return new_head;
}
3.1.3 运行结果
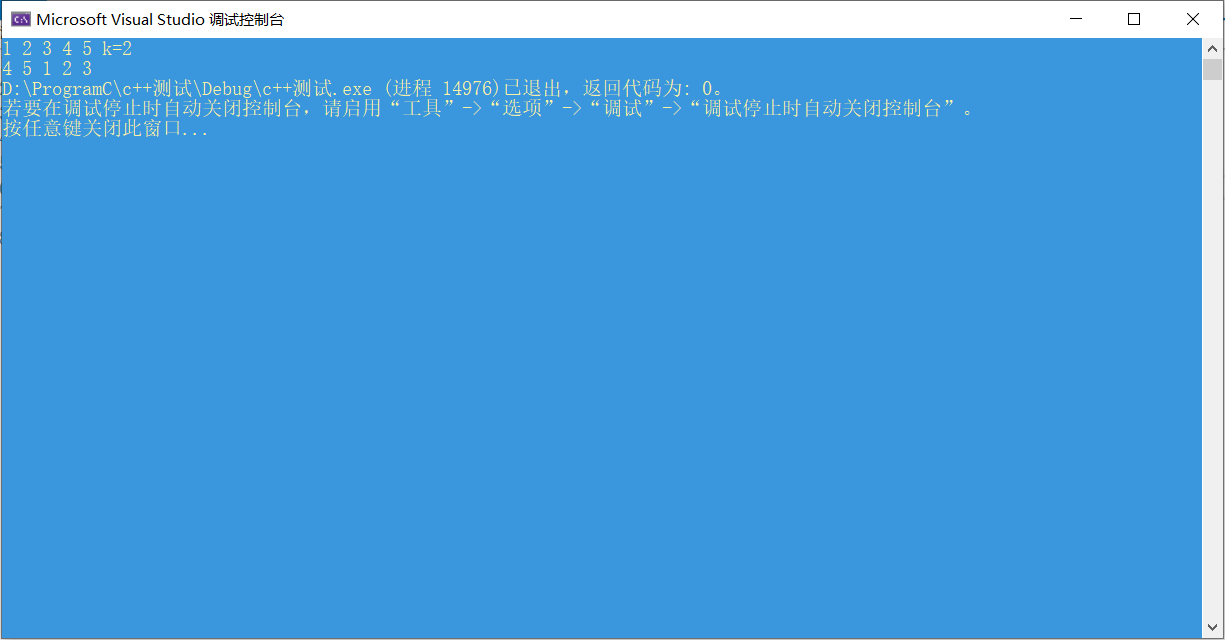
3.1.4分析该题目解题优势及难点。
优势:
此做法巧妙在把链表连成了一个环,在移动节点时不用过多的去关注链表是否遍历到尾部的问题
难点:
难点在于当前指针和新首节点以及最后一个指针之间的关系转换,即old_tail和new_tail
3.2 题目及解题代码
-
题目:
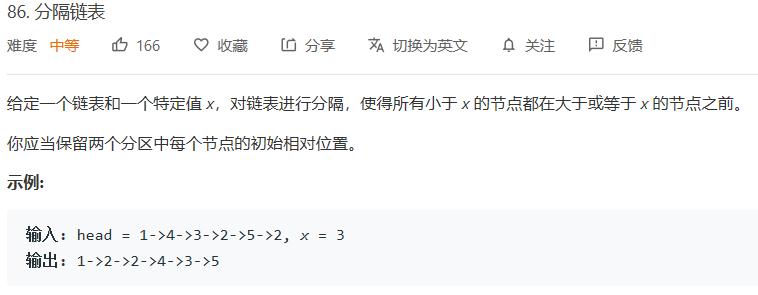
-
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode headLess, headGreater;
struct ListNode *curLess, *curGreater;
headLess.next = headGreater.next = NULL;
curLess = &headLess; curGreater = &headGreater;
while(head){
if(head->val < x){
curLess->next = head;
curLess = curLess->next;
}else{
curGreater->next = head;
curGreater = curGreater->next;
}
head = head->next;
}
curGreater->next = NULL;
curLess->next = headGreater.next;
return headLess.next;
}
}
3.2.1 该题的设计思路
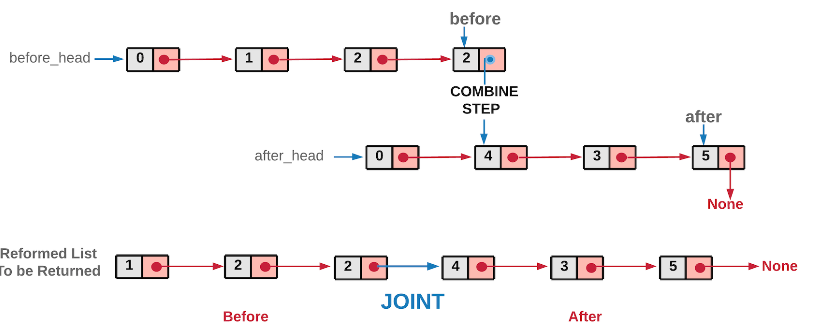
时间复杂度: O(N)
空间复杂度: O(N)
3.2.2 该题的伪代码
/**
* 维护两个链表,一个所有值小于x,一个所有值大于等于x,
* 遍历原始链表,当值小于x时。curLess指向该节点,
* 当值大于等于x时,curGreater指向该节点。
*/
struct ListNode* partition(struct ListNode* head, int x)
{
定义两个链表,一个所有值小于x,一个所有值大于等于x:headLess, headGreater;
struct ListNode* curLess, * curGreater;
链表初始化
curLess = &headLess; curGreater = &headGreater;
while (不为空表) {
if (表中元素小于x ) 在表curLess中插入此数据
end if
else (表中元素大于x) 在表curGreater中插入此节点
end else
原表当前指针后移进行遍历
}
end while
将表curGreater拼接到表curLess后
return headLess.next;
}
3.2.3 运行结果
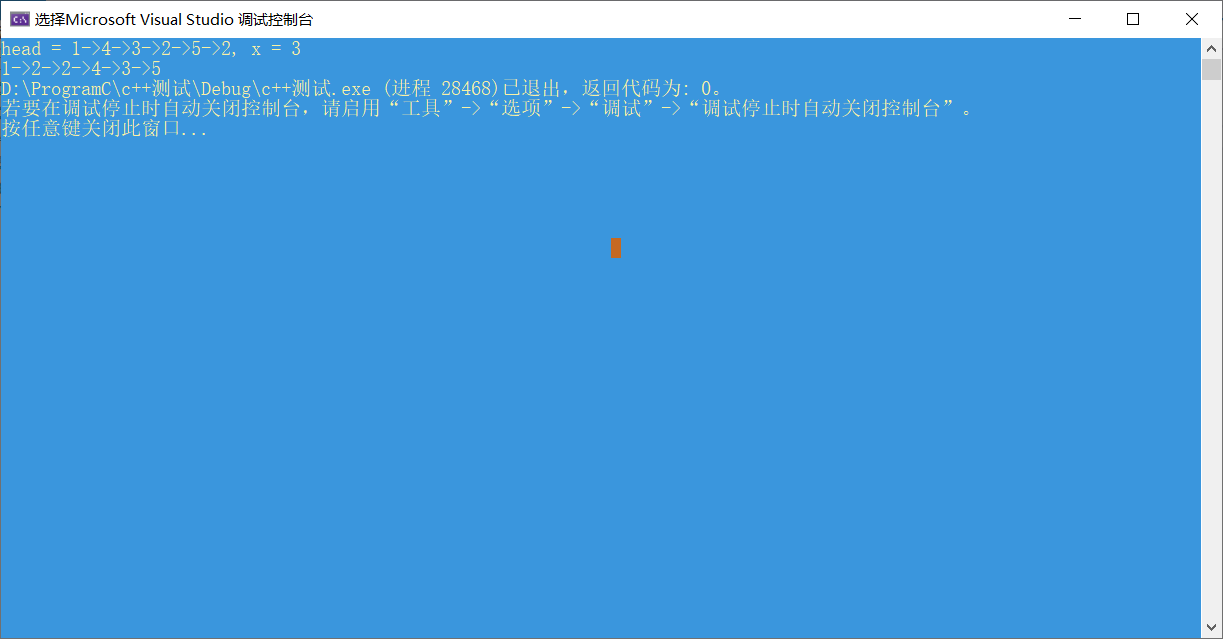
3.2.4分析该题目解题优势及难点
优势:
设置两个链表来分别存储比x大和比x小的节点;
很好的保护了各个数据元素的原始位置;
用引用来保护要返回地址的头结点
难点:
链表拆分,临时节点,不能成环