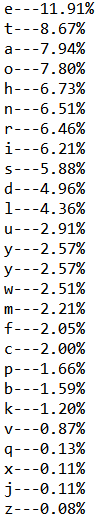要求
第0步:
输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
字母频率 = 这个字母出现的次数 / (所有A-Z,a-z字母出现的总数)
如果两个字母出现的频率一样,那么就按照字典序排列。 如果 S 和 T 出现频率都是 10.21%, 那么, S 要排在T 的前面。
第1步:
输出单个文件中的前 N 个最常出现的英语单词。
作用:一个用于统计文本文件中的英语单词出现频率。
单词:以英文字母开头,由英文字母和字母数字符号组成的字符串视为一个单词。单词以分隔符分割且不区分大小写。在输出时,所有单词都用小写字符表示。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号 例:good123是一个单词,123good不是一个单词。good,Good和GOOD是同一个单词。
设计思想:
首先是统计字母,我们应该先把要统计的文件读取,遍历统计字母出现的次数,将大写字母转换为小写字母;统计单词也需要将大写字母转换为小写,只要遇到空格则记为一个单词,遍历一遍统计单词个数。
代码:
import java.io.FileNotFoundException; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.HashMap; import java.util.Scanner; import java.awt.List; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.io.FileOutputStream; import java.io.PrintStream; import java.text.NumberFormat; public class tongji { public static void main(String[] args) { File src =new File("c:/Harry Potter and the Sorcerer's Stone.txt"); InputStream is=null; try { is=new FileInputStream(src); int temp; int[] p=new int[56]; while((temp=is.read())!=-1)//当数据为不存在时,返回-1 { char t=(char)temp; if(t=='a'||t=='A') { p[0]++; } if(t=='b'||t=='B') { p[1]++; } if(t=='c'||t=='C') { p[2]++; } if(t=='d'||t=='D') { p[3]++; } if(t=='e'||t=='E') { p[4]++; } if(t=='f'||t=='F') { p[5]++; } if(t=='g'||t=='G') { p[6]++; } if(t=='h'||t=='H') { p[7]++; } if(t=='i'||t=='I') { p[8]++; } if(t=='j'||t=='J') { p[9]++; } if(t=='k'||t=='K') { p[10]++; } if(t=='l'||t=='L') { p[11]++; } if(t=='m'||t=='M') { p[12]++; } if(t=='n'||t=='N') { p[13]++; } if(t=='o'||t=='O') { p[14]++; } if(t=='P'||t=='p') { p[15]++; } if(t=='q'||t=='Q') { p[16]++; } if(t=='r'||t=='R') { p[17]++; } if(t=='S'||t=='s') { p[18]++; } if(t=='t'||t=='T') { p[19]++; } if(t=='u'||t=='U') { p[20]++; } if(t=='v'||t=='V') { p[21]++; } if(t=='w'||t=='W') { p[22]++; } if(t=='X'||t=='x') { p[23]++; } if(t=='Y'||t=='y') { p[24]++; } if(t=='z'||t=='Z') { p[25]++; } } int[] y=new int[26]; for(int r=0;r<26;r++) { y[r]=p[r]; } int templ=0; for(int i=0;i<26;i++) { templ+=p[i]; } float qq=(float)templ; int te; //冒泡排序 for(int g=0;g<24;g++) { for(int f=0;f<24-g;f++) { if(p[f]<p[f+1]) { te=p[f]; p[f]=p[f+1]; p[f+1]=te; } }
} for(int j=0;j<26;j++) { NumberFormat nt = NumberFormat.getPercentInstance();//获取百分数实例 nt.setMinimumFractionDigits(2);//保留百分数后两位 char w=' '; for(int b=0;b<26;b++) { if(p[j]==y[b]) { switch (b) { case 0: w='a'; break; case 1: w='b'; break; case 2: w='c'; break; case 3: w='d'; break; case 4: w='e'; break; case 5: w='f'; break; case 6: w='g'; break; case 7: w='h'; break; case 8: w='i'; break; case 9: w='j'; break; case 10: w='k'; break; case 11: w='l'; break; case 12: w='m'; break; case 13: w='n'; break; case 14: w='o'; break; case 15: w='p'; break; case 16: w='q'; break; case 17: w='r'; break; case 18: w='s'; break; case 19: w='t'; break; case 20: w='u'; break; case 21: w='v'; break; case 22: w='w'; break; case 23: w='x'; break; case 24: w='y'; break; case 25: w='z'; break; default: break; } } } float q=(float)p[j]; System.out.println(w+"---"+nt.format(q/qq)); //System.out.println(p[j]/templ); } //System.out.println(templ); //System.out.println(p[0]); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { try { is.close(); } catch (IOException e) { e.printStackTrace(); }
}
}
}
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.PrintWriter; import java.nio.file.NoSuchFileException; import java.util.*; import java.util.StringTokenizer; import java.util.regex.Matcher; import java.util.regex.Pattern; public class danci{ public static void main(String[] args) throws IOException{ ArrayList<String> AL = new ArrayList<String>(); try { FileInputStream IS = new FileInputStream("c:/Harry Potter and the Sorcerer's Stone.txt"); Scanner S = new Scanner(IS); while(S.hasNextLine()){ StringTokenizer st = new StringTokenizer(StringFunc(S.nextLine())); while(st.hasMoreTokens()) { AL.add(st.nextToken()); } } IS.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } HashFunc(AL); } //handle the string public static String StringFunc(String Str) { Str = Str.toLowerCase(); Str = Pattern.compile("[^A-Za-z]+").matcher(Str).replaceAll(" "); return Str; } //put elements in a hashtable and count how many times they appear public static void HashFunc(ArrayList<String> AL) { HashMap<String, Integer> Hmap = new LinkedHashMap<>(); Collections.sort(AL); for (String temp : AL) { Integer count = Hmap.get(temp); Hmap.put(temp, (count == null) ? 1 : count + 1); } Iterator iter = Hmap.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); Object key = entry.getKey(); Object val = entry.getValue(); System.out.println(val + " " + key); } } }
程序截图: