Requests库
7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各种方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
request库的7个方法除了request()方法外,其余6个都是由request()方法封装而成的【其他方法都是通过调用request()方法来实现的】,而我们最主要使用的还是get方法。 |
Requests库的get()方法
r = requests.get(url,params=None,**kwargs)
- url :拟获取页面的url链接
- params :url中的额外参数,字典或字节流格式,可选
- **kwargs:12个控制访问的参数
Requests库的两个重要对象
Response对象
Response对象返回包含服务器返回的所有信息,也包含请求的Request信息
Response对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码) |
| r.content | HTTP响应内容的二进制形式 |
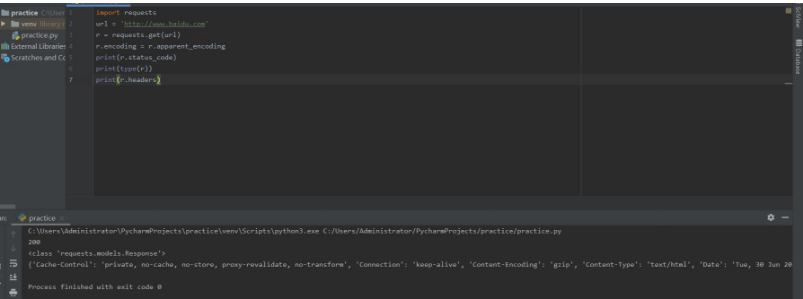 |
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()#如果状态码200
r.encoding = r.apparent_enconding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
演示结果
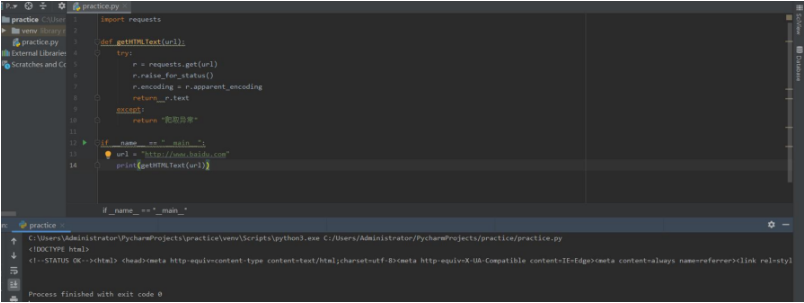
Requests库的post方法
演示代码
import requests
payload = {'key1':'value1','key2':'value2'}
r = requests.post('http://httpbin.org/post',data = payload)
r.encoding = r.apparent.encoding
print(r.text)
演示结果
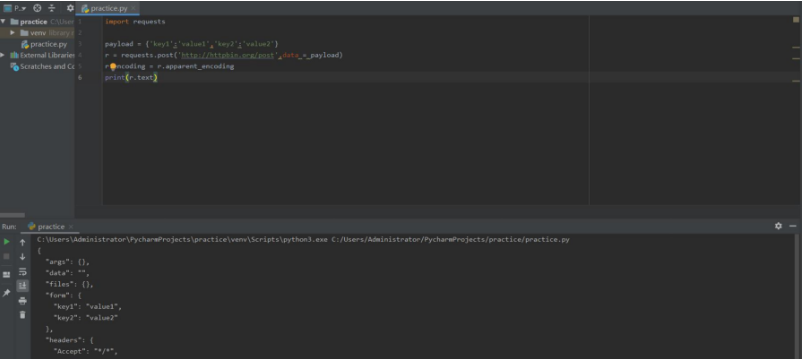
Requests库的request方法
requests.request(method,url,**kwargs)
- method :请求方式,对应
get/put/post等7种 - url :拟获取页面的
url链接 - kwargs:控制访问的参数,共13个
*kwargs:控制访问的参数,均为可选项
| 参数 | 说明 |
|---|---|
| params | 字典或字节序列,作为参数增加到url中 |
| data | 字典、字节序列或文件对象,作为Resquest的内容 |
| josn | JOSN格式的数据,作为Request的内容 |
| headers | 字典,HTTP定制头 |
| cookies | 字典或CookieJar,Request中的cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典类型,传输文件 |
| timeout | 设定超时时间,秒为单位 |
| proxies | 字典类型,设定访问代理服务器,可以增加登录认证 |
| allow_redirects | True/False,默认为True,重定向开关 |
| stream | True/False,默认为True,获取内容立即下载开关 |
| verify | True/False,默认为True,获取SSL证书开关 |
| cert | 本地SSL证书路径 |
Re库
正则表达式
常用操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [abc]表示a,b,c,[a-z]表示a到z单个字符 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次拓展 | abc*表示ab,abc,abcc,abccc等 |
| + | 前一个字符1次或无限次拓展 | abc+表示abc,abcc,abccc等 |
| ? | 前一个字符0次或1次拓展 | abc?表示ab,abc |
| | | 左右表达式任意一个 | abc |
| {m} | 拓展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 拓展前一个字符m至n次(含n) | ab{1,2}c表示abc,abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| () | 分组标记,内部只能使用|操作符 | (abc)表示abc,(abc |
| d | 数字,等价于[0-9] | |
| w | 单词字符,等价于[A-Za-z0-9_] | |
| 经典正则表达式实例 | ||
| 表达式 | 说明 | |
| --- | --- | |
| ^[A-Za-z]+$ | 由26个字母组成的字符串 | |
| ^[A-Za-z0-9]+$ | 由26个字母和数字组成的字符串 | |
| ^-?d+$ | 整数形式的字符串 | |
| ^[0-9]*[1-9][0-9]*$ | 正整数形式的字符串 | |
| [1-9]d{5} | 中国境内邮政编码,6位 | |
| [u4e00-u9fa5] | 匹配中文字符 |
Re库的使用
raw string类型(原生字符串类型)
re库采用raw string类型表示正则表达式,表示为:r'text'
raw string是不包含对转义符再次转义的字符串
Re库主要功能函数
re.search(pattern,string,flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置返回match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
| 常用标记 | 说明 |
|---|---|
| re.I(re.IGNORECASE) | 忽略正则表达式的大小写,[A-Z]能够匹配小写字符 |
| re.M(re.MULTILINE) | 正则表达式中^操作符能够给定字符串的每行当作匹配开始 |
| re.S(re.DOTALL) | 正则表达式中.操作符能够匹配所有字符,默认匹配除换行外的所有字符 |
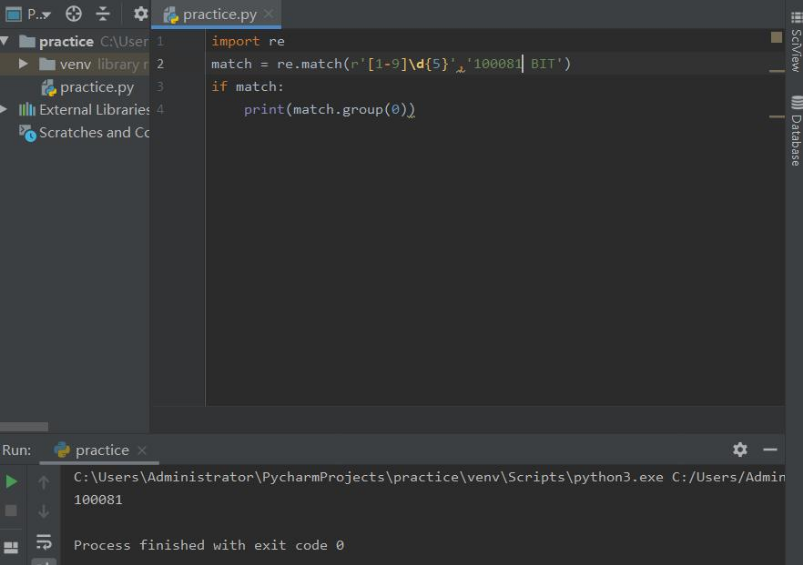
re.match(pattern,string,flags=0)
从一个字符串的开始位置起匹配正则表达式返回match对象
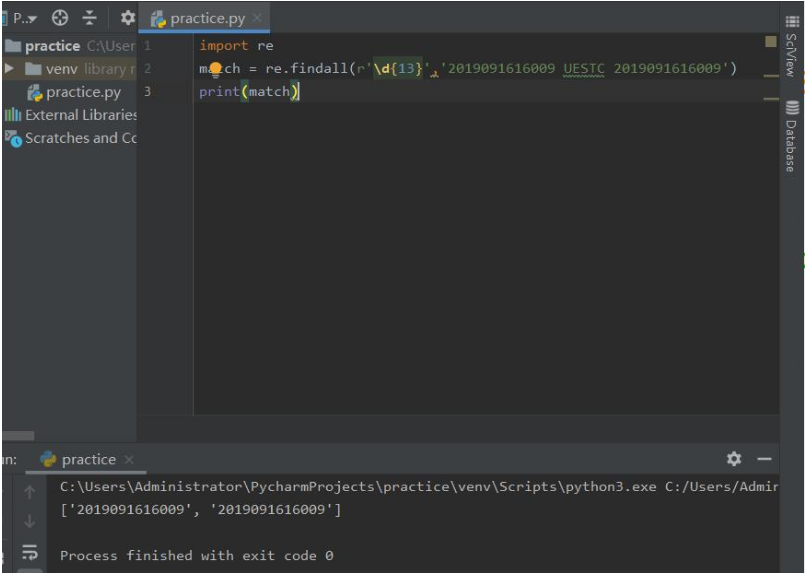
re.findall(pattern,string,flags=0)
搜索字符串,以列表类型返回全部能匹配的子串
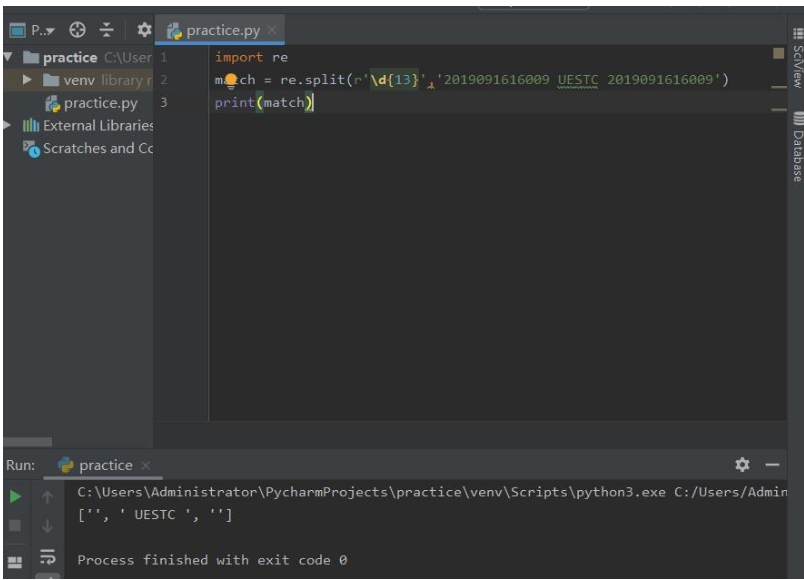
re.split(pattern,string,maxsplit,flags=0)
将一个字符串安装正则表达式匹配结果进行分割,返回列表类型
- maxsplit:最大分割数,剩余部分作为最后一个元素输出
re.finditer(pattern,string,flags=0)
搜索字符串,返回词汇表匹配结果的迭代类型,每个迭代类型元素是match对象

re.sub(pattern,repl,string,count=0,flags=0)
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
- repl:替换匹配的字符串的字符串
- 匹配的最大替换次数

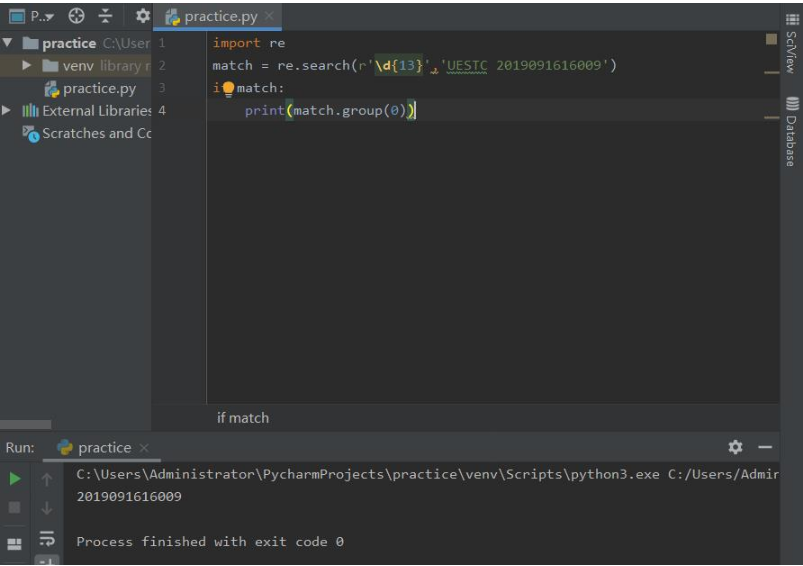
Re库的另一种等价用法
函数式用法:一次性操作
rst = re.search(r'[1-9]d{12}','UESTC 2019091616009')
面向对象用法:编译后的多次操作
pat = re.compile(r'[1-9]d{12})
rst = pat.search('UESTC 2019091616009')
Re库的Match对象
Match对象是一次匹配的结果,包含很多信息
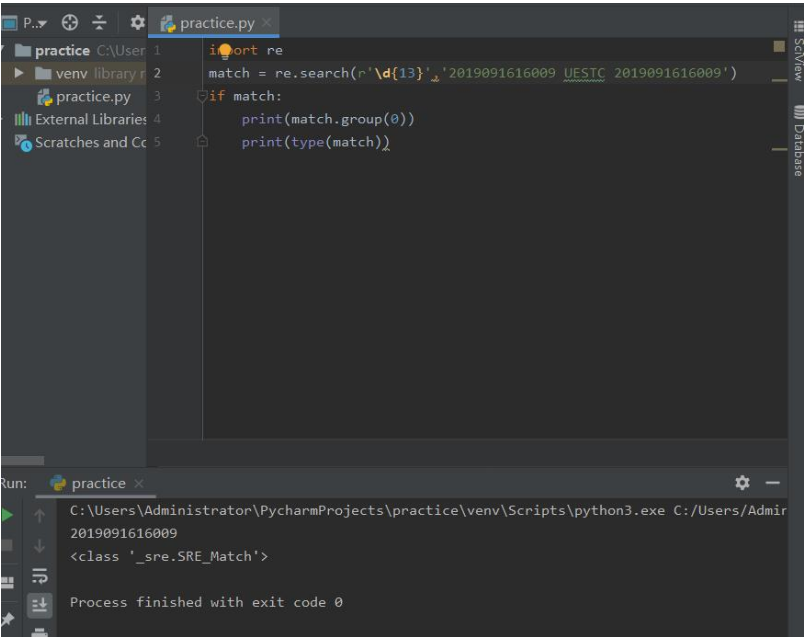
Match对象的属性
| 属性 | 说明 |
|---|---|
| .string | 待匹配的文本 |
| .re | 匹配时使用的patter对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
Match对象的方法
| 方法 | 说明 |
|---|---|
| .group(0) | 获得匹配后的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start(),.end()) |
 |
Re库的贪婪匹配和最小匹配
Re库默认采用贪婪匹配,即输出匹配最长的子串
**最小匹配操作符
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次拓展,最小匹配 |
| +? | 前一个字符1次或无限次拓展,最小匹配 |
| ?? | 前一个字符0次或1次拓展,最小匹配 |
| {m,n}? | 拓展前一个字符m至n次(含n),最小匹配 |
| 只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配 |