算法说明
协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投、拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予资讯相当程度的回应(如评分)并记录下来以达到过滤的目的,进而帮助别人筛选资讯,回应不一定局限于特别感兴趣的,特别不感兴趣资讯的纪录也相当重要。
协同过滤常被应用于推荐系统。这些技术旨在补充用户—商品关联矩阵中所缺失的部分。
MLlib 当前支持基于模型的协同过滤,其中用户和商品通过一小组隐性因子进行表达,并且这些因子也用于预测缺失的元素。MLLib 使用交替最小二乘法(ALS) 来学习这些隐性因子。
用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分、用户查看物品的记录、用户的购买记录等。其实这些用户的偏好信息可以分为两类:
- 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式地提供反馈信息,例如用户对物品的评分或者对物品的评论。
- 隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式地反映了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息,等等。
显式的用户反馈能准确地反映用户对物品的真实喜好,但需要用户付出额外的代价;而隐式的用户行为,通过一些分析和处理,也能反映用户的喜好,只是数据不是很精确,有些行为的分析存在较大的噪音。但只要选择正确的行为特征,隐式的用户反馈也能得到很好的效果,只是行为特征的选择可能在不同的应用中有很大的不同,例如在电子商务的网站上,购买行为其实就是一个能很好表现用户喜好的隐式反馈。
推荐引擎根据不同的推荐机制可能用到数据源中的一部分,然后根据这些数据,分析出一定的规则或者直接对用户对其他物品的喜好进行预测计算。这样推荐引擎可以在用户进入时给他推荐他可能感兴趣的物品。
MLlib目前支持基于协同过滤的模型,在这个模型里,用户和产品被一组可以用来预测缺失项目的潜在因子来描述。特别是我们实现交替最小二乘(ALS)算法来学习这些潜在的因子,在 MLlib 中的实现有如下参数:
- numBlocks是用于并行化计算的分块个数(设置为-1时 为自动配置);
- rank是模型中隐性因子的个数;
- iterations是迭代的次数;
- lambda是ALS 的正则化参数;
- implicitPrefs决定了是用显性反馈ALS 的版本还是用隐性反馈数据集的版本;
- alpha是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。

实例介绍
在本实例中将使用协同过滤算法对GroupLens Research(http://grouplens.org/datasets/movielens/)提供的数据进行分析,该数据为一组从20世纪90年末到21世纪初由MovieLens用户提供的电影评分数据,这些数据中包括电影评分、电影元数据(风格类型和年代)以及关于用户的人口统计学数据(年龄、邮编、性别和职业等)。根据不同需求该组织提供了不同大小的样本数据,不同样本信息中包含三种数据:评分、用户信息和电影信息。
对这些数据分析进行如下步骤:
1. 装载如下两种数据:
a)装载样本评分数据,其中最后一列时间戳除10的余数作为key,Rating为值;
b)装载电影目录对照表(电影ID->电影标题)
2.将样本评分表以key值切分成3个部分,分别用于训练 (60%,并加入用户评分), 校验 (20%), and 测试 (20%)
3.训练不同参数下的模型,并再校验集中验证,获取最佳参数下的模型
4.用最佳模型预测测试集的评分,计算和实际评分之间的均方根误差
5.根据用户评分的数据,推荐前十部最感兴趣的电影(注意要剔除用户已经评分的电影)
测试数据说明
在MovieLens提供的电影评分数据分为三个表:评分、用户信息和电影信息,在该系列提供的附属数据提供大概6000位读者和100万个评分数据,具体位置为/data/class8/movielens/data目录下,对三个表数据说明可以参考该目录下README文档。
1.评分数据说明(ratings.data)
该评分数据总共四个字段,格式为UserID::MovieID::Rating::Timestamp,分为为用户编号::电影编号::评分::评分时间戳,其中各个字段说明如下:
- 用户编号范围1~6040
- 电影编号1~3952
- 电影评分为五星评分,范围0~5
- 评分时间戳单位秒
- 每个用户至少有20个电影评分
使用的ratings.dat的数据样本如下所示:
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
1::1197::3::978302268
1::1287::5::978302039
1::2804::5::978300719
2.用户信息(users.dat)
用户信息五个字段,格式为UserID::Gender::Age::Occupation::Zip-code,分为为用户编号::性别::年龄::职业::邮编,其中各个字段说明如下:
- 用户编号范围1~6040
- 性别,其中M为男性,F为女性
- 不同的数字代表不同的年龄范围,如:25代表25~34岁范围
- 职业信息,在测试数据中提供了21中职业分类
- 地区邮编
使用的users.dat的数据样本如下所示:
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
4::M::45::7::02460
5::M::25::20::55455
6::F::50::9::55117
7::M::35::1::06810
8::M::25::12::11413
3.电影信息(movies.dat)
电影数据分为三个字段,格式为MovieID::Title::Genres,分为为电影编号::电影名::电影类别,其中各个字段说明如下:
- 电影编号1~3952
- 由IMDB提供电影名称,其中包括电影上映年份
- 电影分类,这里使用实际分类名非编号,如:Action、Crime等
使用的movies.dat的数据样本如下所示:
1::Toy Story (1995)::Animation|Children's|Comedy 2::Jumanji (1995)::Adventure|Children's|Fantasy 3::Grumpier Old Men (1995)::Comedy|Romance 4::Waiting to Exhale (1995)::Comedy|Drama 5::Father of the Bride Part II (1995)::Comedy 6::Heat (1995)::Action|Crime|Thriller 7::Sabrina (1995)::Comedy|Romance 8::Tom and Huck (1995)::Adventure|Children's
程序代码
import java.io.File import scala.io.Source import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.rdd._ import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel} object MovieLensALS { def main(args: Array[String]) {
// 屏蔽不必要的日志显示在终端上 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) if (args.length != 2) { println("Usage: /path/to/spark/bin/spark-submit --driver-memory 2g --class week7.MovieLensALS " + "week7.jar movieLensHomeDir personalRatingsFile") sys.exit(1) } // 设置运行环境 val conf = new SparkConf().setAppName("MovieLensALS").setMaster("local[4]") val sc = new SparkContext(conf) // 装载用户评分,该评分由评分器生成 val myRatings = loadRatings(args(1)) val myRatingsRDD = sc.parallelize(myRatings, 1) // 样本数据目录 val movieLensHomeDir = args(0) // 装载样本评分数据,其中最后一列Timestamp取除10的余数作为key,Rating为值,即(Int,Rating) val ratings = sc.textFile(new File(movieLensHomeDir, "ratings.dat").toString).map { line => val fields = line.split("::") (fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)) } // 装载电影目录对照表(电影ID->电影标题) val movies = sc.textFile(new File(movieLensHomeDir, "movies.dat").toString).map { line => val fields = line.split("::") (fields(0).toInt, fields(1)) }.collect().toMap val numRatings = ratings.count() val numUsers = ratings.map(_._2.user).distinct().count() val numMovies = ratings.map(_._2.product).distinct().count() println("Got " + numRatings + " ratings from " + numUsers + " users on " + numMovies + " movies.") // 将样本评分表以key值切分成3个部分,分别用于训练 (60%,并加入用户评分), 校验 (20%), and 测试 (20%) // 该数据在计算过程中要多次应用到,所以cache到内存 val numPartitions = 4 val training = ratings.filter(x => x._1 < 6) .values .union(myRatingsRDD) //注意ratings是(Int,Rating),取value即可 .repartition(numPartitions) .cache() val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8) .values .repartition(numPartitions) .cache() val test = ratings.filter(x => x._1 >= 8).values.cache() val numTraining = training.count() val numValidation = validation.count() val numTest = test.count() println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)
// 训练不同参数下的模型,并在校验集中验证,获取最佳参数下的模型 val ranks = List(8, 12) val lambdas = List(0.1, 10.0) val numIters = List(10, 20) var bestModel: Option[MatrixFactorizationModel] = None var bestValidationRmse = Double.MaxValue var bestRank = 0 var bestLambda = -1.0 var bestNumIter = -1 for (rank <- ranks; lambda <- lambdas; numIter <- numIters) { val model = ALS.train(training, rank, numIter, lambda) val validationRmse = computeRmse(model, validation, numValidation) println("RMSE (validation) = " + validationRmse + " for the model trained with rank = " + rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".") if (validationRmse < bestValidationRmse) { bestModel = Some(model) bestValidationRmse = validationRmse bestRank = rank bestLambda = lambda bestNumIter = numIter } } // 用最佳模型预测测试集的评分,并计算和实际评分之间的均方根误差 val testRmse = computeRmse(bestModel.get, test, numTest) println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda + ", and numIter = " + bestNumIter + ", and its RMSE on the test set is " + testRmse + ".") // create a naive baseline and compare it with the best model val meanRating = training.union(validation).map(_.rating).mean val baselineRmse = math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean) val improvement = (baselineRmse - testRmse) / baselineRmse * 100 println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.") // 推荐前十部最感兴趣的电影,注意要剔除用户已经评分的电影 val myRatedMovieIds = myRatings.map(_.product).toSet val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq) val recommendations = bestModel.get .predict(candidates.map((0, _))) .collect() .sortBy(-_.rating) .take(10) var i = 1 println("Movies recommended for you:") recommendations.foreach { r => println("%2d".format(i) + ": " + movies(r.product)) i += 1 } sc.stop() } /** 校验集预测数据和实际数据之间的均方根误差 **/ def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = { val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product))) val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating)) .join(data.map(x => ((x.user, x.product), x.rating))) .values math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n) } /** 装载用户评分文件 **/ def loadRatings(path: String): Seq[Rating] = { val lines = Source.fromFile(path).getLines() val ratings = lines.map { line => val fields = line.split("::") Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble) }.filter(_.rating > 0.0) if (ratings.isEmpty) { sys.error("No ratings provided.") } else { ratings.toSeq } } }
IDEA执行情况
第一步 使用如下命令启动Spark集群
$cd /app/hadoop/spark-1.1.0 $sbin/start-all.sh
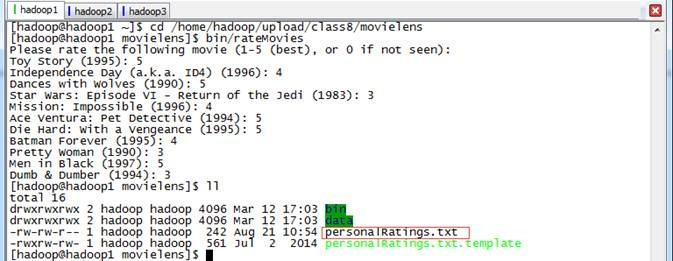
第二步 进行用户评分,生成用户样本数据
由于该程序中最终推荐给用户十部电影,这需要用户提供对样本电影数据的评分,然后根据生成的最佳模型获取当前用户推荐电影。用户可以使用/home/hadoop/upload/class8/movielens/bin/rateMovies程序进行评分,最终生成personalRatings.txt文件:
第三步 在IDEA中设置运行环境
在IDEA运行配置中设置MovieLensALS运行配置,需要设置输入数据所在文件夹和用户的评分文件路径:
- 输入数据所在目录:输入数据文件目录,在该目录中包含了评分信息、用户信息和电影信息,这里设置为/home/hadoop/upload/class8/movielens/data/
- 用户的评分文件路径:前一步骤中用户对十部电影评分结果文件路径,在这里设置为/home/hadoop/upload/class8/movielens/personalRatings.txt
第四步 执行并观察输出
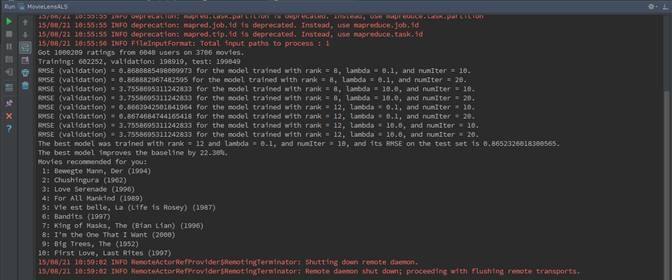
- 输出Got 1000209 ratings from 6040 users on 3706 movies,表示本算法中计算数据包括大概100万评分数据、6000多用户和3706部电影;
- 输出Training: 602252, validation: 198919, test: 199049,表示对评分数据进行拆分为训练数据、校验数据和测试数据,大致占比为6:2:2;
- 在计算过程中选择8种不同模型对数据进行训练,然后从中选择最佳模型,其中最佳模型比基准模型提供22.30%
RMSE (validation) = 0.8680885498009973 for the model trained with rank = 8, lambda = 0.1, and numIter = 10.
RMSE (validation) = 0.868882967482595 for the model trained with rank = 8, lambda = 0.1, and numIter = 20.
RMSE (validation) = 3.7558695311242833 for the model trained with rank = 8, lambda = 10.0, and numIter = 10.
RMSE (validation) = 3.7558695311242833 for the model trained with rank = 8, lambda = 10.0, and numIter = 20.
RMSE (validation) = 0.8663942501841964 for the model trained with rank = 12, lambda = 0.1, and numIter = 10.
RMSE (validation) = 0.8674684744165418 for the model trained with rank = 12, lambda = 0.1, and numIter = 20.
RMSE (validation) = 3.7558695311242833 for the model trained with rank = 12, lambda = 10.0, and numIter = 10.
RMSE (validation) = 3.7558695311242833 for the model trained with rank = 12, lambda = 10.0, and numIter = 20.
The best model was trained with rank = 12 and lambda = 0.1, and numIter = 10, and its RMSE on the test set is 0.8652326018300565.
The best model improves the baseline by 22.30%.
- 利用前面获取的最佳模型,结合用户提供的样本数据,最终推荐给用户如下影片:
Movies recommended for you:
1: Bewegte Mann, Der (1994)
2: Chushingura (1962)
3: Love Serenade (1996)
4: For All Mankind (1989)
5: Vie est belle, La (Life is Rosey) (1987)
6: Bandits (1997)
7: King of Masks, The (Bian Lian) (1996)
8: I'm the One That I Want (2000)
9: Big Trees, The (1952)
10: First Love, Last Rites (1997)