基本概念:
1、.net 架构的组成
(1)CLR(Common Language Runtime) 公共语言运行时,提供内存管理,代码安全性检查等功能。
(2)FCL(.NET Framework Class Library) .net 框架类库,提供大量应用类库。
2、CLR的结构
(1).CLS 公共语言规范,获取各种语言转换成统一的语法规则,是 .net 跨语言开发的基础
(2)CTS 通用类型系统,将各种语言中的数据类型转换成统一的类型。
(3)JIT 实时编译器(即时编译器)用于将转换之后的语言编译为二进制语言,交给CPU 执行
CLR一个很重要的特性就是Type安全。CLR在任何时候都知道某个对象的类型。你可以通过GetType方法获得,由于该方法不是虚函数,因此不能被覆盖,也就是说返回的值是永远真实的。
运行流程概述:
c# 源程序 ---> 经过 CLS、CTS 第一次编译 ---> 统一规范语言(中间语言 )MSIL(.exe、dll) ----> JIT第二次编译 ---> 二进制语言 ---> 运行在CPU中
流程详解:
一、使用VS 编写程序代码 eg: .cs文件
二、把上述文件编译为 .dll (程序集)文件
.dll文件中也包含我们所说的中间语言(IL)
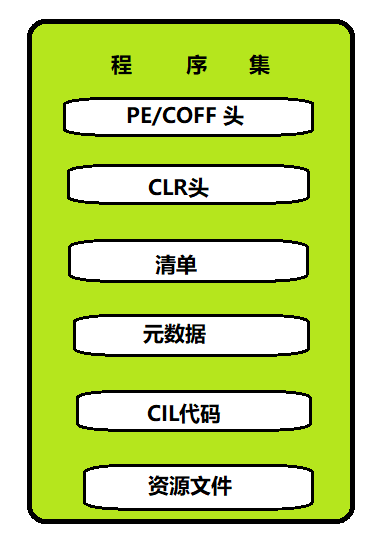
(1)PE/COFF头:Windows操作系统能加载并执行 .dll 和 .exe 文件,是因为他能够理解 PE/COFF格式
.PE/COFF(Micorsoft Windows Protable Executable/Commom Object File Format) 可移植可执行/通用对象文件格式。PE/COFF头包含了供操作系统查看和利用的信息,eg:文件指针
(2)CLR 头:程序集中包含的CLR 代码,并不是计算机可以直接运行的,还需要进行即时编译,so,需要将编译环境运行起来,因为,PE/COFF之后就是CLR头,告诉操作系统这个文件是一个.net 程序集,去呗其他类型的可执行程序
(3)清单:相当于一个目录,描述程序集本身的信息。eg:程序集表示(版本号,名称等),资源(Resources),组成文件。
(4)元数据:描述了程序集中所包含的内容,包括:程序集包含的模块、类型、成员、可见性等。注:元数据不包含类型的实现,在 .Net 中查看元数据的过程就叫做 “反射”。
(5)CIL代码:元数据中类型的实现。包括方法体,字段等
(6)资源文件:eg:图片,音频
三、CLR(公共语言运行库)中的 JIT(即时编译器 Just-In-Time)将我们的 IL 代码编译为机器代码
1、公共语言运行库 (common language runtime,CLR) 是托管代码执行核心中的引擎。
运行库为托管代码提供各种服务,如跨语言集成、代码访问安全性、对象生存期管理、调试和分析支持。
它是整个.NET框架的核心,它为.NET应用程序提供了一个托管的代码执行环境。它实际上是驻留在内存里的一段代理代码,负责应用程序在整个执行期间的代码管理工作。
2、JIT的主要功能:
(1)在负责实现类型的程序集的元数据中查找被调用的方法
(2)从程序集中找到该方法的 IL
(3)分配内存块
(4)将 IL 编译成本机的 CPU 指令,然后把这些东西丢进步骤三中分配的内存里
(5)CPU执行这些指令
JIT 编译时会使用即时编译,对不同架构的机器生成不同的机器码,大部分的代码优化也在这里。
JIT只有在运行时才会工作,生成项目(Build)时不会工作。
编译器在编译时,会对代码进行检查,对于只调用过一次的代码,不会进行优化,多次使用的才会进行JIT优化
通常,程序有两种运行方式:预先编译(AOT)与动态编译。预先编译的程序在执行前全部被翻译为机器码,而动态编译则是一句一句,边运行边翻译。即时编译则混合了这二者,一句句编译源代码,但是会将翻译过的代码缓存起来以降低性能损耗。
当运行程序时,CLR 先会调用类加载器加载需要的类型,加载完成之后,就创建了类型对象,包括方法

当首次调用该类型的 X 方法。由于其没有对应的机器码(除非它预先编译好了,例如Console 类中的方法),CLR 会在调用时遭遇 jmp 指令(目标为 JIT 编译器),将 X 方法的 IL 代码转换为机器码。
JIT 编译过程中,会做运行时的类型验证,将代码和元数据中的定义进行比对,确定代码的类型安全性。
编译完成之后,将机器码存储在缓存中,并将缓存地址放在 jmp 指令的后面,代替之前的 JIT 编译器地址。

以后对该方法的所有调用都不需要再次 JIT 编译, JIT 已将将机器码储存在内存中。当程序结束后,这些机器码就会消失,所以每次程序运行都伴随着即时编译。
不过,这个现象带来的性能损耗仅仅会在方法第一次调用时体现,而大部分程序都会调用方法不止一次