伪 分布模式下启动spark报错
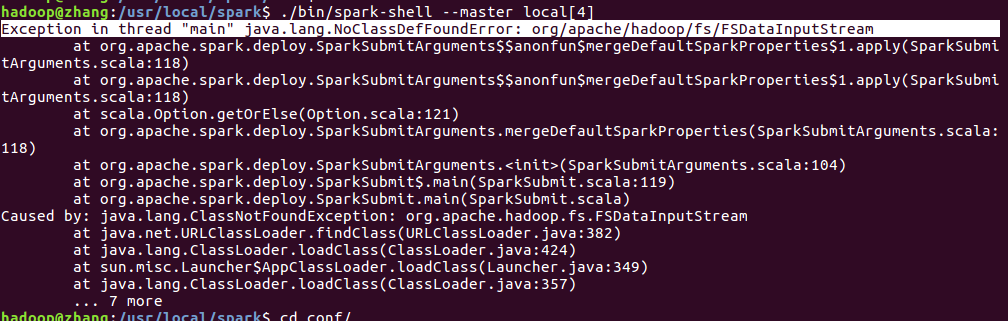
从spark1.4以后,所有spark的编译都是没有将hadoop的classpath编译进去的,所以必须在spark-env.sh中指定hadoop中的所有jar包。
具体设置如下:
在spark/conf文件下spark-evn.sh中添加
这里实际上就是执行一条hadoop的命令,将hadoop的classpath引一下
export export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)