一. 字符编码
核心:以什么编码写的存入硬盘,就以什么编码取出
1.1 内存使用的是unicode编码,全是两个字节提高传输速度..一般都是使用utf-8的万国编码,优点是节省空间.缺点是运行速度相对较慢
1.2 数据最先产生在内存中的 是unicode格式,想要传输就要转化成二进制的bytes格式
1 #unicode----->encode(utf-8)------>bytes 2 拿到bytes,就可以往文件内存放或者基于网络传输 3 #bytes------>decode(gbk)------->unicode
1.3 文件-gbk/utf-8=文件.encode('gbk/utf-8') 这是指定文件编码类型 或者转换 编码.encode将文件编码成某种类型
文件-gbk/utf-8=文件.decode('gbk/utf-8') 这是指定文件编码类型 或者转换 解码.decode 将文件解码成某种类型
1.4 了解 python3里面默认是utf-8来编写和读取文件 utf-8是Unicode万国编码的转变形式
二.文件处理
2.1 关键词 和with 语法
open --打开文件 encoding='utf-8'--打开文件的编码格式 close--关闭文件夹 read--读取文件内容 readline()--逐行读取 (print自带换行符) end=' '可以去除 readlines---每一行都读进来
with open as read_f with语法可以打开多个文件
2.1.1
文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
2.2
上下文管理 with
with open ('aaa.py','r',encoding='utf-8') as read_f,
open('aaa_new.py','w',encoding='utf-8')as writ_f:
date=read_f.read()
write_f.wriet(data)
2.3文件打开模式
f=open('r')=只读模式 f=open('r+')=读写模式(光标在文件末尾)文件不存在就会报错
f=open('w')=只写模式,文件不存在创建新的文件,文件存在则清空(不能读只能写)
f=open('w+')=创建文件读写 想当于w模式加了r的模式
f=open('a')=只追加写模式,文件不存在 则报错,文件存在会在末尾追加
f=open('a+')=在文件末尾读写 直接添加内容到文件尾部
2.4文件内容的修改
for line in f:
print(line,end="") 文件再大 同时只取一行内容
总结性代码
那不了解就抄5遍
上下文管理
with open('aaaa.py','r',encoding='utf-8') as read_f,
open('aaaa_new.py','w',encoding='utf-8') as write_f:
data=read_f.read()
write_f.write(data)
循环取文件每一行内容
with open('a.txt','r',encoding='utf-8') as f:
while True:
line=f.readline()
if not line:break
print(line,end='')
lines=f.readlines() #只适用于小文件
print(lines)
data=f.read()
print(type(data))
for line in f: #推荐使用
print(line,end='')
文件的修改
方式一:只适用于小文件
import os
with open('a.txt','r',encoding='utf-8') as read_f,
open('a.txt.swap','w',encoding='utf-8') as write_f:
data=read_f.read()
write_f.write(data.replace('alex_SB','alex_BSB'))
os.remove('a.txt')
os.rename('a.txt.swap','a.txt')
方式二:
import os
with open('a.txt','r',encoding='utf-8') as read_f,
open('a.txt.swap','w',encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('alex_BSB','BB_alex_SB'))
os.remove('a.txt')
os.rename('a.txt.swap','a.txt')
三.函数的参数 和 返回值(return)
3.1为什么要有函数? 减少带码冗余,增强代码可读性
函数分类? 内置函数的自定义函数 自定义函数以def开头
函数的调用? 调用函数以函数的名称加()来调用
函数初始详解


# name='alex' #字符串 # #计算字符串长度 # # lemgth=len(name) # # print(lemgth) # #计算字符串长度 # length=0 # for char in name: # length+=1 # print(length) # # print(len('name'))#内置函数len # # #函数书写规定 def 加函数名 加空格 加冒号 #函数名要有表达的意义 # def mylen():#把一下代码装到一个叫做mylen()里面 #=叫做定义函数 # name = 'alex' # length=0 # for char in name: # length += 1 # print(length) # mylen() #函数名加()等于执行括号内的缩进代码 =调用 # def mylen(): # name='wupeiqi' # count=0 # for i in name: # count+=1 # print(count) # mylen() #函数名加()等于执行括号内的缩进代码 =函数的调用 # def my_print(): # print( # ''' # name:alex # age:83 # sex:不详 # ''') # #调用就可以 减少代码冗余 # my_print() # my_print() # my_print() # length=len('alex') # print('the length :',length) # # # # # def mylen():#把一下代码装到一个叫做mylen()里面 #=叫做定义函数 # name = 'alex' # length=0 # for char in name: # length += 1 # #print('the length',length) # return length # returen 关键字返回值 相当于执行完之后打印结果返回到函数名的()括号内 # # 在外部直接调用打印结果 不影响原函数 # # # length=mylen() # print(length) #结果不要打印 要返回 # # def hahaha(): # return 111 #只管返回的时 # # # a=hahaha()#定义变量接收 # print(a) # # def hahaha(): # print(123) # return 111 # return 456 #永远都不会被执行 遇到第一个return 函数就执行结束 # # a=hahaha() #有return 只接受returen 的返回值 不管函数内部的打印 # print('a:',a) #只要没有return 就是返回None #return可以返回任意类型 字典 列表 字符串 数字 等 #返回一个元组 # def hahaha(): # return (456,123) # # a=hahaha() # print('a:',a[1],a[0]) # # #返回一个列表 # def hahaha(): # return ([456],[123]) # # a=hahaha() # print('a:',a[1],a[0]) #返回多个值 : 多个返回值以逗号隔开以元组的形式返回 # def hahaha(): # return 111,{456,123} #python 解释器里 加逗号, 就是自动组成元组 # # a=hahaha() # print('a:',a[1],a[0]) # def hahaha(): # print(111) # return #后面没有值 返回的都是none # print(222) # # a=hahaha() # print('a:',a) # def my_max(): # a=111 # b=222 # if a>b: # return a # else: # return b # # a=my_max() #这里这个a 只跟return返回的值有关 跟函数体的a 没有任何关系 # print('a:',a) #返回一个整除3的值 # def find(): # l=[1,2,3,4,5,6] # for i in l: # if i%3==0: # return i # # num=find() # print(num) #返回多个值 添加到新列表内 # def find(): # l=[1,2,3,4,5,6] # new_l=[] # for i in l: # if i%3==0: # new_l.append(i) # return new_l # # num=find() # print(num) #接收返回值 1.一个值接收 #2. 多个变量接收:返回多少个值就用几个变量去接收 只能多不能少 #拆包 解包 当你的程序有多个返回值的时候 # def fun(): # a=1 # if a>5: # return 1,2,3 # # a,b,c=fun() # print(a,b,c) # # def mylen(name):#name参数 都是形参 形式参数 # print(name) # length=0 # for char in name: # length+=1 # print(length) # # mylen('alex')#'alex'参数 站在函数调用的角度上:所有参数都叫做实参 # #实际参数 # s2='wupeiqi' #直接定义实参 然后传进去 # mylen(s2) # # #格式化传参 一个参数 # def welcome(): # print('welcome,%s'%name) # # welcome('alex') # welcome('nezha') #replace('','') 替换老的新的 #传多个值%格式化拼接 个数必须 对 不能少 # def welcome(name1,naem2): # print('welcome,%s,%s'%(name1,name2)) # # # welcome('alex','nezha') #传什么类型 都可以 # # welcome({'a':'b'},'nezha') # welcome(['alex'],'nezha')
3.2返回值可以返回一个值和多个值 和任意类型的值 return就是返回需要的那个值 定义完函数之后在末尾添加
作用就是结束整个函数的运行
看代码 def ret_demo1(): '''返回多个值''' return 1,2,3,4 def ret_demo2(): '''返回多个任意类型的值''' return 1,['a','b'],3,4 ret1 = ret_demo1() print(ret1) ret2 = ret_demo2() print(ret2)
没有返回值
不写return的情况下,会默认返回一个None:我们写的第一个函数,就没有写return,这就是没有返回值的一种情况
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 str_len = mylen() #因为没有返回值,此时的str_len为None print('str_len : %s'%str_len) 不写return
只写return,后面不写其他内容,也会返回None,既然没有要返回的值,完全可以不写return,为什么还要写个return呢?这里我们要说一下return的其他用法,就是一旦遇到return,结束整个函数。
def ret_demo(): print(111) return print(222) ret = ret_demo() print(ret) 只写return
return None:和上面的两种情况一样,我们一般不这样写。
返回一个值
刚刚我们已经写过一个返回一个值的情况,只需在return后面写上要返回的内容即可。
注意:return和返回值之间要有空格,可以返回任意数据类型的值
返回多个值
可以返回任意多个、任意数据类型的值
返回的多个值会被组织成元组被返回,也可以用多个值来接收
原因:
>>> 1,2 #python中把用逗号分割的多个值就认为是一个元组。 (1, 2) >>> 1,2,3,4 (1, 2, 3, 4) >>> (1,2,3,4) (1, 2, 3, 4)
序列的解压:
#序列解压一 >>> a,b,c,d = (1,2,3,4) >>> a >>> b >>> c >>> d #序列解压二 >>> a,_,_,d=(1,2,3,4) >>> a >>> d >>> a,*_=(1,2,3,4) >>> *_,d=(1,2,3,4) >>> a >>> d #也适用于字符串、列表、字典、集合 >>> a,b = {'name':'eva','age':18} >>> a 'name' >>> b 'age' 序列解压扩展
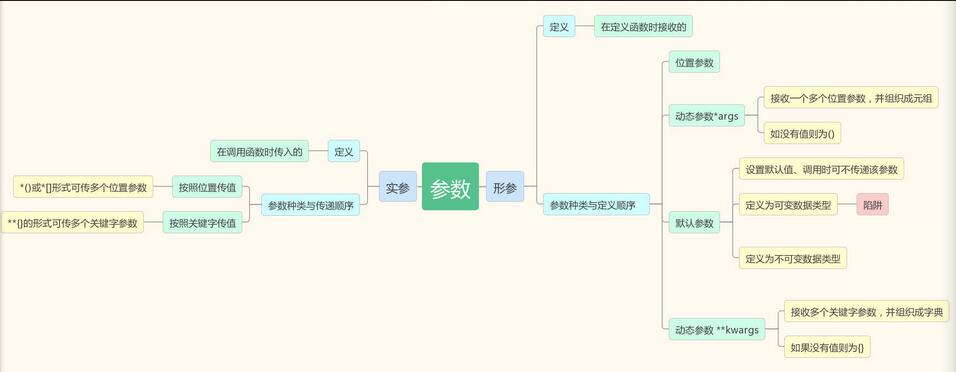
3.3函数的参数
参数分为形参和实参
3.3.1形参就是def后面 跟的参数 分为位置参数 默认参数 和动态参数
位置参数 位置参数必须传值
默认参数 默认参数可以不传值
1.正常使用
使用方法
为什么要有默认参数:将变化比较小的值设置成默认参数
默认参数 不懂写5遍 脑子笨最好的办法 def stu_info(name,sex = "male"): """打印学生信息函数,由于班中大部分学生都是男生, 所以设置默认参数sex的默认值为'male' """ print(name,sex) stu_info('alex') stu_info('eva','female')
参数陷阱:默认参数是一个可变数据类型
def defult_param(a,l = []): l.append(a) print(l) defult_param('alex') defult_param('egon')
动态参数
动态参数分为两种 *args 分解元组 **kwargs分解字典 以下看代码
老规矩 不懂就是抄就抄 def fun2(*args): print(args) t=(1,2,3,4) fun2(*t) **kwarg def stu_info(**kwargs): print(kwargs) print(kwargs['name'],kwargs['sex']) stu_info(name = 'alex',sex = 'male')
位置、关键字形式混着用
混用正确用法
问题一:位置参数必须在关键字参数的前面
问题二:对于一个形参只能赋值一次
站在形参角度
位置参数必须传值
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max #调用mymax不传递参数 ma = mymax() print(ma) #结果 TypeError: mymax() missing 2 required positional arguments: 'x' and 'y' 位置参数必须传参
3.4 实参 :就是实即要传入的参数==传参
也是分为两种方式 位置传参和关键字传参 看代码
位置参数 老规矩 def mymax(x,y): #此时x=10,y=20 the_max = x if x > y else y return the_max ma = mymax(10,20) print(ma) 关键字传参 def mymax(x,y): #此时x = 20,y = 10 print(x,y) the_max = x if x > y else y return the_max ma = mymax(y = 10,x = 20) print(ma)
参数详解
详解参数 def func(a,b):#站在函数定义的角度上:位置参数 print(a,b) #站在调用函数的角度上 func(1,2) #按照位置传参 func(b=1,a=2)#按照关键字传参 func(1,b=2) #混用 顺序不能变 必须先按照位置传参 后按照关键字传参 定义一个函数, 接收两个参数(列表),返回长度比较长的那个列表 def fun(a,b): if len(a)>len(b): return a else: return b c=fun([133],[464665]) print(c) #站在定义函数的角度上--默认参数 def welcome(name,sex='male'):#sex 默认参数 print('welcome,%s,sex:%s'%(name,sex)) welcome('黄中山') welcome('曹海娇') welcome('陆续山','female') 默认参数 是可以不传的参数 如果不传默认就是设置的默认值,如果传就是传入的值 默认的值在定义阶段就确定了 def age(age,my_age=18): if age > my_age: return False else: return True 默认参数的陷阱 专门针对可变的数据类型 始终只有一个容器 如果是可变类型 就会一直添加 def demo3(a=[]): a.append(1) print(a) demo3() demo3() demo3() 不可变类型不影响 def demo3(a=[]): a.append(1) print(a) demo3([]) demo3([]) demo3([]) 面试题 def demo3(a=[]): a.append(123) print(a) demo3()#有了123 demo3([])#用自己的列表 demo3()#原有的123上又加上了123 动态参数 def my_sum(a,b,c): sum_ret=a+b+c return sum_ret print(my_sum(1,2,3)) def my_sum(*args): print(args) my_sum(1,2,'alex',[1,2]) 传参 计算 def my_sum(*args): count_sum=0 for i in args: count_sum+=i return count_sum print(my_sum(3,0,2,1,2,3)) l=[1,2,3,4] my_sum(*l) 动态参数 站在函数定义的角度上: *做聚合用,将一个一个的参数组合成一个元组 站在函数的调用的角度上:*做打散用,将一个列表或元组打散成多个参数 *一个星 只针对位置传参 不能完成按关键字传参 关于**kwargs ,接收按关键字传递过来的参数,组成一个字典 def demo4(**kwargs):#专门接受按关键字传参 打印出来的是字典类型 print(kwargs) demo4(a=1,b=2,c=3) d={'a':1,'b':2,'c':3} demo4(**d) 站在传参角度:按位置 按关键字 规定按位置 关键字 顺序 def demo5(*args,**kwargs): print(args) print(kwargs) demo5(123,a=10,b=20)#必须按照 def func(位置参数1,位置参数2,*args,默认参数=10,**kwargs): print(位置参数1,位置参数2) print(默认参数) print(args) print(kwargs) func(1,2,3,4,5,默认参数='hahaha',a=10,b=20) func(1,2,3,4,5,a=10,b=20) def f(*args,**kwargs): #这里接收的参数个数不确定的时候 pass f()
补充几点
函数的嵌套 和 函数名
函数的嵌套就是为了保护 内部函数不被外部所调用和修改() 但是可以根据动态参数 *args和**kwargs 去传参
函数嵌套 7月28日 def animal(): def tiger(): print('bark') print('eat') tiger() animal() #函数嵌套使用 def f1(): print(a) #无法获取f2的a的值,注意执行顺序 print('f1') def f2(): a = 10 f1() f2()
函数名的本质就是内存地址 下面的代码借用他人的
#!/usr/bin/env python #_*_coding:utf-8_*_ def func(): print('func') print(func) #函数func内存地址 f = func #就是函数的内存地址 print(f) #函数func内存地址 f() #执行代码 ############# l = [f] #还是函数内存地址 print(l) l[0] == f #用索引取值 l[0]() #可以用作函数的参数 def func(): print('func') def func2(f): print(f) #func的内存地址 f() #执行func函数 print('func2') func2(func) #可以作为函数的返回值 def func(): print('func') def func2(f): #1 接收func函数的内存地址 print('func2') return f #2 返回给fu函数func函数的内存地址 fu = func2(func) fu() #3 执行函数func #如果我想在全局使用内部的函数
四.作用域 闭包 局部变量和全局变量
4.1 作用域的定义和作用
分为内置函数空间..在哪里都可以用
全局函数空间..他不能用局部的但是局部的可以用他的
局部函数空间(自定义函数) 在自己定义的空间内可以用 (注意一点就是 它只在调用的时候加载)
爷爷 爸爸 儿子 =内置 全局 局部 就是这个作用域最好的解释!!!
全局作用域:全局命名空间、内置命名空间
局部作用域:局部命名空间
站在全局看:
使用名字:name=123
如果全局有:用全局的
如果全局没有:用内置的(这个内置是python自带的函数)
为什么要有作用域的概念:
为了函数内的变量不会影响到全局
不懂就抄 #全局命名空间 a = 5 b = 8 #局部命名空间(函数) def my_max(): c = a if a > b else b return c m = my_max() print(m)
作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变
白话就是:定义一个函数可以使用的范围
作用:作用域:(老师总结的 太详细了 )
1.小范围的可以用大范围的
2.但是大范围的不能用小范围的
3.范围从大到小
4.在小范围内,如果要用一个变量,是当前这个小范围有的,就用自己的
5.如果在小范围内没有,就用上一级的,上一级没有就用上上一级的,以此类推。
6.如果都没有,报错
global 的作用
a=789 b=159 def alex(*args,**kwargs): def egon(*args,**kwargs): global a a = 999 global b b = 888 print(a,b) egon() alex()
4.2闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包闭包
4.2.1闭包函数的定义和解释
内部函数,包含了对外部作用域中变量的引用
闭包
1.闭 内部的函数
2.包 包含了对外部函数作用域中变量的引用
3.内部函数调用全局的变量和return一个返回值
4.函数名可以当做函数的参数
5.闭包函数多用于装饰器中(自己目前的理解)
#闭包的常用形式
def hei():
x = 20
def inner():
print(x) #局部的
return inner
如果在一个内部函数里:inner()就是这个内部函数,
对在外部作用域(但不是在全局作用域)的变量进行引用:x就是被引用的变量,x在外部作用域hei()里面,但不在全局作用域里。
则这个内部函数inner()就是一个闭包。
五.装饰器(各种装饰器/带参数的装饰器)和语法糖(重点)
详见博客http://www.cnblogs.com/zgd1234/p/7463861.html
总结自己的理解
装饰器=用之前先写好模板放在那里 然后一句一句的写原函数 最后想办法把两者加起来
装饰器本质就是能更好的去调用原函数的功能和使用功能
5.1装饰器是什么?
装饰器也是一个函数
字面意思:就是装饰某件东西让其变得高雅.....其实就是装饰闭包函数
真是意思:为其他函数加上其他新功能
5.2装饰器原则和方式
原则:对扩展是开放的 对修改是封闭的,在不改变原代码和原函数的调用方式的情况下给原函数加上新的功能
装饰器必须放到被装饰的函数上边,并且独占一行;多个装饰器下 ,按照先下后上执行。
5.3装饰固定代码(想办法记住 最贱的办法就是抄 印到脑子里 10遍)
代码不懂就敲 一言不合就5遍 def timer(func): def inner(*args,**kwargs): '''执行函数之前要做的''' re = func(*args,**kwargs) '''执行函数之后要做的''' return re return inner 2.默写代码 import time def timer(func): def inner(*args,**kwargs): start = time.time() re = func(*args,**kwargs) print(time.time() - start) return re return inner @timer #==> func2 = timer(func2) def func2(a): print('in func2 and get a:%s'%(a)) return 'fun2 over'
5.4带参数的装饰器(白话就是开关:想用就用不用就关) 和多个修饰器装饰一个函数(这块学的太渣渣.只能把代码放上自己慢慢理解了)
#带参数的装饰器 开关 # F = True F = False def outer(flag): def wrapper(func): def inner(*args,**kwargs): if flag: print('before') ret = func(*args,**kwargs) print('after') else: ret = func(*args, **kwargs) return ret return inner return wrapper @outer(F) #-->@wrapper -->hahaha = wrapper(hahaha) #-->hahaha == inner def hahaha(): print('hahaha') @outer(F) #shuangww = outer(shuangww) def shuangww(): print('shuangwaiwai') shuangww() hahaha()
#多个装饰器装饰一个函数 def qqxing(func): #func = pipixia_inner def qqxing_inner(*args,**kwargs): print('in qqxing:before') ret = func(*args,**kwargs) #pipixia_inner print('in qqxing:after') return ret return qqxing_inner def pipixia(func): #dapangxie def pipixia_inner(*args,**kwargs): print('in pipixia:before') ret = func(*args,**kwargs) #dapangxie print('in pipixia:after') return ret return pipixia_inner #qqxing(pipixia_inner) -->dapangxie = qqxing_inner() @qqxing #dapangxie = qqxing(dapangxie) -->dapangxie = qqxing(pipixia(dapangxie)) --> @pipixia #dapangxie = pipixia(dapangxie) def dapangxie(): print("饿了么") dapangxie() #dapangxie = pipixia(dapangxie) #dapangxie = qqxing(dapangxie) -->dapangxie = qqxing(pipixia(dapangxie)) #pipixia(dapangxie) == >pipixia_inner #qqxing(pipixia_inner) = qqxing_inner #dapangxie() ==> qqxing_inner() #应用场景 #func #1.计算func的执行时间 @timmer #1.登录认证 #@auth #@auth #@timmer #func #解耦 尽量的让代码分离。小功能之间的分离 #解耦的目的 提高代码的重用性