1. 进程的创建
2. 进程的终止
3. 进程的阻塞与唤醒
4. 进程的挂起与激活
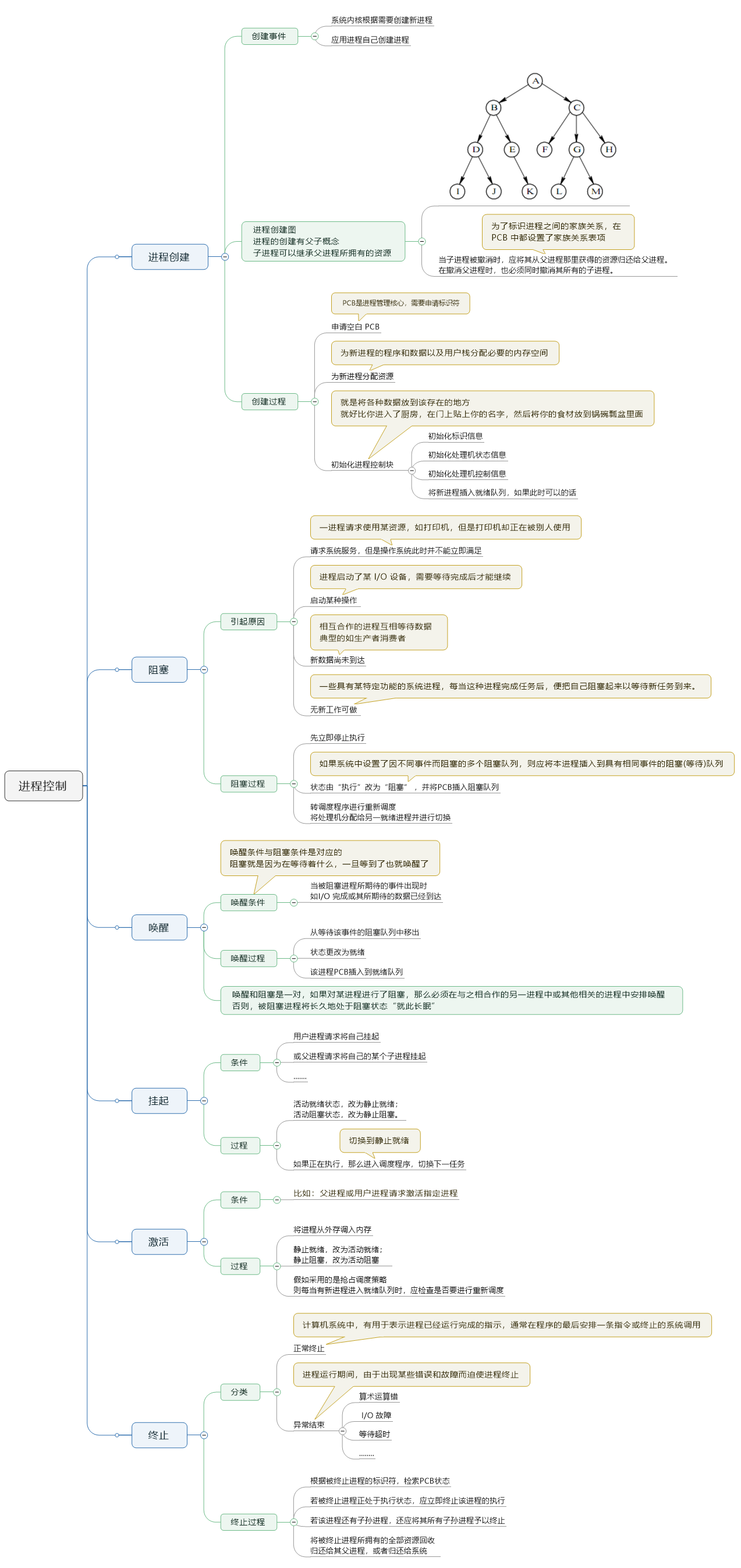
小结
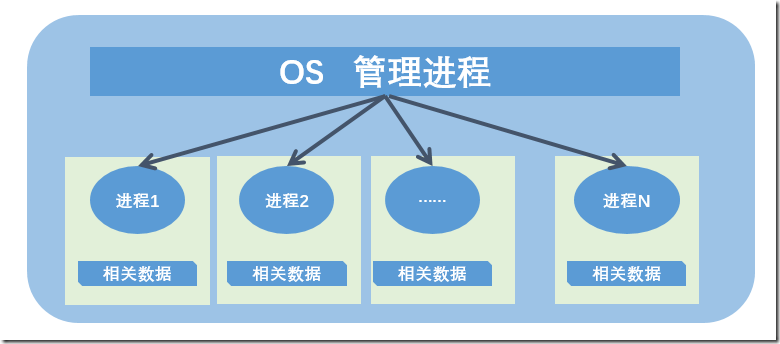
进程的控制就是操作系统对进程的主要管理工作,最重要的就是状态的切换维护。
每种状态都有不同的引发事件,每种状态又有各自不同的处理步骤和过程,整个进程控制主要就是涉及这些内容。
上面主要就是对这些状态进行简单的描述,以更好地对“进程的控制”这个概念有一个透彻的理解
上图中的思维导图是进程控制的核心
必须要理解:操作系统对于进程的控制就是对于这些状态的切换,以及切换所需要的数据维护。
二、进程的同步
(一)、进程同步概念
1.1 临界资源
一旦有对资源的共享,就必然涉及竞争限制
临界资源用来表示一种公共资源或者说是共享数据,可以被多个线程使用。
但是每一次,只能有一个线程使用它,一旦临界资源被占用,其他线程要想使用这个资源,就必须等待。
所以尽管A进程和B进程轮流获得时间片运行,但是当需要访问临界资源时,一旦有一个进程已经开始使用,另外的进程就不能进行使用,只能等待。
1.2 两种制约关系
既然资源访问有限制,到底有哪些场景是需要同步处理的?也就是何时会出现资源冲突?

看得出来,其实同步要解决的问题根本就是竞争,间接关系是赤裸裸的的竞争,共享同一个I/O就是一种竞争,尽管他们看似好像没有什么关系
直接的制约关系,源于进程间的合作,某种程度上来说也是一种竞争,只不过是有条件的竞争,他们共享缓冲区,当缓冲区满时只能是消费者可以运行,生产者需要阻塞,这可以认为缓冲区满这种情况下,消费者独占了缓冲区,生产者不能使用了,不过这种情况下还是说成合作比较容易理解
所以,要么是因为共享资源带来的竞争,要么就是相互合作带来的依赖。
1.3 临界区
有了临界资源的概念,就很容易理解临界区的概念,在程序中,所有的操作都是通过代码执行的,访问临界资源的那段代码就是临界区
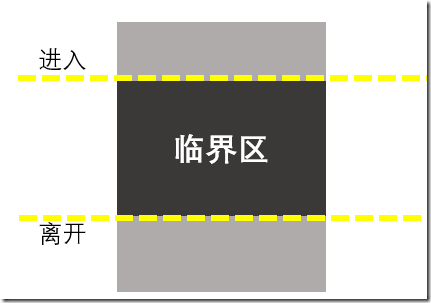
以打水为例,所以在还没到井口,就要画一个大圈,不允许第二个人进入范围,“请站在安全黄线内”这句话熟悉么?这就是临界区。
1.4 同步规则
四种同步规则: 1. 空闲让进 2. 忙则等待 3. 有限等待 4. 让权等待
空闲让进:对于临界资源没有被使用,则谁来都可以直接使用。
忙则等待:这个就是上面的对立,如果临界资源被使用,后者就需要进行等待。
有限等待:保证在有限时间内,进入临界区,而不是一直憨憨的傻等。
让权等待:如果一直进入不了临界区,就要释放处理机,让别人进入,不能一直占着没有结果。比如超市付钱,一直连不上网,无法付钱,所以你必须让后面的人来付款,不能浪费时间和资源。
有限等待和让权等待的共同特性是必须保证有条件的退出以给其他进程提供运行的机会。简单说就是有限时间内你就要走开,你得不到更要走开,你即使能得到但是时间太久也得先让一下别人
临界区的设置就是安全黄线的设置,同步规则其实就是临界区两条黄线进出规则
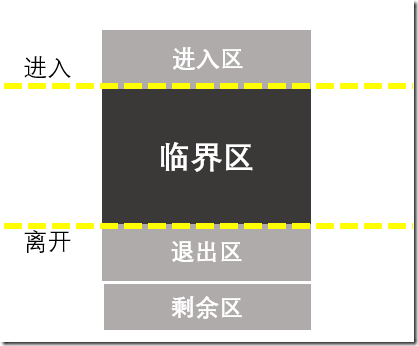
对于临界区,还可以进一步细分出来进入区和退出区以及剩余区
(二)、临界区算法


因为P1,P2两个进程的执行顺序是随机的,可能顺序执行也可能是并发的,由图可见,不同的执行顺序,COUNT的值会不同,这是不允许的。
像这种情况,及多个进程并发访问和操作同一数据且执行结果与访问发生的特定顺序有关,称为竞争条件。
所以临界区方式解决同步问题就是借助于算法,合理的控制对于临界区的进入与退出,并且保障能够做到:空闲让进、忙则等待、有限等待、让权等待
一种有名的算法为 Peterson
Peterson算法
Peterson算法适用于两个进程在临界区与剩余区间交替执行。假设两个进程分别为p0 和 p1
为了表示方便,使用pi表示其中一个进程时,pj表示另外一个,显然有i = 1-j(j = 1-i)

使用一个int类型变量turn 表示可以进入临界区的线程,如果turn == i,表示pi可以进入临界区
使用boolean 类型数组flag,总共两个进程,所以flag[2],用来表示哪个进程想要进入临界区,如果flag[i] = true;表示进程pi想要进入临界区
上图红框内为进入区,蓝框内为退出区
为了进入临界区,进程pi首先设置flag[i]为true;并且设置turn为j;
显然,根据while的条件,只有flag[j] == false 或者turn == i 时,pi可以进入临界区
也就是如果我想进入的话,当对方不想进入或者当前允许我进入时,我就可以进入临界区
显然,如果只有一个进程想要进入,那么如上所述,对方不想进入时,可以进入临界区,符合空闲让进
如果两个进程都想进入,不管经过多么激烈的竞争,当执行到while时flag[0] 和 flag[1] 都是true,也就是while内部的两个条件,条件1始终是true
但是turn只会有一个值,要么0 要么1,也就是说while的第2个条件决定了谁会被while阻塞,谁能够继续执行下去
这种情况下必然能够有一个进程会进入临界区,另外一个被while循环阻塞,所以符合空闲让进、忙则等待
当临界区内的进程执行结束后,会设置flag[] 标志位,如果此时另外的进程在等待,一旦设置后,其他进程就可以进入临界区(刚才已经说了,如果pi想进入,flag[j] == false 或者turn == i 时可以进入)也就是说当前进程结束后,下一个进程就能够进入了,所以满足有限等待。
Peterson只是一种临界区算法,还有其他的。
(三)、同步方式之信号量
1965年,荷兰学者Dijkstra 提出的信号量(Semaphores)机制是一种卓有成效的进程同步工具。
临界区算法的原理可以让多进程对于临界区资源的访问串行化;
信号量机制允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。
什么是信号量?信号量(semaphore)的数据结构为一个值和一个指针,指针指向等待该信号量的下一个进程。信号量的值与相应资源的使用情况有关。
-- 当它的值大于0时,表示当前可用资源的数量;
-- 当它的值小于0时,其绝对值表示等待使用该资源的进程个数。
一般来说,信号量S>=0时,S表示可用资源的数量。
执行一次P操作意味着请求分配一个单位资源,因此S的值减1;当S<0时,表示已经没有可用资源,请求者必须等待别的进程释放该类资源,它才能运行下去。
而执行一个V操作意味着释放一个单位资源,因此S的值加1;若S<=0,表示有某些进程正在等待该资源,因此要唤醒一个等待状态的进程,使之运行下去。
一、整型信号量
最初信号量机制被称之为整型信号量
最初由Dijkstra 把整型信号量定义为一个用于表示资源数目的整型量 S,它与一般整型量不同,除初始化外,仅能通过两个标准的原子操作(Atomic Operation) wait(S)和 signal(S)来访问。
这两个操作一直被分别称为P、V操作
wait表示资源申请:如果S小于等于0(资源不足)等待,如果满足那么将会进行S-1,也就是申请资源
signal表示资源释放:每释放一次资源,资源数目 S+1
P、V操作也称之为操作原语,就是指原子操作。(原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败)
简单来说: p操作(wait):申请一个单位资源,进程进入
v操作(signal):释放一个单位资源,进程出来
PV操作的含义:PV操作由P操作原语和V操作原语组成(原语是不可中断的过程),对信号量进行操作,具体定义如下:
P(S): ①将信号量S的值减1,即S=S-1;
②如果S<=0,则该进程继续执行;否则该进程置为等待状态,排入等待队列。
V(S): ①将信号量S的值加1,即S=S+1;
②如果S>0,则该进程继续执行;否则释放队列中第一个等待信号量的进程。
PV操作的意义:我们用信号量及PV操作来实现进程的同步和互斥。PV操作属于进程的低级通信。
使用PV操作实现进程互斥时应该注意的是:
(1)每个程序中用户实现互斥的P、V操作必须成对出现,先做P操作,进临界区,后做V操作,出临界区。若有多个分支,要认真检查其成对性。
(2)P、V操作应分别紧靠临界区的头尾部,临界区的代码应尽可能短,不能有死循环。
(3)互斥信号量的初值一般为1。
优缺点
优点:效率高。
缺点: 1. 不可被中断。由于PV操作是原子操作,因此若程序在PV操作间隙出现异常进而中断PV操作,那么会造成该程序无法恢复信号量,进而导致一直锁住某块临界资源,造成程序死锁,永远无法访问。
2. 我们说,一个好的进程调度,需要满足这四个条件:闲则让进,忙则等待,有限等待,让权等待(见名词表释义),然而整型信号量无法实现让权等待,导致处理器性能降低。
二、记录型信号量
定义:一个由两部分组成的结构体。其一为整型数值(就是整型信号量),其值为正数时用于记录当前允许进入临界区的进程数量,为负数时,记录阻塞队列中进程数量;其二为链表,用于记录当前想要进入临界区的进程。
鉴于整型信号量机制中的“忙等”情况,演化出来记录型信号量,如果进程无法进入临界区,那么进入等待释放CPU资源,并且通过一个链表记录等待的进程。
记录型信号量机制在整形信号量机制的基础上增加了进程链表指针L,这也是记录型信号量名称的由来。
记录型信号量 semaphore 的结构如下:
semaphore {
value:int value;
L:进程等待链表(集合);
}
value相当于整型信号量中的S,L就是一个链表(集合)
简言之,将整形信号量中的整型S,演化为一个结构,这个结构包括一个整型值,还有一个等待的进程链表。
相对应整型信号量中的wait(S) 和 signal(S)可以描述为:
wait(S):
var S = semaphore;
S.value=S.value-1;
if S.value<0 then block(S.L);
signal(S):
var S = semaphore;
S.value=S.value+1;
if S.value<=0 then wakeup(S.L);
上面的操作中,均定义了一个semaphore类型的变量S
- 如果执行 wait 操作,先执行资源减一,如果此时S.value<0,说明在申请资源之前(S.value-1),原来的资源就是<=0,那么该进程阻塞,加入等待队列L中
- 如果执行 signal 操作,先执行资源加一,如果此时S.value<=0,说明在释放资源之前(),原来的资源是<0的,那么将等待链表中的进程唤醒
上面逻辑的关键之处在于:
- 当申请资源时,先进行S.value-1,一旦资源出现负数,说明需要等待,S.value的绝对值就是等待进程的个数,也就是S.L的长度
- 当资源恢复时,先进行S.value+1,已经有人释放资源了然而资源个数还是小于等于0,说明原来就有人在等待,所以应该去唤醒
block 和 wakeup 也都是原语,也就是原子操作。block原语,进行自我阻塞,放弃处理机,并插入到信号量链表S.L 中;wakeup原语,将S.L链表中的等待进程唤醒。
如果 S.value的初值为 1,表示只允许一个进程访问临界资源,此时的信号量转化为互斥信号量,用于进程互斥。(效果就如同Peterson算法了)
三、AND型信号量
针对于临界区算法或者是整型信号量或者是记录型信号量是针对各进程之间只共享一个临界资源而言的。
但是有些场景下,一个进程需要先获得两个或更多的共享资源后方能执行其任务。
process A: wait(D); 于是D=0
process B: wait(E); 于是E=0
process A: wait(E); 于是E=-1 A阻塞
process B: wait(D); 于是D=-1 B阻塞
最终A,B都被阻塞,如果没有外力作用下,两者都无法从阻塞状态释放出来,这就是死锁
AND 同步机制的基本思想:
将进程在整个运行过程中需要的所有资源,一次性全部地分配给进程,待进程使用完后再一起释放。
只要尚有一个资源未能分配给进程,其它所有可能为之分配的资源也不分配给它。
也就是对若干个临界资源的分配,采取原子操作方式:要么把它所请求的资源全部分配到进程,要么一个也不分配。
这种思维就是通过对“若干个临界资源“的原子分配,逻辑上就相当于一份共享资源,要么得到,也么得不到,所以就不会出现死锁。
在 wait 操作中,增加了一个“AND”条件,所以被称为AND 同步,也被称为同时wait操作,即Swait(Simultaneous wait),相应的signal被称为Ssignal(Simultaneous signal)
AND型信号量机制借助于对于多个资源的“批量处理”的原子操作方式,将多资源的同步问题,转换为一个“同一批资源”的同步问题。
四、信号量集
记录型信号量机制中,只是对信号量加1(S+1 或者S.value+1) 或者 减1(S-1 或者S.value-1)操作,也就是只能获得或者释放一个单位的临界资源
如果想要一次申请N个呢?
如果进行N次的资源申请怎么办,一种方式是可以使用多次Wait(S)操作,但是显然效率较低;
另外有时候当资源数量低于某一下限值时,就不进行分配怎么办?需要在每次分配资源前检查资源的数量。
为了解决这两个问题,对AND信号量机制进一步扩展,形成了一般化的“信号量集”机制。
Swait操作可描述如下
其中S为信号量,d为需求值,而 t为下限值。
信号量集就是AND型信号量机制将资源限制扩展到Ti
1. Swait(S,d,d)。此时在信号量集中只有一个信号量 S,但允许它每次申请 d 个资源,当现有资源数少于d时,不予分配。
2. Swait(S,1,1)。此时的信号量集已蜕化为一般的记录型信号量(S>1时)或互斥信号量(S=1 时)。
3. Swait(S,1,0)。这是一种很特殊且很有用的信号量操作。当 S≥1 时,允许多个进程进入某特定区;当 S 变为 0 后,将阻止任何进程进入特定区。换言之,它相当于一个可控开关。
上面的格式为(s,t,d)也就是第一个为信号量,第二个为限制,第三个为需求量
所以Swait(S,1,0)可以用做开关,只要S>=1,>=1时可分配,每次分配0个,所以只要S>=1,永远都进的来,一旦S<1,也就是0往后,那么就不满足条件,就一个都进不去
五、小结
临界区机制通过算法控制进程串行进入临界区,而信号量机制则是借助于原语操作(原子性)对临界资源进行访问控制
按照各种信号量机制对应的规则以及相应的原语操作,就可以做到对资源的共享同步访问,而不会出现问题
信号量机制总共有四种
---- 整型信号量机制可以处理同一共享资源中,资源数目不止一个的情况
---- 记录型信号量对整型信号量机制的“忙等”进行了优化,通过block以及weakup原语进行阻塞和通知
---- AND型信号量机制解决了对于多个共享资源的同步
---- 信号量集是对AND的再一次优化,既能够处理多个共享资源同步的问题,还能够设置资源申请的下限,是一种更加通用的处理方式
(四)、同步方式之管程
虽然信号量机制是一种既方便、又有效的进程同步机制,但每个要访问临界资源的进程都必须自备同步操作 wait(S)和 signal(S),这就使大量的同步操作分散在各个进程中。
这不仅给系统的管理带来了麻烦,而且还会因同步操作的使用不当而导致系统死锁。
引入管程机制的目的:
1、把分散在各进程中的临界区集中起来进行管理;
2、防止进程有意或无意的违法同步操作;
3、便于用高级语言来书写程序,也便于程序正确性验证。
(一)、管程的定义
系统中的各种硬件资源和软件资源,均可用数据结构抽象地描述其资源特性。
定义如下:
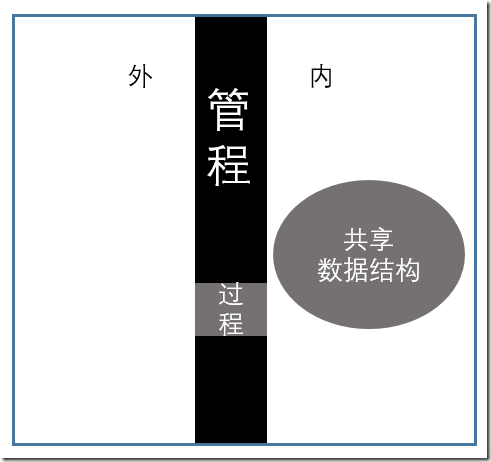
一组相关的数据结构和过程一并称为管程。
Hansan的定义:一个管程定义了一个数据结构和能为并发进程在该数据结构上所执行的一组操作,这组操作能同步进程和改变管程中的数据。
所以管程的核心部分是对共享数据抽象描述的数据结构以及可以对该数据结构实施操作的一组过程。
使用数据结构对共享资源进行抽象描述,那么必然要初始化数据,比如一个队列Queue,有属性size,这是一个抽象的数据结构,那么一个具体的队列到底有多大?你需要设置size 的值,所以对于管程还包括初始化
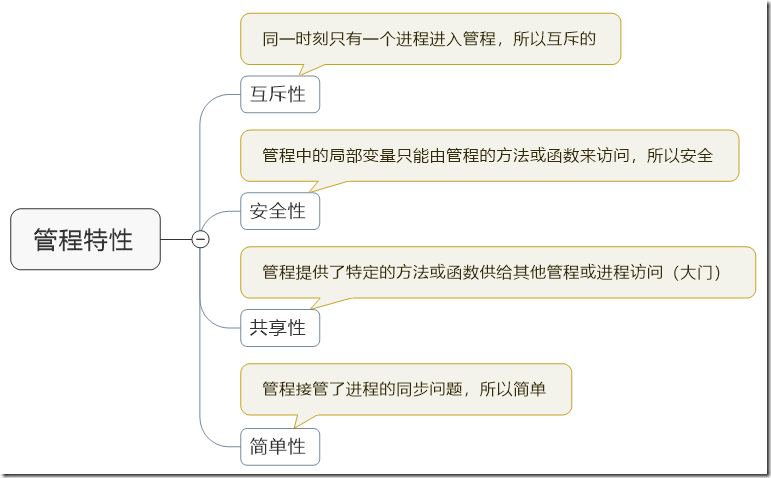
(二)、管程的特点
管程是墙,过程是门,想要访问共享资源,必须通过管程的控制(通过城墙上的门,也就是经过管程的过程)
管程的核心理念就是相当于构造了一个管理进程同步的“IOC”容器。
管程是一个语言的组成成分(非操作系统支持部分),管程的互斥访问完全由编译程序在编译时自动添加上,无需程序员关心,而且保证正确
一般的 monitor 实现模式是编程语言在语法上提供语法糖,而如何实现 monitor 机制,则属于编译器的工作
(注意:并不是所有的语言都支持管程的概念)
(三)、条件变量
条件变量(例如名称为c)是管程内的一种数据结构,且只有在管程中才能被访问,它对管程内的所有过程是全局的,只能通过两个原语操作来控制它。
c.wait( )-调用进程阻塞并移入与条件变量c相关的队列中,并释放管程,直到另一个进程在该条件变量c上执行signal( )唤醒等待进程并将其移出条件变量c队列。
c.signal( )-如果存在其他进程由于对条件变量c执行wait( )而被阻塞,便释放之;如果没有进程在等待,那么,信号被丢弃。
条件变量与P、V操作中信号量的区别:
条件变量是一种信号量,但不是P、V操作中纯粹的计数信号量,没有与条件变量关联的值,不能像信号量那样积累供以后使用,仅仅起到维护等待进程队列的作用。因此在使用条件变量x时,通常需要定义一个与之配套使用的整型变量x-count用于记录条件变量x所维护等待队列中的进程数。
管程可以保证互斥,同一时刻仅有一个进程进入管程,所以他必然需要同步工具,如两个同步操作原语 wait和 signal,他还需要互斥量用以控制管程进入的同步
当某进程通过管程请求获得临界资源而未能满足时,管程便调用 wait 原语使该进程等待,并将其排在等待队列上
仅当另一进程访问完成并释放该资源之后,管程调用signal原语,唤醒等待队列中的队首进程
但是,仅仅这个互斥量是不够的
比如,如果需要处理之前提到过的“执行顺序控制”,如何控制前驱关系?
当一个进程调用了管程,在管程中时被阻塞或挂起,直到阻塞或挂起的原因解除,而在此期间,如果该进程不释放管程,则其它进程无法进入管程,被迫长时间地等待。
所以还需要其他的信号量用于针对其他条件进行同步,这些就是条件变量。条件变量就是当调用管程过程的进程无法运行时,用于阻塞进程的一种信号量。
上面可以用简单的例子解释。A在用厨房,突然临时有事,要停止做饭 离开厨房。但是他把厨房锁住,钥匙拿走,不允许排队的人做饭,必须等待他回来做完。那他什么时候回来?这个太占用资源了,所以需要找个方法解决。如下。
管程中对每个条件变量都须予以说明,其形式为:Var x,y:condition。
对条件变量的操作仅仅是wait和signal,条件变量也是一种抽象数据类型,每个条件变量保存了一个链表,用于记录因该条件变量而阻塞的所有进程,同时提供的两个操作即可表示为 x.wait和x.signal,其含义为:
① x.wait:正在调用管程的进程因 x 条件需要被阻塞或挂起,则调用 x.wait 将自己插入到x条件的等待队列上,并释放管程,直到x条件变化。此时其它进程可以使用该管程。
② x.signal:正在调用管程的进程发现 x 条件发生了变化,则调用 x.signal,重新启动一个因 x 条件而阻塞或挂起的进程。如果存在多个这样的进程,则选择其中的一个,如果没有,则继续执行原进程,而不产生任何结果。
这与信号量机制中的 signal操作不同,因为后者总是要执行s:=s+1操作,因而总会改变信号量的状态。
接着上面例子扩展理解。
1. 加入A在厨房(管程)做饭,其他人在外面等着(阻塞队列),此时A来一个电话,临时有事(x的条件),需要停止做饭(阻塞),离开厨房(管程),这个时候可以让排队的人进来做(唤醒)。
此时A就是阻塞状态。这个是x.wait。
2. 过会A把事情处理完了回来,就让此时正在做饭的兄弟暂停(阻塞),让A开始继续做放(唤醒)。这个是x.signal
个人理解,如有不符,敬请谅解!
如果有进程Q因x条件处于阻塞状态, 当正在调用管程的进程P执行了x.signal操作后,进程Q 被重新启动,此时两个进程 P和Q,如何确定哪个执行,哪个等待,可采用下述两种方式之一进行处理:
(1) P等待,直至Q 离开管程或等待另一条件。
(2) Q等待,直至P离开管程或等待另一条件。
采用哪种处理方式,当然是各执一词。
Hoare 采用了第一种处理方式
而 Hansan 选择了两者的折衷,他规定管程中的过程所执行的signal 操作是过程体的最后一个操作,于是,进程P执行signal操作后立即退出管程,因而进程Q马上被恢复执行。
总结
进程控制是操作系统的一种硬性管理,是必须要有的,如果没有进程控制,就没办法合理安排运行进程, 根本无法完成状态的切换维护等。
进程的同步是一种软逻辑上的,如果不做,并不会导致系统出问题或者进程无法运行,但是如果不进行同步,结果却很可能是错误的,所以也是必须做的
类比装修的话,进程控制就是硬装,不装没法住,总归要水电搞搞好,进程同步就是家具家电和软装,硬装后住进去不会出现“生存问题”(至少有水喝有电用),但是你要是连个热水壶都没有是打算要喝凉水么。
进程同步的概念多很复杂抽象,因为毕竟是概念表述,没有涉及到具体的实现细节。
进程同步的核心是对于临界资源的访问控制,也就是对于临界区的访问。
不管是临界区算法还是信号量机制还是管程机制,终归也都是控制进入临界区的不同的实现思路。
每种不同的算法、机制都各自有各自的特色,场景。
信号量机制将临界资源的访问的互斥,演化为可以多个进程访问资源(整型信号量),记录型信号量对整型信号量机制进行优化,处理了忙等的问题
然后继续演化出AND型,可以对不同的资源进行同步,而不仅仅是同一种资源
最后发展为信号量集的形式,可以对不同的资源、不同的个数、不同的限制进行处理,变得更为通用。
管程更多的是一种设计思维,管程就是管理进程的程序,进程对于资源的同步操作全都依赖管程这一“大管家”,管程是编程语言级别的,不需要程序员进行过多的处理,一般会提供语法糖
需要注意并不是所有的语言都有管程的概念(Java是有的),管程让你从同步的细节中解放出来,可以在很多场景下简化同步的实现。
管程的概念是“线程同步”的“IOC”,大大简化了同步的代价。
不管临界区算法还是信号量机制还是借助于管程,他们都是一种同步工具,可以认为他们就是一组“方法”,“方法”的逻辑就是本文前面介绍的原理
在需要进程同步问题的解决思路中,可以直接使用“封装好的方法”
以上,尽管都是在说操作系统关于进程的同步的处理,其实,在同步问题上进程和线程的设计理念是相通的
因为这本质上都是在说并发----多道程序运行的操作系统,通常使用轮转时间片的方式并发的运行多个进程
感谢 :https://www.cnblogs.com/noteless/p/10350253.html#16