第一部分 课本学习
进程的切换和系统的一般执行过程
-
进程调度的时机
Linux内核系统通过schedule函数实现进程调度,进程调度的时机就是内核调用schedule函数的时机。当内核即将返回用户空间时,内核会检查need_resched标志是否设置。如果设置,则调用schedule函数,此时是从中断(异常/系统调用)处理程序返回用户空间的时间点作为一个固定的调度时机点。
简单总结进程调度时机如下:
用户进程通过特定的系统调用主动让出CPU
中断处理程序在内核返回用户态时进行调度。
内核线程主动调用schedule函数让出CPU。
中断处理程序主动调用schedule函数让出CPU,涵盖以上第一种和第二种情况。 -
调度策略与算法
调度策略:Linux系统中常用的几种调度策略为SCHED_NORMAL、SCHED_FIFO、SCHED_RR。其中SCHED_NORMAL是用于普通进程的调度类,而SCHED_FIFO和SCHED_RR是用于实时进程的调度类,优先级高于SCHED_NORMAL。内核中根据进程的优先级来区分普通进程和实时进程,Linux内核进程优先级为0139,数值越高,优先级越低,0为最高有限级。实时进程的优先级取值为099;而普通进程只具有nice值,nice值映射到优先级为100~139。子进程会继承父进程的优先级。
CFS调度算法:CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使用CPU的顺序由进程已使用的CPU虚拟时间(vruntime)决定,已使用的虚拟时间越少,进程排序就越靠前,进程再次被调度执行的概率就越高。每个进程每次占用CPU后能够执行的时间(ideal_runtime)由进程的权重决定,并且保证在某个时间周期(__sched_period)内运行队列里的所有进程都能够至少被调度执行一次。 -
进程上下文切换
在实际代码中,每个进程切换基本由两个步骤组成。
切换页全局目录(CR3)以安装一个新的地址空间,这样不同进程的虚拟地址如0x8048400就会经过不同的页表转换为不同的物理地址。
切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器状态 -
Linux系统的运行过程
最基本和一般场景是:正在运行的用户态进程X切换到用户态进程Y的过程。具体过程如下。
1、 正在运行的用户态进程X。
2、发生中断(包括异常、系统调用等)。
3、SAVE_ALL,保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态。
4、中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换。
5、标号1,之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)。
6、restore_all,恢复现场,与3中保存现场相对应。
7、iret - pop cs:eip/ss:esp/eflags,从Y进程的内核堆栈中弹出2中硬件完成的压栈内容。此时完成了中断上下文的切换,即从进程Y的内核态返回到进程Y的用户态。
8、继续运行用户态进程Y。 -
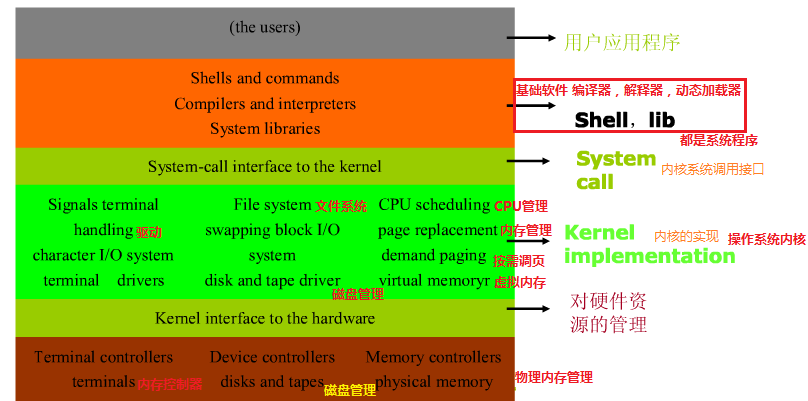
Linux系统架构与执行过程概览
Linux系统的整体架构如图所示:
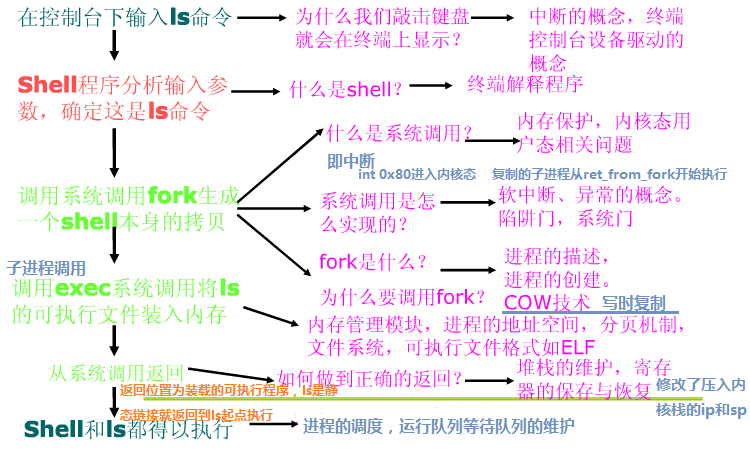
Ls命令执行过程示意图如下:
第二部分 代码分析
- context_switch代码
static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) { //如果被切换进来的进程的mm为空切换,内核线程mm为空
next->active_mm = oldmm; //将共享切换出去的进程的active_mm
atomic_inc(&oldmm->mm_count); //有一个进程共享,所有引用计数加一
enter_lazy_tlb(oldmm, next); //普通mm不为空,则调用switch_mm切换地址空间
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
context_tracking_task_switch(prev, next);
// 这里切换寄存器状态和栈
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}
- switch_to代码
#define switch_to(prev, next, last) //prev指向当前进程,next指向被调度的进程
do {
unsigned long ebx, ecx, edx, esi, edi;
asm volatile("pushfl
" //把prev进程的flag保存到prev进程的内核堆栈中
"pushl %%ebp
" //把prev进程的基址ebp保存到prev进程的内核堆栈中
"movl %%esp,%[prev_sp]
"//保存ESP
"movl %[next_sp],%%esp
"//更新ESP,将下一栈顶保存到ESP中
"movl $1f,%[prev_ip]
"//保存当前进程EIP*
"pushl %[next_ip]
"//把next进程起点压入next进程的内核堆栈栈顶
__switch_canary
"jmp __switch_to
"//prev进程中设置next进程堆栈
//jmp不同于call,是通过寄存器传递参数,而不是通过堆栈传递参数,所以ret时弹出的是之前压入栈顶的next进程起点
//wancheng EIP的切换
"1: "
"popl %%ebp
"
"popfl
"
/* output parameters */
: [prev_sp] "=m"(prev->thread.sp), //保存prev进程的esp
[prev_ip] "=m"(prev->thread.ip), //保存prev进程的eip
"=a" (last),
/* clobbered output registers: */
"=b" (ebx), "=c"(ecx), "=d" (edx),
"=S" (esi), "=D"(edi)
__switch_canary_oparam
/* input parameters: */
: [next_sp] "m" (next->thread.sp), //next进程内核堆栈栈顶地址,即esp
[next_ip] "m" (next->thread.ip), //next进程的原eip
/* regparm parameters for __switch_to():*/
//jmp通过eax寄存器和edx寄存器传递参数
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: /* 重新加载段寄存器
"memory");
} while (0)
第三部分 实验楼实验
在实验楼中配置运行MenuOS系统:
配置gdb断点:
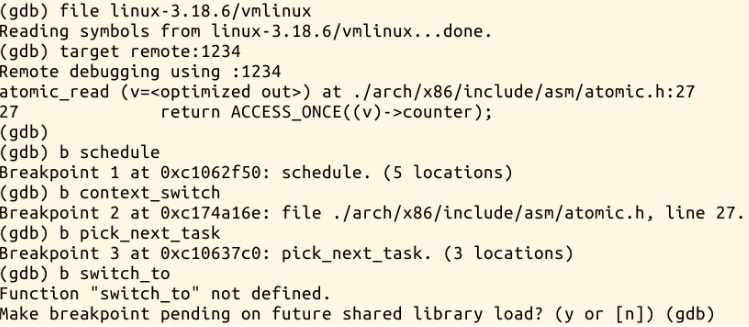
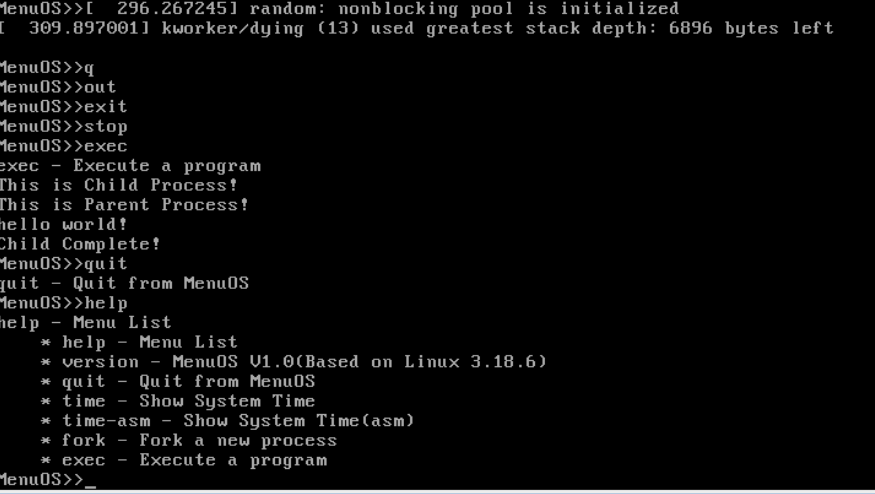
开始执行,分别停在各断点处:


Schedule函数的作用非常重要,是进程调度的主体函数。其中pick_next_task函数是schedule函数中重要的函数,负责根据调度策略和调度算法选择下一个进程,context_switch函数是schedule函数中实现进程切换的函数,switch_to是context_switch函数中进行进程关键上下文切换的函数。由于switch_to内部是内嵌汇编代码,无法跟踪调试。