郑昀 创建于2015/12/2 最后更新于2015/12/4
关键词:数据库,MySQL,自动化运维,DDL,DML,SQL审核,备份,回滚,Inception,osc
提纲:
- 普通DBA和文艺DBA怎么做SQL审核
- 预执行库如何实操
- Inception对备份/回滚服务器的特殊处理
每个大型互联网公司都有一个数据库自动化运维系统,比如 Qunar 有 Inception(已开源),美团也有,赶集网的3个 DBA 开发了一个变更自助发布系统,淘宝和新浪呢都叫 iDB,腾讯互动娱乐团队有个 TMySQL。
大家都做这件事,一定是因为当数据量大到一定程度,数据重要到一定程度时,online schema change 和刷库不容有失,第一解决锁表问题,不能影响线上业务,第二搞定操作回滚问题,第三解救 DBA 于倒悬。我们的实现请参考《#研发解决方案#iDB-数据库自动化运维平台》。
0x00,普通DBA和文艺DBA怎么做SQL审核
无论是 DDL 操作,还是数据订正(也被称为 DML 操作),都涉及 SQL 审核、预执行和数据备份及回滚。
1,普通 DBA 青年的做法是:
- Dev 或 CM 给 DBA 发执行脚本,
- DBA 肉眼审核,
- 语法错误/语义错误/不符合规范/……
- 驳回,修改,审核,再驳回,……,通过,
- DBA 执行前做一次全表备份,
- 援引 Inception 文档的原话:
- 『备份是必要的,因为语句在没有执行时,都是想不到它影响会有多大,一般是不需要,而需要时,才知道备份是多么的重要,这也正是应了一句谚语:“书到用时方恨少,事非经过不知难。”,但这个工作也很让人为难,应该备份全表呢?还是把影响的查出来备份呢?DBA在这个时候肯定是不愿意这样做的,但万一出问题怎么办?都懂得,不说了。』
- 执行,
- Dev 或 QA 检查,
- 收兵,或许有问题,则备份还原。
2,稍微文艺一些的 DBA 青年的做法是:
- Dev 或 CM 登录自动化运维系统,提交 SQL 脚本,
- SQL 审核组件对脚本自动审核,检查语法,检查规范,
- DBA 点击预执行,脚本在测试数据库上 explain 或直接执行,获得第一手数据,
- 影响行数,索引使用情况
- 预估执行时间
- DBA 确认无误后,审核通过,系统按时在生产库上执行,执行前系统将生产库数据备份。
或者援引 Inception 文档里的这张图示意:
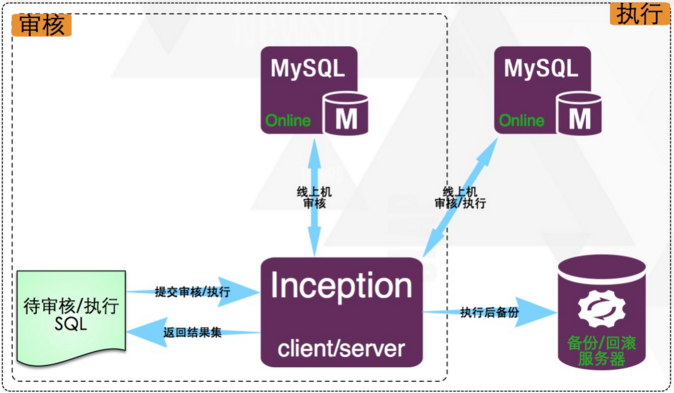
图1 Inception的架构
0x01,预执行库如何实操
我们云纵对 iDB 的设想是,当审核 DDL 操作时,环境中部署一个预执行库。当 iDB 上要做预执行时,iDB 程序调用命令行暂停预执行库的同步,等预执行回滚之后恢复同步,避免因为表结构变化而同步停止。预执行库不需要配置为 blackhole,因为我们需要真实数据来获得执行耗时,来决定我们应以什么策略在线上自动执行。
下面展示一下预执行时审核详情页上点击”生成执行明细“按钮的效果:
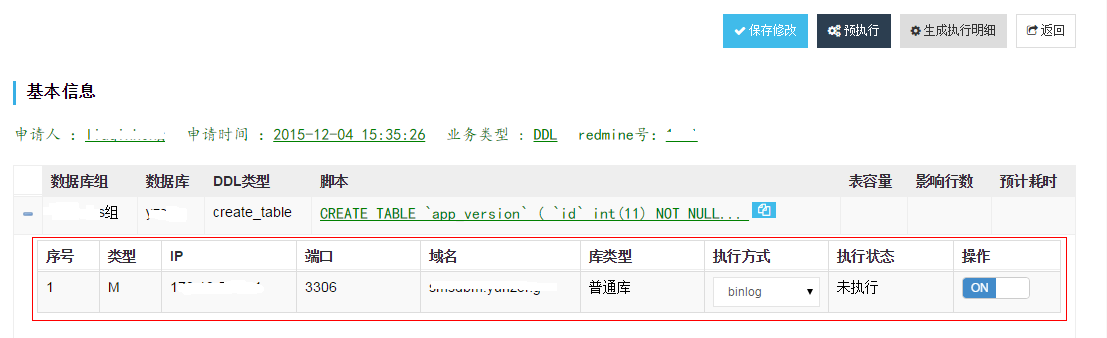
我们可以在这里选一下“执行方式”,共有三种可选:
- nobinlog:适合我们的 Cobar 库,合并库和主站库。先执行从库,再执行主库。从库执行之后,会给30分钟时间确认是否执行主库。
- binlog:非 Cobar 库操作。
- osc:对应于 MySQL 的在线 schema 修改工具 pt-online-schema-change。它先创建一个 tmp 表作为原表导数据的临时表,然后在原表上建立三个触发器,对应 Insert、Update、Delete 三种操作,再拷贝原表数据到临时表中,Rename 原表为 old 表,再把临时表 Rename 为原表,最后清理以上过程中不再使用的数据,如 old 表。它强调的是”在线更改表结构“,适合于大表。我们看一下 Inception 怎么做的:Inception 有一个设置项 inception_osc_min_table_size,默认为 16MB,表示表空间占用大于 16MB 时自动选择 osc 方式执行。
0x02,Inception 对备份/回滚服务器的特殊处理
Inception 在做 DML 操作时,会将所有当前语句修改的行备份下来,存储到一个指定的库中。Qunar 在这里有一些特殊设计,值得借鉴。
下面文字搬运自他们的文档:
备份数据在备份机器的存储,是与线上被修改库一对一的。但因为机器多(线上机器有很多)对一(备份机器只有一台),所以为了防止库名的冲突,备份机器的库名组成是由线上机器的 IP 地址的点换成下划线,再加上端口号,再加上库名三部分,这三部分也是通过下划线连接起来的。例如:
192_168_1_1_3310_inceptiondb
一个备份库,里面的表与对应线上表都是一一对应的,也就是说线上库 inceptiondb 中有什么表,在备份库 192_168_1_1_3310_inceptiondb 中就有什么表,表名也完全相同,不同的只是表中的列不同而已,它是用来存储所有对这个表修改的回滚语句的,对应的表包括的列主要有下面两个:
rollback_statement text:这个列存储的是针对当前这个表的某一行被修改后,生成的这行修改的回滚语句。因为 binlog 是 Row 模式的,所以不管是什么语句,产生的回滚语句都是针对一行的,同时有可能一条语句的修改影响了多行,那么这里就会有多个回滚语句,但对应的是同一个 SQL 语句。对应关于通过下面的列来关联起来。
opid_time varchar(50):这个列存储的是的被执行的 SQL 语句在执行时的一个序列号,这个序列号由三部分组成:timestamp(int 值,是语句被执行的时间点),线上服务器执行时所产生的 thread_id,当前这条语句在所有被执行的语句块中的一个序号。产生结果类似下面的样子:1413347135_136_3,针对同一个语句影响多行的情况,那么所产生的多行数据中,这个列的值都是相同的,这样就可以找到一条语句对应的所有被影响数据的回滚语句。
于是线上库表结果与备份库表结构的对应关系为:
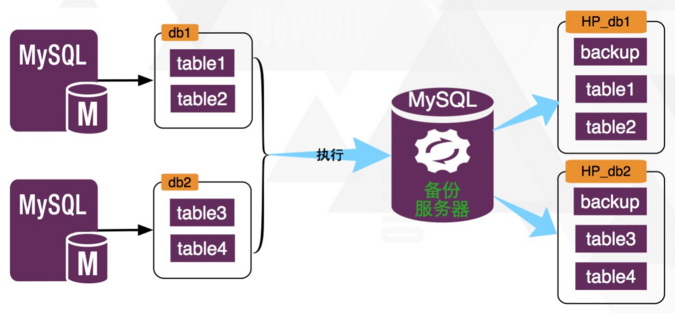
图2 Inception的备份服务器
-未完待续-
参考资源:
2,2014,isadba,pt-online-schema-change工具文艺用法;
3,2014,博客园-王滔,mysql在线修改表结构大数据表的风险与解决办法归纳;
4,2011,杨挺,OSC 实现原理剖析;
5,2015,郑昀,#研发解决方案#iDB-数据库自动化运维平台;
