from: https://zhuanlan.zhihu.com/p/103205929
这篇博客最好的地方是题图:
正文:
RoBERTa
论文原文:Roberta
项目主页中文, 作者表示,在本项目中,没有实现 dynamic mask。 英文项目主页
从模型上来说,RoBERTa基本没有什么太大创新,主要是在BERT基础上做了几点调整: 1)训练时间更长,batch size更大,训练数据更多; 2)移除了next predict loss; 3)训练序列更长; 4)动态调整Masking机制。 5) Byte level BPE RoBERTa is trained with dynamic masking (Section 4.1), FULL - SENTENCES without NSP loss (Section 4.2), large mini-batches (Section 4.3) and a larger byte-level BPE (Section 4.4).
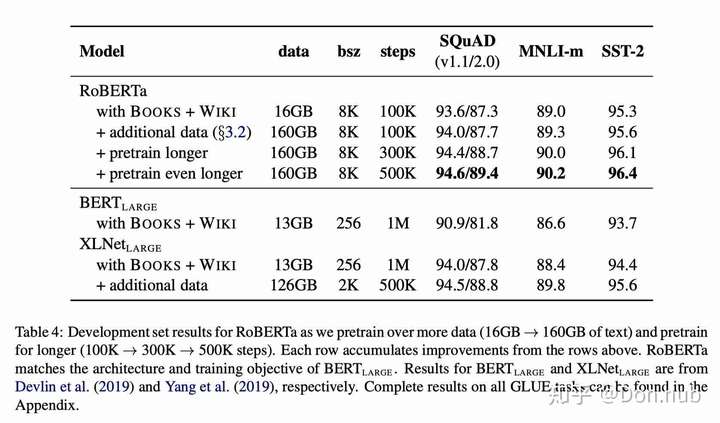
更多训练数据/更大的batch size/训练更长时间
- 原本bert:BOOKCORPUS (Zhu et al., 2015) plus English W IKIPEDIA.(16G original)
- add CC-NEWS(76G)
- add OPEN WEB TEXT(38G)
- add STORIES(31G)
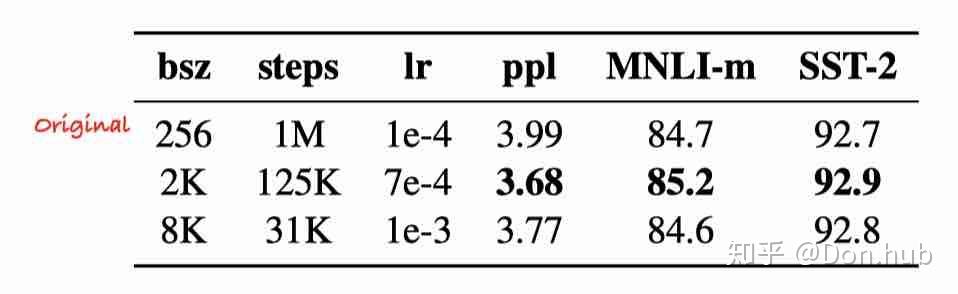
- 更大的batch size
- 更长的训练时间
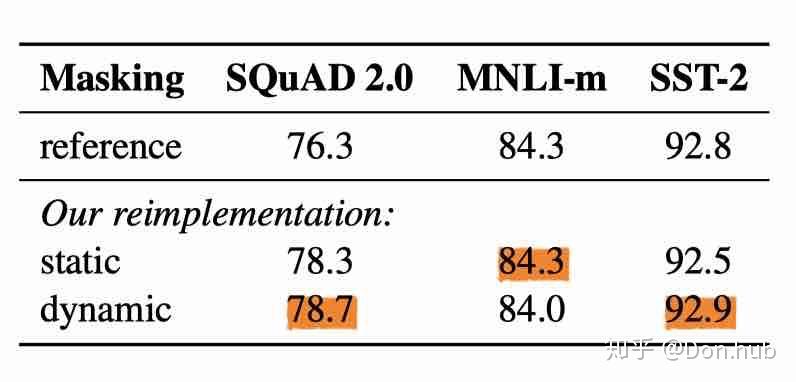
Dynamic Masking
- static masking: 原本的BERT采用的是static mask的方式,就是在
create pretraining data中,先对数据进行提前的mask,为了充分利用数据,定义了dupe_factor,这样可以将训练数据复制dupe_factor份,然后同一条数据可以有不同的mask。注意这些数据不是全部都喂给同一个epoch,是不同的epoch,例如dupe_factor=10,epoch=40, 则每种mask的方式在训练中会被使用4次。 The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training. - dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask。
No NSP and Input Format
NSP: 0.5:从同一篇文章中连续的两个segment。0.5:不同的文章中的segment
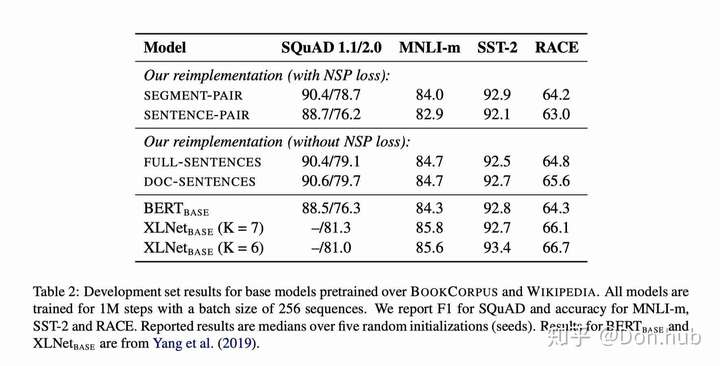
- Segment+NSP:bert style
- Sentence pair+NSP:使用两个连续的句子+NSP。用更大的batch size
- Full-sentences:如果输入的最大长度为512,那么就是尽量选择512长度的连续句子。如果跨document了,就在中间加上一个特殊分隔符。无NSP。实验使用了这个,因为能够固定batch size的大小。
- Doc-sentences:和full-sentences一样,但是不跨document。无NSP。最优。
Text Encoding
BERT原型使用的是 character-level BPE vocabulary of size 30K, RoBERTa使用了GPT2的 byte BPE 实现,使用的是byte而不是unicode characters作为subword的单位。
learn a subword vocabulary of a modest size (50K units) that can still encode any input text without introducing any “unknown” tokens.
zh 实现没有dynamic masking