1、 DISTINCT 去重的用法
从 "Websites" 表的 "country" 列中选取唯一不同的值,也就是去掉 "country" 列重复值:
select DISTINCT country from Websites
2、Where的用法
从 "Websites" 表中选取国家为 "CN" 的所有网站:
select * from Websites where country = 'CN'
3、AND和OR的用法
从 "Websites" 表中选取国家为 "CN" 且alexa排名大于 "50" 的所有网站:
从 "Websites" 表中选取国家为 "USA" 或者 "CN" 的所有客户:
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
+----+--------------+---------------------------+-------+---------+
select * from Websites where country='CN' AND alexa>50
select * from Websites where country='CN' or country='USA'
AND和OR结合起来的用法就是:
SELECT * FROM Websites WHERE alexa > 15 AND (country='CN' OR country='USA')
4、ORDER BY 的用法,关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字
ORDER BY 排列时,不写明ASC,DESC(倒序)的时候,默认是ASC(正序)
+----+--------------+---------------------------+-------+---------+| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
+----+--------------+---------------------------+-------+---------+
从 "Websites" 表中选取所有网站,并按照 "alexa" 列排序:
select * from Websites order by alexa
多列的排序:
SELECT * FROM Websites ORDER BY country,alexa
5、INSERT INTO 语句用于向表中插入新记录,没有指定要插入数据的列名的形式需要列出插入行的每一列数据
+----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | +----+--------------+---------------------------+-------+---------+
向 "Websites" 表中插入一个新行:
insert into Websites (name, url, alexa, country) VALUES ('百度','https://www.baidu.com/','4','CN');
插入一个新行,但是只在 "name"、"url" 和 "country" 列插入数据(id 字段会自动更新):
INSERT INTO Websites (name, url, country) VALUES ('stackoverflow', 'http://stackoverflow.com/', 'IND');
6、UPDATE 语句用于更新表中已存在的记录
+----+--------------+---------------------------+-------+---------+| id | name | url | alexa | country |+----+--------------+---------------------------+-------+---------+|1|Google| https://www.google.cm/ | 1 | USA ||2|淘宝| https://www.taobao.com/ | 13 | CN ||3|菜鸟教程| http://www.runoob.com/ | 4689 | CN ||4|微博| http://weibo.com/ | 20 | CN ||5|Facebook| https://www.facebook.com/ | 3 | USA |+----+--------------+---------------------------+-------+---------+
我们要把表中的 alexa 排名更新为 5000,country 改为 USA:
update Websites set alexa='5000' ,country='USA' where name = '菜鸟教程'
7、DELETE 语句用于删除表中的行
DELETE FROM table_name WHERE some_column=some_value;
从 "Websites" 表中删除网站名为 "Facebook" 且国家为 USA 的网站:
DELETE FROM Websites WHERE name='Facebook' AND country='USA';
8、SELECT TOP 子句用于规定要返回的记录的数目
注意:并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
mysql语法:
select * from Websites limit 5
Oracle语法:
select * from Websites where rownum >=100
示例:
从 "Websites" 表中选取头两条记录:
SELECT * FROM Websites LIMIT 2
SQL函数
1、AVG() 函数
AVG() 函数返回数值列的平均值
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
①从 "access_log" 表的 "count" 列获取平均值:
select AVG(count) as CountAverage FROM access_log
②查询访问量高于平均访问量的 "site_id" 和 "count":
select site_id,count from access_log where count >(select avg(count) from access_log)
2、COUNT() 函数返回匹配指定条件的行数
①COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
select COUNT(column_name) from table_name
②COUNT(*) 函数返回表中的记录数:
select count(*) from table_name
③COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
select count(distinct column_name ) from table_name
示例:
+-----+---------+-------+------------+ | aid | site_id | count | date | +-----+---------+-------+------------+ | 1 | 1 | 45 | 2016-05-10 | | 2 | 3 | 100 | 2016-05-13 | | 3 | 1 | 230 | 2016-05-14 | | 4 | 2 | 10 | 2016-05-14 | | 5 | 5 | 205 | 2016-05-14 | | 6 | 4 | 13 | 2016-05-15 | | 7 | 3 | 220 | 2016-05-15 | | 8 | 5 | 545 | 2016-05-16 | | 9 | 3 | 201 | 2016-05-17 | +-----+---------+-------+------------+
计算 "access_log" 表中 "site_id"=3 的总访问量:
select count(count) from access_log where site_id=3
计算 "access_log" 表中总记录数:
SELECT COUNT(*) AS nums FROM access_log;
计算 "access_log" 表中不同 site_id 的记录数:
select count(distinct site_id) as nums from access_log
-- 查询websites 表中 alexa列中不为空的记录的条数
select count(alexa) from websites;
3、FIRST() 函数返回指定的列中第一个记录的值
mysql语法
SELECT name FROM Websites
ORDER BY id ASC
LIMIT 1;
Oracle语法
select name from Websites order by id asc where rownum <=1
4、LAST() 函数返回指定的列中最后一个记录的值
mysql语法
SELECT name FROM Websites
ORDER BY id DESC
LIMIT 1;
Oracle语法
select name from Websites order by id desc where rownum <=1
5、MAX() 函数返回指定列的最大值,MIN() 函数返回指定列的最小值。
+----+--------------+---------------------------+-------+---------+| id | name | url | alexa | country |+----+--------------+---------------------------+-------+---------+|1|Google| https://www.google.cm/ | 1 | USA ||2|淘宝| https://www.taobao.com/ | 13 | CN ||3|菜鸟教程| http://www.runoob.com/ | 5000 | CN ||4|微博| http://weibo.com/ | 20 | CN ||5|Facebook| https://www.facebook.com/ | 3 | USA ||6|百度| https://www.baidu.com/ | 4 | CN ||7| stackoverflow | http://stackoverflow.com/ | 0 | IND |+----+---------------+---------------------------+-------+---------+
从 "Websites" 表的 "alexa" 列获取最大值:
select max(alexa) as max_alexa from Websites
从 "Websites" 表的 "alexa" 列获取最小值:
select min(alexa) as min_alexa from Websites
6、SUM() 函数返回数值列的总数。
+-----+---------+-------+------------+| aid | site_id | count | date |+-----+---------+-------+------------+|1|1|45|2016-05-10||2|3|100|2016-05-13||3|1|230|2016-05-14||4|2|10|2016-05-14||5|5|205|2016-05-14||6|4|13|2016-05-15||7|3|220|2016-05-15||8|5|545|2016-05-16||9|3|201|2016-05-17|+-----+---------+-------+------------+
查找 "access_log" 表的 "count" 字段的总数:
select sum(count) as nums from access_log
7、GROUP BY 语句可结合一些聚合函数来使用
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
GROUP BY语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
Group By 和 Order By
select 类别, sum(数量) AS 数量之和
from A
group by 类别
order by sum(数量) desc
下面是选自 "Websites" 表的数据:
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
下面是 "access_log" 网站访问记录表的数据:
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
统计 access_log 各个 site_id 的访问量:
select sit_id,sum(access_log.count) as nums from access_log group by site_id
统计有记录的网站的记录数量:
select Websites.name ,COUNT(access_log.aid) as nums from access_log LEFT JOIN Websites ON access_log.site_id=Websites.id GROUP BY Websites.name;
SQL的GROUP BY用法小结,利用聚合函数进行分组
使用COUNT()、AVG()、MIN()、MAX()等聚合函数可实现对分组的过滤,聚合函数会分别对各组数据进行聚合
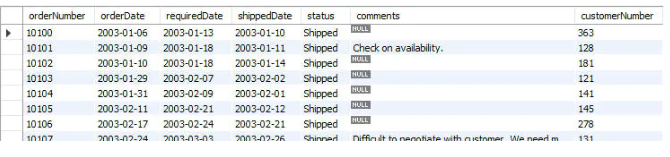
按照status列将订单分组并计算各组包含的订单条目数:
SELECT status, COUNT(status) FROM orders GROUP BY status;
若希望计算每个订单中包含商品的总价,则有
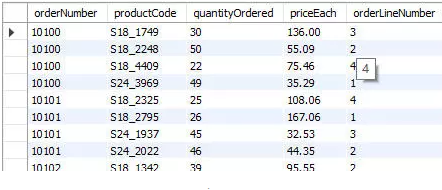
SELECT
orderNumber,
SUM(quantityOrdered * priceEach) AS amount
FROM orderdetails
GROUP BY orderNumber;8、在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
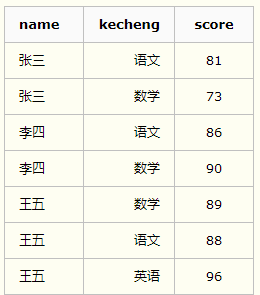
查询 xuesheng表每门课都大于80 分的学生姓名:
SELECTnameFROM xuesheng GROUPBYnameHAVINGMIN(score)> 80
如果考虑学生的课程数大于等于3的情况
SELECTnameFROM xuesheng GROUPBYnameHAVINGMIN(score)> 80ANDCOUNT(kecheng)>=3
统计 access_log 各个 site_id 的访问量:SELECT column_name FROM table_name
ORDER BY column_name ASC
LIMIT 1;
Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
多表查询
语法:
select 要查询的字段
from 表1,表2,表3.......
where member.Id = invest .memberId
and loan.Id = invest.loanId
and 过滤条件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
SQL常见面试题
1.用一条SQL 语句 查询出每门课都大于80 分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
A: select distinct name from table where name not in (select distinct name from table where fenshu<=80)
select name from table group by name having min(fenshu)>80
2. 学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同, 其他都相同的学生冗余信息
A: delete tablename where 自动编号 not in(select min( 自动编号) from tablename group by学号, 姓名, 课程编号, 课程名称, 分数)
3.一个叫 team 的表,里面只有一个字段name, 一共有4 条纪录,分别是a,b,c,d, 对应四个球对,现在四个球对进行比赛,用一条sql 语句显示所有可能的比赛组合.
你先按你自己的想法做一下,看结果有我的这个简单吗?
答:select a.name, b.name
from team a, team b
where a.name < b.name
4.请用SQL 语句实现:从TestDB 数据表中查询出所有月份的发生额都比101 科目相应月份的发生额高的科目。请注意:TestDB 中有很多科目,都有1 -12 月份的发生额。
AccID :科目代码,Occmonth :发生额月份,DebitOccur :发生额。
数据库名:JcyAudit ,数据集:Select * from TestDB
答:select a.*
from TestDB a
,(select Occmonth,max(DebitOccur) Debit101ccur from TestDB where AccID='101' group by Occmonth) b
where a.Occmonth=b.Occmonth and a.DebitOccur>b.Debit101ccur
************************************************************************************
5.面试题:怎么把这样一个表儿
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
答案一、
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year
*******************************************************************************
6. 说明:复制表( 只复制结构, 源表名:a新表名:b)
SQL: select * into b from a where 1<>1 (where1=1,拷贝表结构和数据内容)
Oracle:create table b
As
Select * from a where 1=2
比较两个表达式。 当使用此运算符比较非空表达式时,如果左操作数不等于右操作数,则结果为 TRUE。 否则,结果为 FALSE。]
7. 说明:拷贝表( 拷贝数据, 源表名:a目标表名:b)
SQL: insert into b(a, b, c) select d,e,f from a;
8. 说明:显示文章、提交人和最后回复时间
SQL: select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
9. 说明:外连接查询( 表名1 :a表名2 :b)
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUTER JOIN b ON a.a = b.c
ORACLE:select a.a, a.b, a.c, b.c, b.d, b.f from a ,b
where a.a = b.c(+)
10. 说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f 开始时间,getdate())>5
11. 说明:两张关联表,删除主表中已经在副表中没有的信息
SQL:
Delete from info where not exists (select * from infobz where info.infid=infobz.infid )
*******************************************************************************
12.有两个表A 和B ,均有key 和value 两个字段,如果B 的key 在A 中也有,就把B 的value 换为A 中对应的value
这道题的SQL 语句怎么写?
update b set b.value=(select a.value from a where a.key=b.key) where b.id in(select b.id from b,a where b.key=a.key);
***************************************************************************
13.高级sql 面试题
原表:
courseid coursename score
-------------------------------------
1 Java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
-------------------------------------
为了便于阅读, 查询此表后的结果显式如下( 及格分数为60):
courseid coursename score mark
---------------------------------------------------
1 Java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
---------------------------------------------------
写出此查询语句
select courseid, coursename ,score ,decode(sign(score-60),-1,'fail','pass') as mark from course
完全正确
SQL> desc course_v
Name Null? Type
----------------------------------------- -------- ----------------------------
COURSEID NUMBER
COURSENAME VARCHAR2(10)
SCORE NUMBER
SQL> select * from course_v;
COURSEID COURSENAME SCORE
---------- ---------- ----------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
SQL> select courseid, coursename ,score ,decode(sign(score-60),-1,'fail','pass') as mark from course_v;
COURSEID COURSENAME SCORE MARK
---------- ---------- ---------- ----
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
SQL面试题(1)
create table testtable1
(
id int IDENTITY,
department varchar(12)
)
select * from testtable1
insert into testtable1 values('设计')
insert into testtable1 values('市场')
insert into testtable1 values('售后')
/*
结果
id department
1 设计
2 市场
3 售后
*/
create table testtable2
(
id int IDENTITY,
dptID int,
name varchar(12)
)
insert into testtable2 values(1,'张三')
insert into testtable2 values(1,'李四')
insert into testtable2 values(2,'王五')
insert into testtable2 values(3,'彭六')
insert into testtable2 values(4,'陈七')
/*
用一条SQL语句,怎么显示如下结果
id dptID department name
1 1 设计 张三
2 1 设计 李四
3 2 市场 王五
4 3 售后 彭六
5 4 黑人 陈七
*/
答案:
SELECT testtable2.* , ISNULL(department,'黑人')
FROM testtable1 right join testtable2 on testtable2.dptID = testtable1.ID
也做出来了可比这方法稍复杂。
sql面试题(2)
有表A,结构如下:
A: p_ID p_Num s_id
1 10 01
1 12 02
2 8 01
3 11 01
3 8 03
其中:p_ID为产品ID,p_Num为产品库存量,s_id为仓库ID。请用SQL语句实现将上表中的数据合并,合并后的数据为:
p_ID s1_id s2_id s3_id
1 10 12 0
2 8 0 0
3 11 0 8
其中:s1_id为仓库1的库存量,s2_id为仓库2的库存量,s3_id为仓库3的库存量。如果该产品在某仓库中无库存量,那么就是0代替。
结果:
select p_id ,
sum(case when s_id=1 then p_num else 0 end) as s1_id
,sum(case when s_id=2 then p_num else 0 end) as s2_id
,sum(case when s_id=3 then p_num else 0 end) as s3_id
from myPro group by p_id
SQL面试题(3)
1.触发器的作用?
答:触发器是一中特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
2。什么是存储过程?用什么来调用?
答:存储过程是一个预编译的SQL 语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL ,使用存储过程比单纯SQL 语句执行要快。可以用一个命令对象来调用存储过程。
3。索引的作用?和它的优点缺点是什么?
答:索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。缺点是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
3。什么是内存泄漏?
答:一般我们所说的内存泄漏指的是堆内存的泄漏。堆内存是程序从堆中为其分配的,大小任意的,使用完后要显示释放内存。当应用程序用关键字new 等创建对象时,就从堆中为它分配一块内存,使用完后程序调用free 或者delete 释放该内存,否则就说该内存就不能被使用,我们就说该内存被泄漏了。
4。维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?
答:我是这样做的,尽可能使用约束,如check, 主键,外键,非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据的完整新和一致性。最后考虑的是自写业务逻辑,但这样做麻烦,编程复杂,效率低下。
5。什么是事务?什么是锁?
答:事务就是被绑定在一起作为一个逻辑工作单元的SQL 语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过ACID 测试,即原子性,一致性,隔离性和持久性。
锁:在所以的 DBMS中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
6。什么叫视图?游标是什么?
答:视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
7。为管理业务培训信息,建立3个表:
S(S#,SN,SD,SA)S#,SN,SD,SA分别代表学号,学员姓名,所属单位,学员年龄
C(C#,CN)C#,CN分别代表课程编号,课程名称
SC(S#,C#,G) S#,C#,G分别代表学号,所选的课程编号,学习成绩
(1)使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
答案:select s# ,sn from s where S# in(select S# from c,sc where c.c#=sc.c# and cn=’税收基础’)
(2) 使用标准SQL嵌套语句查询选修课程编号为’C2’的学员姓名和所属单位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’
(3) 使用标准SQL嵌套语句查询不选修课程编号为’C5’的学员姓名和所属单位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查询选修了课程的学员人数
答:select 学员人数=count(distinct s#) from sc
(5) 查询选修课程超过5门的学员学号和所属单位?
答:select sn,sd from s where s# in(select s# from sc group by s# having count(distinct c#)>5)
SQL面试题(4)
1.查询A(ID,Name)表中第31至40条记录,ID作为主键可能是不是连续增长的列,完整的查询语句如下:
select top 10 * from A where ID >(select max(ID) from (select top 30 ID from A order by A ) T) order by A
2.查询表A中存在ID重复三次以上的记录,完整的查询语句如下:
select * from(select count(ID) as count from table group by ID)T where T.count>3
SQL面试题(5)
在面试应聘的SQL Server数据库开发人员时,我运用了一套标准的基准技术问题。下面这些问题是我觉得能够真正有助于淘汰不合格应聘者的问题。它们按照从易到难的顺序排列。当你问到关于主键和外键的问题时,后面的问题都十分有难度,因为答案可能会更难解释和说明,尤其是在面试的情形下。
你能向我简要叙述一下SQL Server 2000中使用的一些数据库对象吗?
你希望听到的答案包括这样一些对象:表格、视图、用户定义的函数,以及存储过程;如果他们还能够提到像触发器这样的对象就更好了。如果应聘者不能回答这个基本的问题,那么这不是一个好兆头。
NULL是什么意思?
NULL(空)这个值是数据库世界里一个非常难缠的东西,所以有不少应聘者会在这个问题上跌跟头您也不要觉得意外。
NULL这个值表示UNKNOWN(未知):它不表示“”(空字符串)。假设您的SQL Server数据库里有ANSI_NULLS,当然在默认情况下会有,对NULL这个值的任何比较都会生产一个NULL值。您不能把任何值与一个 UNKNOWN值进行比较,并在逻辑上希望获得一个答案。您必须使用IS NULL操作符。
什么是索引?SQL Server 2000里有什么类型的索引?
任何有经验的数据库开发人员都应该能够很轻易地回答这个问题。一些经验不太多的开发人员能够回答这个问题,但是有些地方会说不清楚。
简单地说,索引是一个数据结构,用来快速访问数据库表格或者视图里的数据。在SQL Server里,它们有两种形式:聚集索引和非聚集索引。聚集索引在索引的叶级保存数据。这意味着不论聚集索引里有表格的哪个(或哪些)字段,这些字段都会按顺序被保存在表格。由于存在这种排序,所以每个表格只会有一个聚集索引。非聚集索引在索引的叶级有一个行标识符。这个行标识符是一个指向磁盘上数据的指针。它允许每个表格有多个非聚集索引。
什么是主键?什么是外键?
主键是表格里的(一个或多个)字段,只用来定义表格里的行;主键里的值总是唯一的。外键是一个用来建立两个表格之间关系的约束。这种关系一般都涉及一个表格里的主键字段与另外一个表格(尽管可能是同一个表格)里的一系列相连的字段。那么这些相连的字段就是外键。
什么是触发器?SQL Server 2000有什么不同类型的触发器?
让未来的数据库开发人员知道可用的触发器类型以及如何实现它们是非常有益的。
触发器是一种专用类型的存储过程,它被捆绑到SQL Server 2000的表格或者视图上。在SQL Server 2000里,有INSTEAD-OF和AFTER两种触发器。INSTEAD-OF触发器是替代数据操控语言(Data Manipulation Language,DML)语句对表格执行语句的存储过程。例如,如果我有一个用于TableA的INSTEAD-OF-UPDATE触发器,同时对这个表格执行一个更新语句,那么INSTEAD-OF-UPDATE触发器里的代码会执行,而不是我执行的更新语句则不会执行操作。
AFTER触发器要在DML语句在数据库里使用之后才执行。这些类型的触发器对于监视发生在数据库表格里的数据变化十分好用。
您如何确一个带有名为Fld1字段的TableB表格里只具有Fld1字段里的那些值,而这些值同时在名为TableA的表格的Fld1字段里?
这个与关系相关的问题有两个可能的答案。第一个答案(而且是您希望听到的答案)是使用外键限制。外键限制用来维护引用的完整性。它被用来确保表格里的字段只保存有已经在不同的(或者相同的)表格里的另一个字段里定义了的值。这个字段就是候选键(通常是另外一个表格的主键)。
另外一种答案是触发器。触发器可以被用来保证以另外一种方式实现与限制相同的作用,但是它非常难设置与维护,而且性能一般都很糟糕。由于这个原因,微软建议开发人员使用外键限制而不是触发器来维护引用的完整性。
对一个投入使用的在线事务处理表格有过多索引需要有什么样的性能考虑?
你正在寻找进行与数据操控有关的应聘人员。对一个表格的索引越多,数据库引擎用来更新、插入或者删除数据所需要的时间就越多,因为在数据操控发生的时候索引也必须要维护。
你可以用什么来确保表格里的字段只接受特定范围里的值?
这个问题可以用多种方式来回答,但是只有一个答案是“好”答案。您希望听到的回答是Check限制,它在数据库表格里被定义,用来限制输入该列的值。
触发器也可以被用来限制数据库表格里的字段能够接受的值,但是这种办法要求触发器在表格里被定义,这可能会在某些情况下影响到性能。因此,微软建议使用Check限制而不是其他的方式来限制域的完整性。
如果应聘者能够正确地回答这个问题,那么他的机会就非常大了,因为这表明他们具有使用存储过程的经验。
返回参数总是由存储过程返回,它用来表示存储过程是成功还是失败。返回参数总是INT数据类型。
OUTPUT参数明确要求由开发人员来指定,它可以返回其他类型的数据,例如字符型和数值型的值。(可以用作输出参数的数据类型是有一些限制的。)您可以在一个存储过程里使用多个OUTPUT参数,而您只能够使用一个返回参数。
什么是相关子查询?如何使用这些查询?
经验更加丰富的开发人员将能够准确地描述这种类型的查询。
相关子查询是一种包含子查询的特殊类型的查询。查询里包含的子查询会真正请求外部查询的值,从而形成一个类似于循环的状况。
SQL面试题(6)
原表:
courseid coursename score
-------------------------------------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
-------------------------------------
为了便于阅读,查询此表后的结果显式如下(及格分数为60):
courseid coursename score mark
---------------------------------------------------
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
---------------------------------------------------
写出此查询语句
ORACLE : select courseid, coursename ,score ,decode(sign(score-60),-1,'fail','pass') as mark from course
(DECODE函数是ORACLE PL/SQL是功能强大的函数之一,目前还只有ORACLE公司的SQL提供了此函数)