# 进程类别
交互式进程(I/O)
批处理进程(CPU)
实时进程(Real-time)
CPU密集型:分配时间片长,优先级低
IO密集型:时间片短,优先级高
Linux优先级:priority
实时优先级:1-99,数字越小,优先级越低;
静态优先级:100-139,数字越小,优先级越高; nice值得范围-20~19分别对应于优先级得100~139
实时优先级比静态优先级高
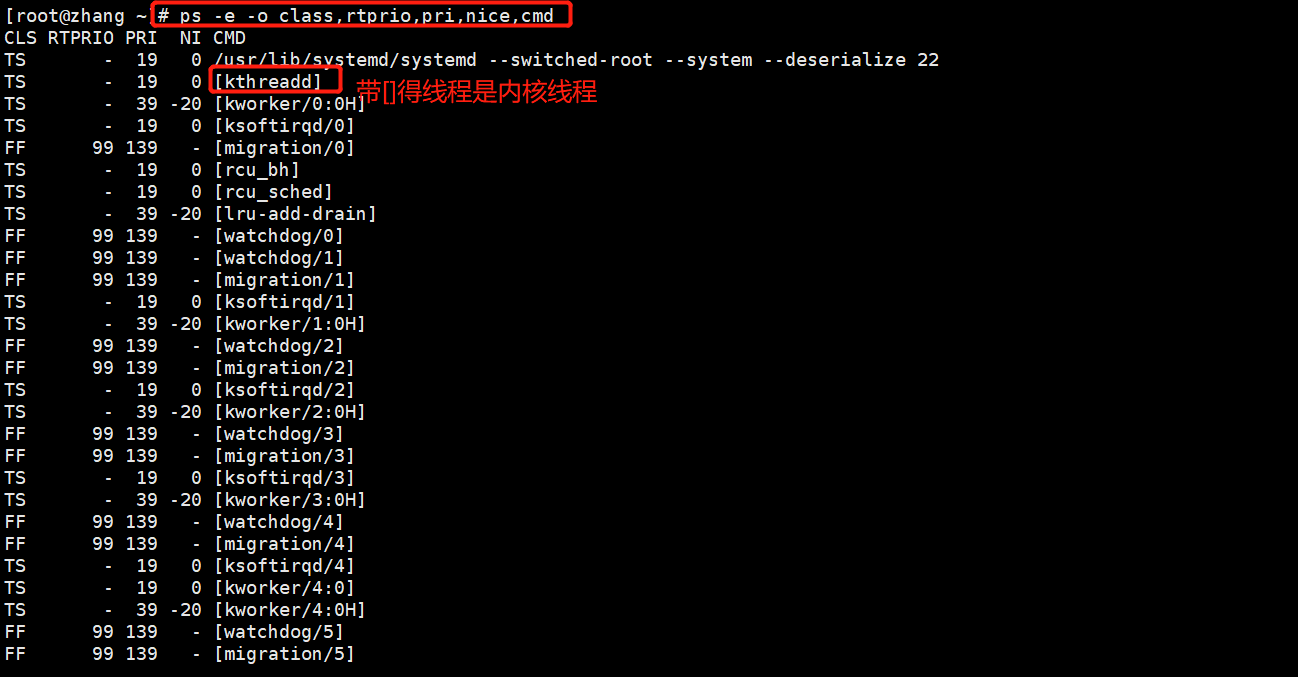
ps -e -o class,rtprio,pri,nice,cmd # 如下图1
-e:显示和终端相关和无关的进程
-o:表示自定义显示的字段
class:调度类别
rptprio:实时优先级
pri:优先级(静态优先级)
nice:nice值,调整静态优先级的
cmd:启动进程的命令
调度类别:
实时进程:
SCHED_FIFO:First In First Out
SCHED_RR:Round Robin
SCHED_Other:用来调度100~139之间的进程
动态优先级:
dynamic prioruty = max(100,min(static priority - bonus + 5,139))
bonus:0~10
手动调整优先级:
100~139:nice
nice:
nice N COMMNAD
renice:
renice -n # PID
chrt -p [prio] PID # 也可以调整用户空间的100~139进程的优先级
1~99:
chrt [options] -p [prio] pid
options:
-f:FIFO
-r:Round Robin
-p: priority,其后加上优先级参数
pid:代表是哪一个进程
chrt -f -p [prio] PID
chrt -r -p [prio] PID
chrt -f -p [prio] COMMAND # 启动一个进程,直接指定为实时优先级
图1:
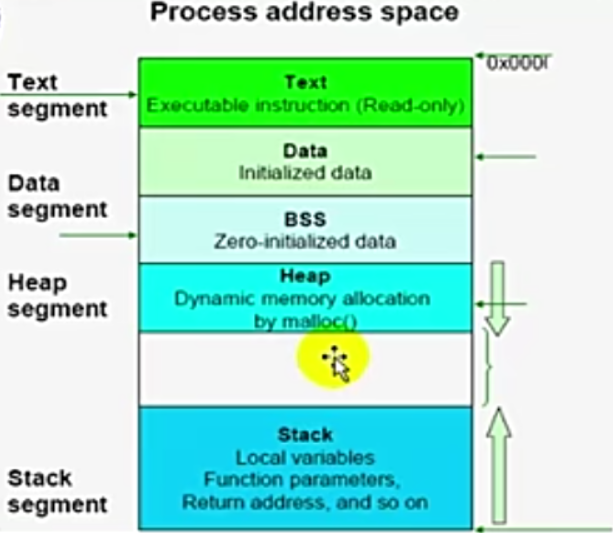
进程的格式:# 如下图2
一个进程的内部,在他的线性地址空间里,从0x000到0xfff,有一段地址空间是不能使用的(32位的系统上,线性地址空间为4G,有1G是留给内核),在进程自己的地址空间当中,从低地址开始,放的是:
TEXT:代码段(指令区),只读的;
DATA:有了初始值的变量;
BSS:初始化为零的变量;
HEAP(堆):打开的文件内容都在堆上;
Stack(栈):函数的参数、函数的返回地址及局部变量、本地变量都在栈当中;# 程序执行过程中产生的变量都在栈上;
栈是从高地址空间向低地址空间增长的,而堆是从低地址空间向高地址空间增长的
图2:
CPU调优
cpu访问自己的内存需要三个时钟周期,1、CPU通知内存控制器,2、内控制器寻址,3、CPU取内存中的数据和指令;访问其它内存需要六个时钟周期,首先访问自己的内存控制器需要一个,自己的内存控制器和对方内存控制器的通信需要三个,对方控制器再继续寻址和读取数据和指令,需要两个时钟周期。。。
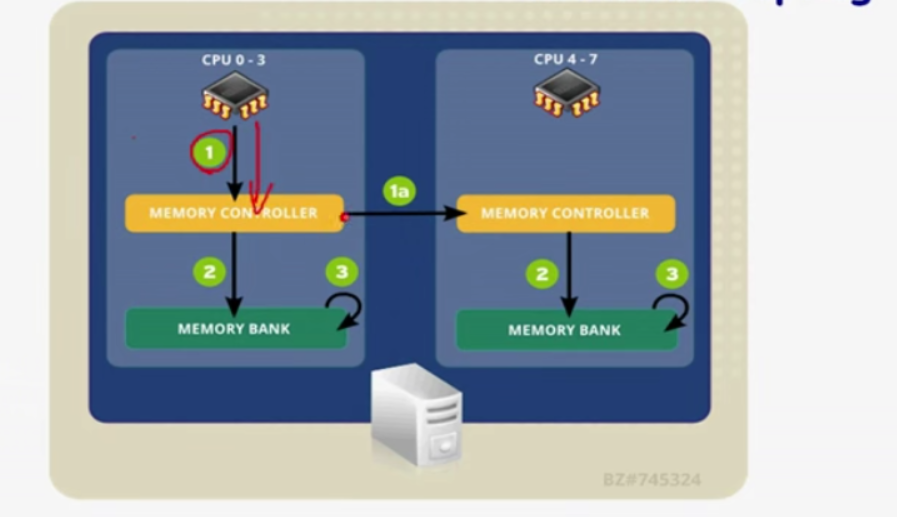
CPU affinity:CPU的姻亲关系,指的是某些进程再启动以后绑定到指定的CPU上或CPU核心上运行,不再交叉访问内存。
# report memory and swap space utilization statistics
sar -r [interval] [count]
# rate of change in memory
sar -R [interval] [count] # report memory statistics
# report swapping statistics
sar -W [interval] [count]
# ALL IO
sar -B [interval] [count] # report paging statistics
sar -q # rpm -qf `which sar` ==> sysstat模块==>rpm -qf sysstat ==> yum install -y systat
sar -q 1 # 每隔一秒钟查看一次上下文切换(进程切换)的平均次数,如果切换次数多,说明起的进程过多;如果中断的次数过多,说明外部硬件繁忙。
top
w
uptime
vmstat -n [interval] [count]
vmstat 1 5
pmstat 1 2
sar -P 1 2 # 每隔2s显示一次第1号CPU的使用率
iostat -c 1 6
cat /proc/stat # 查看每一个CPU的使用率
dstat
--top-cpu # 查看哪个进程最消耗CPU
--top-mem # 查看哪个进程最消耗内存
--top-io # 查看哪个进程的IO量最大
-c # 查看CPU使用率
taskset -p -c 0 16386 # 将16386号进程绑定到0号进程上。-p必须再-c前面
一般来讲,用户空间和内核空间CPU的使用率百分比为:7:3,且CPU的使用率不要长期超过80%,意味着系统比较繁忙,将来有可能会挂掉。
内存常见调优参数
内存子系统组件
slab allocator
buddy system
kswapd
pdflush
mmu
# 启用大页面(enable hugepages)
1. 在/etc/sysctl.conf文件中,添加参数vm.nr_hugepages = n
或者:
2.在操作系统启动的时候,向内核传送参数 hugepages = n
# Configure hugetlbfs if needed by application
mmap system call requires that hugetlbfs is mounted
mkdir /hugepages
mount -t hugetlbfs none /hugepages # none 字段指的是挂载的设备,不用指定任何的设备类型
shmat and shmget system calls do not require hugetlbfs
strace命令:
strace COMMAND: 查看命令的syscall
strace -p PID:查看已经启动进程的syscall
-c:只输出其概括信息;
-o:将追踪结果保存至文件中,以供后续分析使用;
1.降低微型内存对象的系统开销,使用slab
cat /proc/slabinfo
slabtop
2.缩减慢速子系统的服务时间
使用buffer cache 缓存文件元数据;
使用page cache缓存DISK IO;
使用share memory完成进程间通信;
使用buffer cache、arp cache和connection tracking 提升网络IO性能;
vfs_cache_pressure:
0:不回收dentries和inodes;
1-99:倾向于不回收;
100:倾向性与page cache和swap cache相同;
100+:倾向于回收;
进程间通信管理类命令:
ipcs
ipcsrm
shm:
shmani:系统级别,所允许使用的共享内存段上限;
shmall:系统级别,能够为共享内存分配使用的最大页面数;
shmmax:单个共享内存段的上限;
messages:
msgmnb:单个消息队列的上限,单位为字节;
msgmni:系统级别,消息队列个数上限;
msgmax:单个消息大小的上限,单位为字节;
手动清写脏缓存和缓存:
sync
echo s > /proc/sysrq-trigger
回收清理页:
echo 3 > /proc/sys/vm/drop_caches
1:释放缓存页(pagecache)
2:释放dentries(目录项)和inodes
3:释放缓存页(pagecache)、dentries(目录项)、inodes。
echo $$ :用于打印当前进程的进程号;
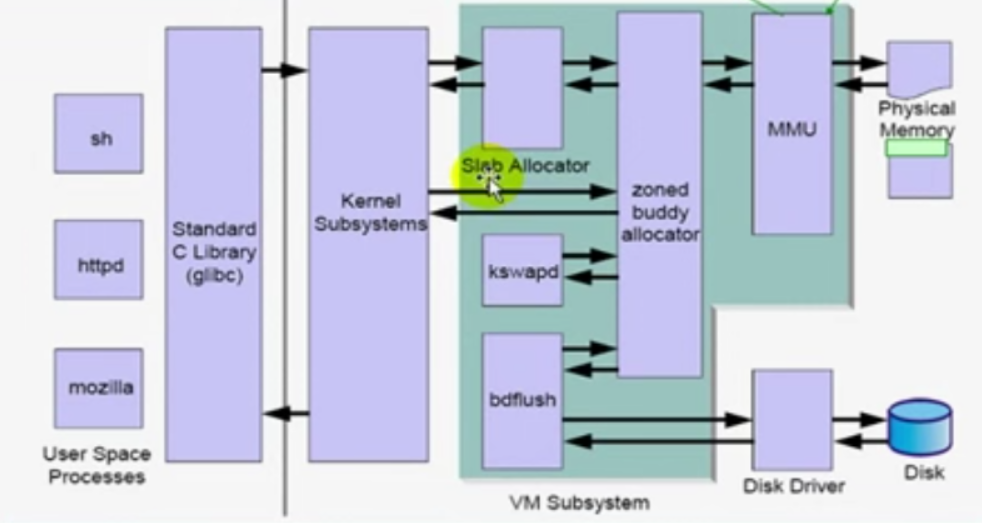
slab allocator和buddy system完成内存的申请、分配和释放,MMU将线性地址映射为物理地址,bdflush每隔一段时间清写Physical Memory中的数据到Disk,kswapd监控页面到交换内存的换进换出。我们调控参数就是为了控制子系统工作。包括:
HugePage:TLB
IPC:
pdflush
slab
swap
oom
yum install -y perf
perf stat
Task-clock-msecs:CPU利用率,该值高,说明程序的多数时间花费在CPU计算上而非IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
Cachae-misses:程序运行过程中总体的cache利用情况,如果改制过高,说明程序的cache利用不好。
CPU-migrations:表示进程ti运行过程中发生了多少次CPU迁移,即被调度器从一个CPU转移到另一个CPU上运行。
Cycles:处理器时钟,一条机器指令可能需要多少cycles。
Instructions:机器指令数目。
IPC:是Instructions/Cycles的比值,该值越大越好,说明程序充分利用了处理器的特性。
Cache-references:cache命中的次数
Cache-misses:cache失效的次数
通过指定-e选项,可以改变perf stat的缺省事件(可以通过perf list 来查看),可能会使用-e选项来查看感兴趣的特殊的事件。
perf Top
使用perf stat的时候,往往您已经有一个调优的目标,也有些时候,您只是发现系统性能无端下降,并不清楚究竟哪个进程成为了贪吃的hog,此时需要一个类似top的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的家伙,类似法制节目中办案民警常常做的那样,通过查看监控录像从茫茫人海中找到行为古怪的那些人,而不是到大街上抓住每一个人来审问。
Perf Top用于实时显示当前系统的性能统计信息,该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最好是的内核函数或某个用户进程。
使用 perf record,解读report
使用 top 和stat之后,您可能已经大致有数了,要进一步分析,便需要一些粒度更细的信息,比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简,那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用perf record 记录单个函数级别的统计信息,并使用perf report来显示统计结果。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行事件的0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高0.1%。
Disk:
IO Scheduler:
CFQ:完全公平队列,
deadline:最后期限调度
anticipatory:期望,读这个数据之后,还会读这个数据之后的其它数据,会等待几毫秒,这种等待很可能是白费的,比较适合顺序读写的场景当中。
NOOP
# 磁盘的IO调度器,可以根据需要调节
/sys/block/<device>/queue/scheduler
Memory:
MMU:memory management unit ,是一个硬件芯片。
TLB:缓存MMU转换的结果,为了提高TLB的性能,可以使用大内存页。是在硬件中实现的缓存芯片
vm.swapiness={0..100}:我们知道系统使用交换内存,会降低系统性能,但是当我们内存不够用的,系统也不能说就不运行了,这个时候我们可以使用交换内存,而swapiness可以控制是否在多大程度上倾向将page cache 交换至swap. 这个值越大,使用的倾向性越大。vm.swapiness=0表示物理内存够用时,不使用交换内存。
overcommit_memory:过量使用
0:启发式过量
1:总是过量
2:可以超出指定百分比
RAM,swap
overcommit_ratio:
当overcommit_memory=2时,overcommit_ratio=50意味着什么呢?
表示:swap+RAM*ratio
例如:
swap:4G
RAM:8G
可以使用的内存空间为:4+8*50%=8G
充分使用物理内存:
1.swap跟RAM一样大;swapiness=0(尽量不使用swap)
2. overcommit_memory=2,overcommit_ratio=100;
这样将使用所有的swap和物理内存(swap+ram),会导致系统性能下降,如何提升呢?我们可以再加上 vm.swapiness=0,意味着尽量不使用swap,这样ram(物理内存)就能够得到充分利用。
cd /proc/sys/net/ipv4
tcp_max_tw_buckets:为什么只能调大,不能调小?此参数用于保存当前系统上处于timewait状态的会话的个数或者叫连接的个数,在断开TCP连接的时候,服务器再没有收到断开的请求之前是不可能被清除出去的,不能被清除出去,就只能持有着,只要tw会话不能被断开或者超时,就意味着tw_buckets就不能腾出来,不能腾出来,其它的断开连接的会话就不能进入TW程序,如果将tcp_max_tw_buckets参数调小,会导致同时持有TW状态会话的连接个数更少,所以增大才有意义,调小会使系统上同时持有多的tw状态的连接个数更小。
tcp_mem:tcp套接字缓冲区大小,包括接收缓存和发送缓存
tcp_rmem:TCP套接字的接收缓冲区大小
tcp_wmem:TCP套接字的发送(写)缓冲区大小
tcp_fin_timeout:定义fin状态标志超时时长
cd /proc/sys/net/core
# 核心缓冲
rmem_max:
wmem_max:
rmem_default:
wmem_default:
IPC:进程间通信的三种方式
消息(message)
可以调节的参数:
msgmni
msgmax
msgmnb
共享内存(shm:shared memory)
可以调节的参数:
shmall
shmmax
shmmni
somephore:信号
cpu和内存监控的命令:
sar,dstat,vmstat,mpstat,iostat,top,free,iotop,uptime,cat /proc/meminfo,ss,netstat,lsof(查看进程打开的文件),time(评估一个命令的运行时长,如下图1), perf(评估整个命令的执行情况,perf stat,perf top),strace(追踪每一个命令产生的系统调用情况)
blktrace,blkparse,btt
对文件系统进行压力测试的工具:
dd,iozone,io-stress,fio(功能及其强大)
OS可以说是进程控制器,OS负责协调运行在其上进程的资源的申请。假如我们的CPU只有一颗,一个进程正在运行,其它的进程就只能等待。
IO端口是让CPU跟IO设备实现数据交换的,而中断是让IO设备通知CPU,它有一个紧急事件需要处理。CPU利用可编程中断控制器让每一个IO设备注册使用一个中断线上的中断设备号的。
图1:
虚拟化技术
Intel和AMD分别通过EPT(Extended Page Tables)和NPT(Nested Page Tables)为虚拟化应用提升影子MMU的性能,并通过标记(tagged)TLB来避免虚拟机切换时频繁清写(flush)TLB以提高TLB缓存的命中率。