Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接
本文介绍Hive的使用原理及命令行、Java JDBC对于Hive的使用。
在Hadoop项目中,HDFS解决了文件分布式存储的问题,MapReduce解决了数据处理分布式计算问题,之前介绍过Hadoop生态中MapReduce(以下统称MR)的使用,大数据系列之分布式计算批处理引擎MapReduce实践。HBase解决了一种数据的存储和检索。那么要对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce类的。一方面,很麻烦,另一方面只能由懂MapReduce的程序员类编写。对于业务人员或数据科学家,非常不方便,这些人习惯了通过sql与rdbms打交道,因此如果有sql方式查询文件和数据就很有必要,这就是hive要满足的要求。
比如说采用MR处理WordCount统计词频时,我们如果用hql语句进行处理如下:
select word,count(*) as totalNum from t_word group by word order by totalNum desc
关于Hive的典型应用场景:
1.日志分析
2.统计网站一个时间段的pv,uv;
3.多维度数据分析;
4.海量结构化数据离线分析;
5.低成本进行数据分析(无须编写MR).
介绍Hive中分区-Partition的意义
1.Hive的数据类型
1.1 基本数据类型:
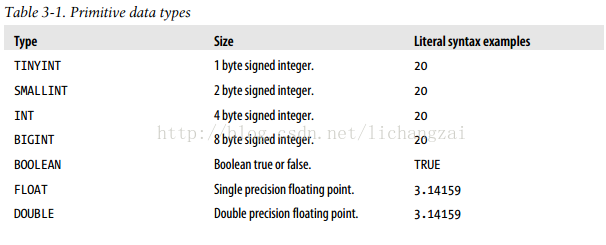
1.2 hive的集合类型:

2.hive的命令练习:
连接hive:
beeline !connect jdbc:hive2://master:10000/dbmfz mfz 111111
2.1 基本数据类型命令使用
#用户表创建 create table if not EXISTS user_dimension( uid String, name string, gender string, birth date, province string ) row format delimited fields terminated by ','; describe user_dimension; show create table user_dimension; #品牌表创建 create table if not EXISTS brand_dimension( bid string, category string, brand string )row format delimited fields terminated by ','; #交易表创建 create table if not EXISTS record_dimension( rid string, uid string, bid string, price int, source_province string, target_province string, site string, express_number string, express_company string, trancation_date date )row format delimited fields terminated by ','; show tables; #创建数据 user.DATA brand.DATA record.DATA #载入数据 LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/user.data' OVERWRITE INTO TABLE user_dimension; LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/brand.data' OVERWRITE INTO TABLE brand_dimension; LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/record.data' OVERWRITE INTO TABLE record_dimension; #验证 select * from user_dimension; select * from brand_dimension; select * from record_dimension; #载入HDFS上数据 load data inpath 'user.data_HDFS_PATH' OVERWRITE INTO TABLE user_dimension; #查询 select count(*) from record_dimension where trancation_date = '2017-09-01'; +-----+--+ | c0 | +-----+--+ | 6 | +-----+--+ #不同年龄消费的情况 select cast(datediff(CURRENT_DATE ,birth)/365 as int ) as age,sum(price) as totalPrice from record_dimension rd JOIN user_dimension ud on rd.uid = ud.uid group by cast(datediff(CURRENT_DATE ,birth)/365 as int) order by totalPrice DESC ; +------+-------------+--+ | age | totalprice | +------+-------------+--+ | 5 | 944 | | 25 | 877 | | 24 | 429 | | 28 | 120 | +------+-------------+--+ #不同品牌被消费的情况 select brand,sum(price) as totalPrice from record_dimension rd join brand_dimension bd on bd.bid = rd.bid group by bd.brand order by totalPrice desc; +------------+-------------+--+ | brand | totalprice | +------------+-------------+--+ | SAMSUNG | 944 | | OPPO | 625 | | WULIANGYE | 429 | | DELL | 252 | | NIKE | 120 | +------------+-------------+--+ #统计2017-09-01 当天各个品牌的交易笔数,按照倒序排序 select brand,count(*) as sumCount from record_dimension rd join brand_dimension bd on bd.bid=rd.bid where rd.trancation_date='2017-09-01' group by bd.brand order by sumCount desc +------------+-----------+--+ | brand | sumcount | +------------+-----------+--+ | SAMSUNG | 2 | | WULIANGYE | 1 | | OPPO | 1 | | NIKE | 1 | | DELL | 1 | +------------+-----------+--+ #不同性别消费的商品类别情况 select ud.gender as gender,bd.category shangping,sum(price) totalPrice,count(*) FROM record_dimension rd join user_dimension ud on rd.uid = ud.uid join brand_dimension bd on rd.bid = bd.bid group by ud.gender,bd.category; +---------+------------+-------------+-----+--+ | gender | shangping | totalprice | c3 | +---------+------------+-------------+-----+--+ | F | telephone | 944 | 2 | | M | computer | 252 | 1 | | M | food | 429 | 1 | | M | sport | 120 | 1 | | M | telephone | 625 | 1 | +---------+------------+-------------+-----+--+
2.3. 集合数据类型的命令操作
#data employees.txt create database practice2; show databases; use practice2; create table if not EXISTS employees( name string, salary string, subordinates array<String>, deductions map<String,Float>, address struct<street:string,city:string,state:string,zip:int> ) row format delimited fields terminated by '�01' collection items terminated by '�02' map keys terminated by '�03' lines terminated by ' ' stored as textfile; describe employees; +---------------+---------------------------------------------------------+----------+--+ | col_name | data_type | comment | +---------------+---------------------------------------------------------+----------+--+ | name | string | | | salary | string | | | subordinates | array<string> | | | deductions | map<string,float> | | | address | struct<street:string,city:string,state:string,zip:int> | | +---------------+---------------------------------------------------------+----------+--+ LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/employees.txt' OVERWRITE INTO TABLE employees; +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ | John Doe | 100000.0 | ["Mary Smith","Todd Jones"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | {"street":"1 Michigan Ave.","city":"Chicago","state":"IL","zip":60600} | | Mary Smith | 80000.0 | ["Bill King"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | {"street":"100 Ontario St.","city":"Chicago","state":"IL","zip":60601} | | Todd Jones | 70000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"200 Chicago Ave.","city":"Oak Park","state":"IL","zip":60700} | | Bill King | 60000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"300 Obscure Dr.","city":"Obscuria","state":"IL","zip":60100} | | Boss Man | 200000.0 | ["John Doe","Fred Finance"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | {"street":"1 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Fred Finance | 150000.0 | ["Stacy Accountant"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | {"street":"2 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Stacy Accountant | 60000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"300 Main St.","city":"Naperville","state":"IL","zip":60563} | +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ select * from employees where deductions['Federal Taxes']>0.2; +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | John Doe | 100000.0 | ["Mary Smith","Todd Jones"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | { "street":"1 Michigan Ave.","city":"Chicago","state":"IL","zip":60600} | | Mary Smith | 80000.0 | ["Bill King"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | { "street":"100 Ontario St.","city":"Chicago","state":"IL","zip":60601} | | Boss Man | 200000.0 | ["John Doe","Fred Finance"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | { "street":"1 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Fred Finance | 150000.0 | ["Stacy Accountant"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | { "street":"2 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ #查询第一位下属是John Doe的 select * from employees where subordinates[0] = 'John Doe'; +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | Boss Man | 200000.0 | ["John Doe","Fred Finance"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | { "street":"1 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ #查询经理 --下属人数大于0 select * from employees where size(subordinates)>0; +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ | John Doe | 100000.0 | ["Mary Smith","Todd Jones"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | { "street":"1 Michigan Ave.","city":"Chicago","state":"IL","zip":60600} | | Mary Smith | 80000.0 | ["Bill King"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | { "street":"100 Ontario St.","city":"Chicago","state":"IL","zip":60601} | | Boss Man | 200000.0 | ["John Doe","Fred Finance"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | { "street":"1 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Fred Finance | 150000.0 | ["Stacy Accountant"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | { "street":"2 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | +-----------------+-------------------+------------------------------+------------------------------------------------------------+-- ----------------------------------------------------------------------------+--+ #查询地址状态在IL select * from employees where address.state='IL'; +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ | John Doe | 100000.0 | ["Mary Smith","Todd Jones"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | {"street":"1 Michigan Ave.","city":"Chicago","state":"IL","zip":60600} | | Mary Smith | 80000.0 | ["Bill King"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | {"street":"100 Ontario St.","city":"Chicago","state":"IL","zip":60601} | | Todd Jones | 70000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"200 Chicago Ave.","city":"Oak Park","state":"IL","zip":60700} | | Bill King | 60000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"300 Obscure Dr.","city":"Obscuria","state":"IL","zip":60100} | | Boss Man | 200000.0 | ["John Doe","Fred Finance"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | {"street":"1 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Fred Finance | 150000.0 | ["Stacy Accountant"] | {"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05} | {"street":"2 Pretentious Drive.","city":"Chicago","state":"IL","zip":60500} | | Stacy Accountant | 60000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"street":"300 Main St.","city":"Naperville","state":"IL","zip":60563} | +-------------------+-------------------+------------------------------+------------------------------------------------------------+ ------------------------------------------------------------------------------+--+ #模糊查询city 头字符是Na select * from employees where address.city like 'Na%'; +-------------------+-------------------+-------------------------+------------------------------------------------------------+----- --------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-------------------+-------------------+-------------------------+------------------------------------------------------------+----- --------------------------------------------------------------------+--+ | Stacy Accountant | 60000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"st reet":"300 Main St.","city":"Naperville","state":"IL","zip":60563} | +-------------------+-------------------+-------------------------+------------------------------------------------------------+----- --------------------------------------------------------------------+--+ #正则查询 select * from employees where address.street rlike '^.*(Ontario|Chicago).*$'; +-----------------+-------------------+-------------------------+------------------------------------------------------------+------- --------------------------------------------------------------------+--+ | employees.name | employees.salary | employees.subordinates | employees.deductions | employees.address | +-----------------+-------------------+-------------------------+------------------------------------------------------------+------- --------------------------------------------------------------------+--+ | Mary Smith | 80000.0 | ["Bill King"] | {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} | {"stre et":"100 Ontario St.","city":"Chicago","state":"IL","zip":60601} | | Todd Jones | 70000.0 | [] | {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1} | {"stre et":"200 Chicago Ave.","city":"Oak Park","state":"IL","zip":60700} | +-----------------+-------------------+-------------------------+------------------------------------------------------------+------- --------------------------------------------------------------------+--+
2.4 分区Partition的命令使用
#stocks表创建 CREATE TABLE if not EXISTS stocks( ymd date, price_open FLOAT , price_high FLOAT , price_low FLOAT , price_close float, volume int, price_adj_close FLOAT )partitioned by (exchanger string,symbol string) row format delimited fields terminated by ','; #加载数据 LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/stocks.csv' OVERWRITE INTO TABLE stocks partition(exchanger="NASDAQ",symbol="AAPL"); #查询partition stocks show partitions stocks; +-------------------------------+--+ | partition | +-------------------------------+--+ | exchanger=NASDAQ/symbol=AAPL | +-------------------------------+--+ #建立多个分区加载不同的数据 LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/stocks.csv' OVERWRITE INTO TABLE stocks partition(exchanger="NASDAQ",symbol="INTC"); LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/stocks.csv' OVERWRITE INTO TABLE stocks partition(exchanger="NYSE",symbol="GE"); LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/stocks.csv' OVERWRITE INTO TABLE stocks partition(exchanger="NYSE",symbol="IBM"); #分页查询stocks分区是exchanger='NASDAQ' and symbol='AAPL'的数据 select * from stocks where exchanger='NASDAQ' and symbol='AAPL' limit 10 ; +-------------+--------------------+--------------------+-------------------+---------------------+----------------+----------------- --------+-------------------+----------------+--+ | stocks.ymd | stocks.price_open | stocks.price_high | stocks.price_low | stocks.price_close | stocks.volume | stocks.price_adj _close | stocks.exchanger | stocks.symbol | +-------------+--------------------+--------------------+-------------------+---------------------+----------------+----------------- --------+-------------------+----------------+--+ | 2010-02-08 | 195.69 | 197.88 | 194.0 | 194.12 | 17036300 | 194.12 | NASDAQ | AAPL | | 2010-02-05 | 192.63 | 196.0 | 190.85 | 195.46 | 30344200 | 195.46 | NASDAQ | AAPL | | 2010-02-04 | 196.73 | 198.37 | 191.57 | 192.05 | 27022300 | 192.05 | NASDAQ | AAPL | | 2010-02-03 | 195.17 | 200.2 | 194.42 | 199.23 | 21951800 | 199.23 | NASDAQ | AAPL | | 2010-02-02 | 195.91 | 196.32 | 193.38 | 195.86 | 24928900 | 195.86 | NASDAQ | AAPL | | 2010-02-01 | 192.37 | 196.0 | 191.3 | 194.73 | 26717800 | 194.73 | NASDAQ | AAPL | | 2010-01-29 | 201.08 | 202.2 | 190.25 | 192.06 | 44448700 | 192.06 | NASDAQ | AAPL | | 2010-01-28 | 204.93 | 205.5 | 198.7 | 199.29 | 41874400 | 199.29 | NASDAQ | AAPL | | 2010-01-27 | 206.85 | 210.58 | 199.53 | 207.88 | 61478400 | 207.88 | NASDAQ | AAPL | | 2010-01-26 | 205.95 | 213.71 | 202.58 | 205.94 | 66605200 | 205.94 | NASDAQ | AAPL | +-------------+--------------------+--------------------+-------------------+---------------------+----------------+----------------- --------+-------------------+----------------+--+ #统计各分区中总数 select exchanger,symbol,count(*) from stocks group by exchanger,symbol; +------------+---------+-------+--+ | exchanger | symbol | c2 | +------------+---------+-------+--+ | NASDAQ | AAPL | 6412 | | NASDAQ | INTC | 6412 | | NYSE | GE | 6412 | | NYSE | IBM | 6412 | +------------+---------+-------+--+ #统计各分区中最大的最大消费金额 select exchanger,symbol,max(price_high) from stocks group by exchanger,symbol; +------------+---------+---------+--+ | exchanger | symbol | c2 | +------------+---------+---------+--+ | NASDAQ | AAPL | 215.59 | | NASDAQ | INTC | 215.59 | | NYSE | GE | 215.59 | | NYSE | IBM | 215.59 | +------------+---------+---------+--+
2.5 Hive ORCFile 的操作:
更高的压缩比,更好的性能–使用ORC文件格式优化Hive
create table if not EXISTS record_orc( rid string, uid string, bid string, price int, source_province string, target_province string, site string, express_number string, express_company string, trancation_date date )stored as orc; show create table record_orc; +---------------------------------------------------------------------+--+ | createtab_stmt | +---------------------------------------------------------------------+--+ | CREATE TABLE `record_orc`( | | `rid` string, | | `uid` string, | | `bid` string, | | `price` int, | | `source_province` string, | | `target_province` string, | | `site` string, | | `express_number` string, | | `express_company` string, | | `trancation_date` date) | | ROW FORMAT SERDE | | 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' | | STORED AS INPUTFORMAT | | 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' | | OUTPUTFORMAT | | 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' | | LOCATION | | 'hdfs://master:9000/user/hive/warehouse/practice2.db/record_orc' | | TBLPROPERTIES ( | | 'COLUMN_STATS_ACCURATE'='{"BASIC_STATS":"true"}', | | 'numFiles'='0', | | 'numRows'='0', | | 'rawDataSize'='0', | | 'totalSize'='0', | | 'transient_lastDdlTime'='1491706697') | +---------------------------------------------------------------------+--+ #载入数据 insert into table record_orc select * from record_dimension; select * from record_orc; +-----------------+-----------------+-----------------+-------------------+-----------------------------+---------------------------- -+------------------+----------------------------+-----------------------------+-----------------------------+--+ | record_orc.rid | record_orc.uid | record_orc.bid | record_orc.price | record_orc.source_province | record_orc.target_province | record_orc.site | record_orc.express_number | record_orc.express_company | record_orc.trancation_date | +-----------------+-----------------+-----------------+-------------------+-----------------------------+---------------------------- -+------------------+----------------------------+-----------------------------+-----------------------------+--+ | 0000000000 | 00000001 | 00000002 | 625 | HeiLongJiang | HuNan | TianMao | 22432432532123421431 | ShenTong | 2017-09-01 | | 0000000001 | 00000001 | 00000001 | 252 | GuangDong | HuNan | JingDong | 73847329843 | ZhongTong | 2017-09-01 | | 0000000002 | 00000004 | 00000003 | 697 | JiangSu | Huan | TianMaoChaoShi | 2197298357438 | Shunfeng | 2017-09-01 | | 0000000003 | 00000004 | 00000003 | 247 | TianJing | NeiMeiGu | JingDong | 73298759327894 | YunDa | 2017-09-01 | | 0000000004 | 00000002 | 00000004 | 429 | ShangHai | Ning | TianMao | 438294820 | YunDa | 2017-09-01 | | 0000000005 | 00000008 | 00000005 | 120 | HuBei | Aomen | JuHU | 5349523959 | ZhongTong | 2017-09-01 | +-----------------+-----------------+-----------------+-------------------+-----------------------------+---------------------------- -+------------------+----------------------------+-----------------------------+-----------------------------+--+ select * from record_dimension; +-----------------------+-----------------------+-----------------------+-------------------------+---------------------------------- -+-----------------------------------+------------------------+----------------------------------+----------------------------------- +-----------------------------------+--+ | record_dimension.rid | record_dimension.uid | record_dimension.bid | record_dimension.price | record_dimension.source_province | record_dimension.target_province | record_dimension.site | record_dimension.express_number | record_dimension.express_company | record_dimension.trancation_date | +-----------------------+-----------------------+-----------------------+-------------------------+---------------------------------- -+-----------------------------------+------------------------+----------------------------------+----------------------------------- +-----------------------------------+--+ | 0000000000 | 00000001 | 00000002 | 625 | HeiLongJiang | HuNan | TianMao | 22432432532123421431 | ShenTong | 2017-09-01 | | 0000000001 | 00000001 | 00000001 | 252 | GuangDong | HuNan | JingDong | 73847329843 | ZhongTong | 2017-09-01 | | 0000000002 | 00000004 | 00000003 | 697 | JiangSu | Huan | TianMaoChaoShi | 2197298357438 | Shunfeng | 2017-09-01 | | 0000000003 | 00000004 | 00000003 | 247 | TianJing | NeiMeiGu | JingDong | 73298759327894 | YunDa | 2017-09-01 | | 0000000004 | 00000002 | 00000004 | 429 | ShangHai | Ning | TianMao | 438294820 | YunDa | 2017-09-01 | | 0000000005 | 00000008 | 00000005 | 120 | HuBei | Aomen | JuHU | 5349523959 | ZhongTong | 2017-09-01 | +-----------------------+-----------------------+-----------------------+-------------------------+---------------------------------- -+-----------------------------------+------------------------+----------------------------------+----------------------------------- +-----------------------------------+--+
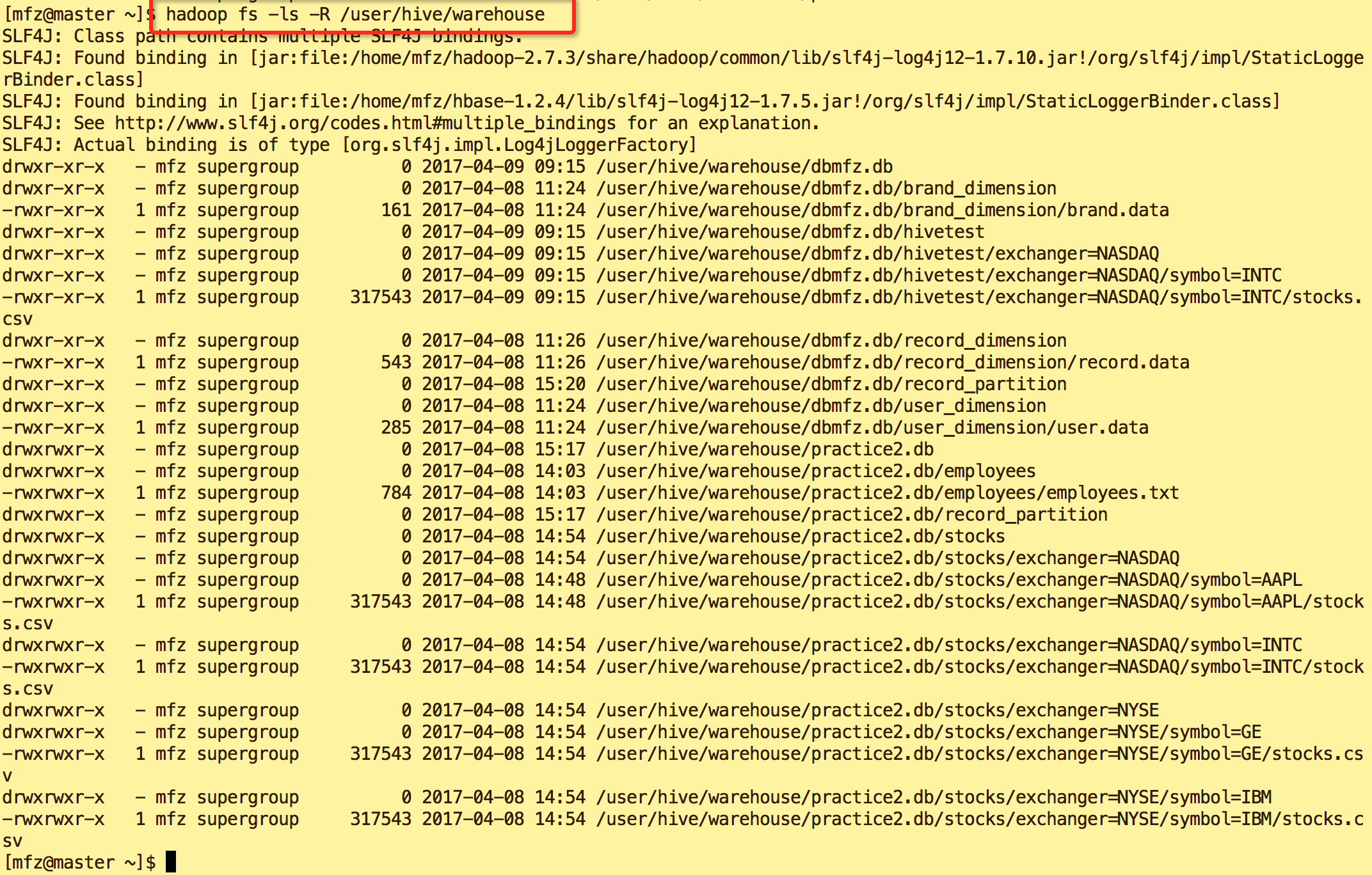
从数据结果来看没有多大区别。那我们来看下hdfs上的存储文件:
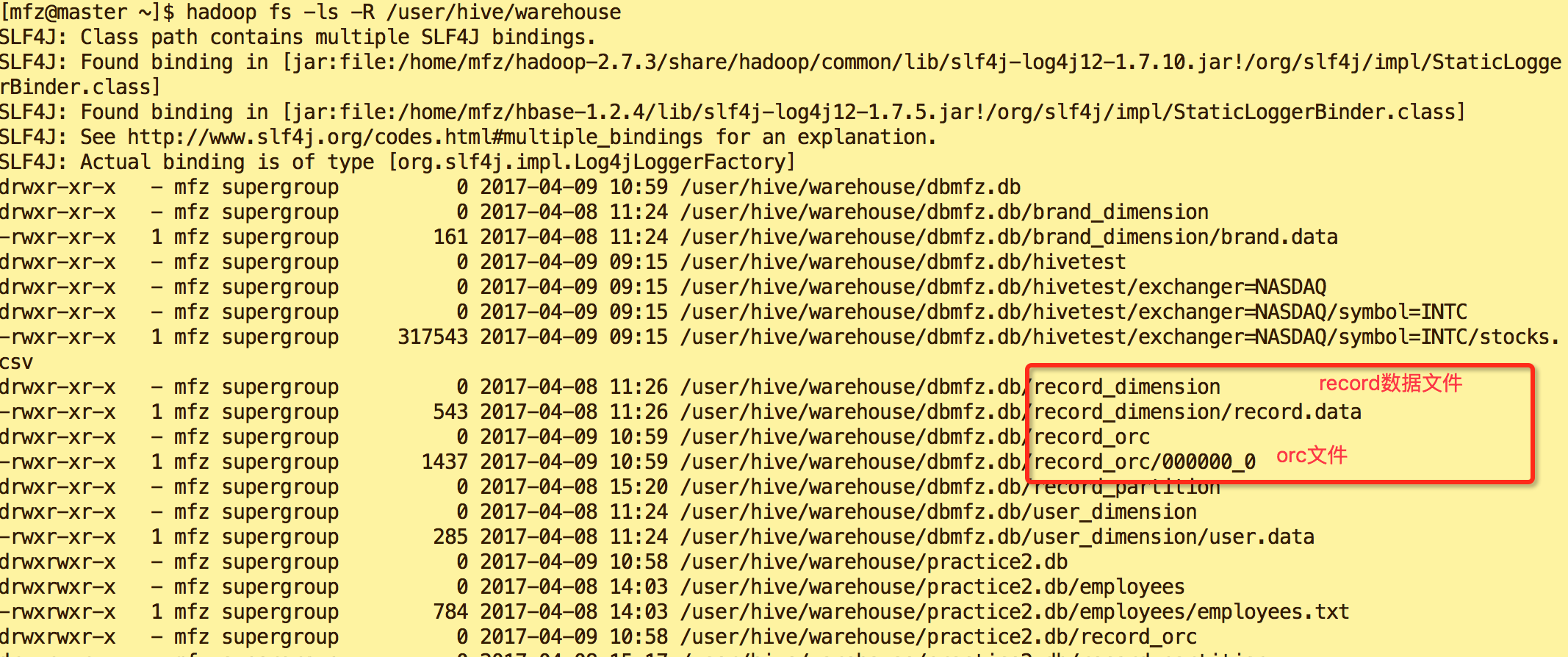


3.介绍下基本的JDBC连接hiveServer2的示例
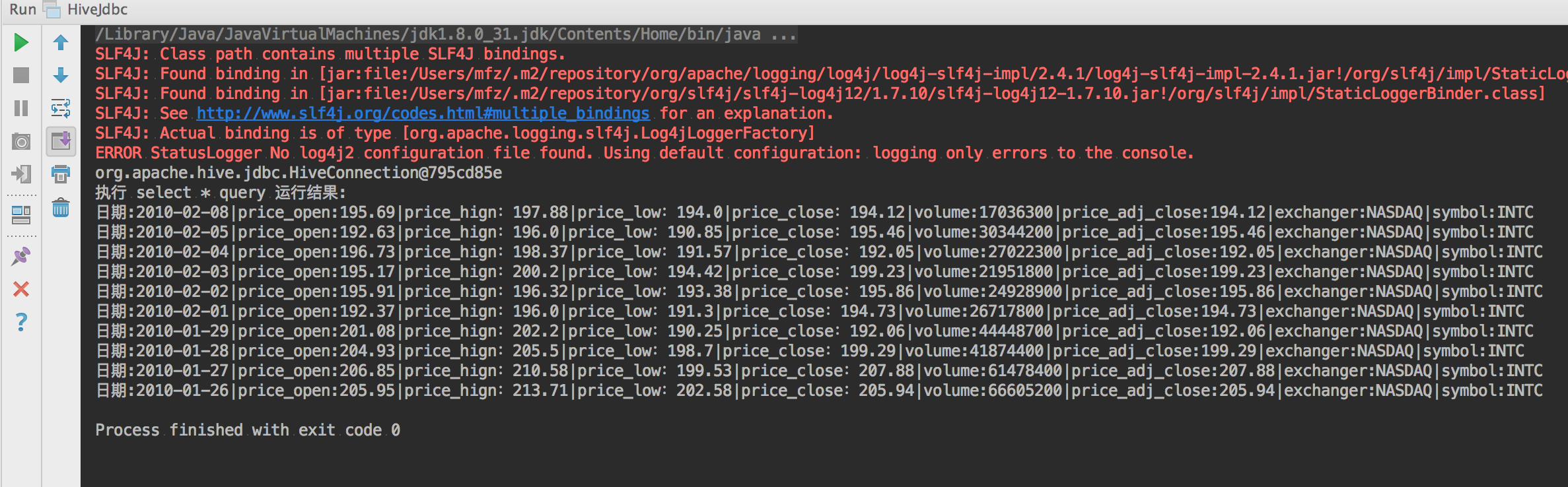
package com.m.hive; import java.sql.*; /** * @author mengfanzhu * @Package com.m.hive * @Description: * @date 17/4/3 11:57 */ public class HiveJdbc { private static String driverName = "org.apache.hive.jdbc.HiveDriver";//jdbc驱动路径 private static String url = "jdbc:hive2://10.211.55.5:10000/dbmfz";//hive库地址+库名 private static String user = "mfz";//用户名 private static String password = "111111";//密码 public static void main(String[] args) { Connection conn = null; Statement stmt = null; ResultSet res = null; try { conn = getConn(); System.out.println(conn); stmt = conn.createStatement(); stmt.execute("drop table hivetest"); stmt.execute("CREATE TABLE if not EXISTS hivetest(" + "ymd date," + "price_open FLOAT ," + "price_high FLOAT ," + "price_low FLOAT ," + "price_close float," + "volume int," + "price_adj_close FLOAT" + ")partitioned by (exchanger string,symbol string)" + "row format delimited fields terminated by ','"); stmt.execute("LOAD DATA LOCAL INPATH '/home/mfz/apache-hive-2.1.1-bin/hivedata/stocks.csv' " + "OVERWRITE INTO TABLE hivetest partition(exchanger="NASDAQ",symbol="INTC")"); res = stmt.executeQuery("select * from hivetest limit 10"); System.out.println("执行 select * query 运行结果:"); while (res.next()) { System.out.println( "日期:"+res.getString(1)+ "|price_open:"+res.getString(2)+ "|price_hign:"+res.getString(3)+ "|price_low:"+res.getString(4)+ "|price_close:"+res.getString(5)+ "|volume:"+res.getString(6)+ "|price_adj_close:"+res.getString(7)+ "|exchanger:"+res.getString(8)+ "|symbol:"+res.getString(9)); } } catch (ClassNotFoundException e) { e.printStackTrace(); System.exit(1); } catch (SQLException e) { e.printStackTrace(); System.exit(1); }finally { try{ if(null!=res){ res.close(); } if(null!=stmt){ stmt.close(); } if(null!=conn){ conn.close(); } }catch (Exception e){ e.printStackTrace(); } } } private static Connection getConn() throws ClassNotFoundException, SQLException { Class.forName(driverName); Connection conn = DriverManager.getConnection(url, user, password); return conn; } }
运行结果
操作完成后我们在hdfs中可以见到我们之前操作过的文件。这个目录是我们之前在hive-site.xml中配置了此项
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>locationofdefault databasefor thewarehouse</description>
</property>
完~,项目示例见Github https://github.com/fzmeng/HiveExample