平台数据仓库使用Hive进行构建,通过调研决定使用“SQL Standards Based Authorization in HiveServer2”对用户提交的SQL进行权限控制,也可根据实际情况选择是否开启“Storage Based Authorization in the Metastore Server”。
权限校验时需要识别提交SQL的用户名(即:与HiveServer2建立连接时使用的用户名),在使用Kerberos的环境下,用户名为通过Kerberos认证的用户名;在没有使用Kerberos的环境下,用户名依靠系统赋值或用户输入,有一定的随意性,存在伪装用户身份的可能性。
本文档不考虑用户名伪造的问题(在Kerberos环境下进行),以此为前提讨论数据仓库中Hive权限控制的问题。
SQL Standards Based Authorization in HiveServer2官方文档地址https://cwiki.apache.org/confluence/display/Hive/SQL+Standard+Based+Hive+Authorization,其中有一句很重要的说明:
The checks will happen against the user who submits the request, but the query will run as the Hive server user. The directories and files for input data would have read access for this Hive server user.
权限校验时是以提交SQL的用户身份进行的,而具体执行SQL时是以HiveServer2用户身份(可以简单理解为HiveServer2的进程启动用户)进行的,因此HiveServer2用户需要具有读取HDFS目录或文件的权限,根据应用场景不同,可能也需要写/执行权限。
平台HDFS的超级用户为hdfs,数据的ETL均以此账号进行,导致HDFS中的目录或文件所属用户均为hdfs,而HiveServer2需要与HDFS中的数据进行交互,因此我们需要以hdfs用户启动HiveServer2,并确保Hive在HDFS的基目录(假设为“/warehouse”)具有如下权限:

只有这样才能保证HiveServer2在执行SQL语句(以hdfs用户执行)时不会遇到目录或文件的权限问题。
SQL Standards Based Authorization in HiveServer2默认提供两种角色:public和admin,所有用户默认属于角色public,而授权则必须是具有角色admin的用户才可以完成(普通用户仅可以将自己获得的权限授权给其它用户),因此我们必须添加至少一个用户拥有角色admin,通过在hive-site.xml中配置:

为了保持超级户的一致性,我们将用户hdfs加入角色admin,从而使用户hdfs变成我们HiveServer2的内置“超级用户”。
数据仓库中存在两种类型的数据库:数据集数据库和用户数据库。数据集数据库(仅有一个)中包含平台所有业务数据表,用户数据库(每个用户一个数据库)存储用户的查询结果表。
根据实际情况,用户数据库可以以两个数据库的形式存在,一个为用户主库,主要用于保存用户需要长期留存或后续需要分析的查询结果表;一个为用户从库,主要用于保存用户临时查询结果表或系统执行中间表,也可以用于保存用户从主库删除的表(延迟删除)。
注:本文档不考虑用户从库的从库。
根据上述描述,模拟场景如下:
(1)数据集数据库:dataset;
(2)管理员:qixing、yurun;
(3)team1:tongwei、hexiang;
(4)team2:xinqi、hanhan
平台希望通过Hive权限控制达到的效果如下:
(1)管理员可以将指定用户加入角色admin;
(2)数据库dataset的所有者为角色admin,只有具有角色admin的用户才可以在此库中完成建表、修改表、删除表等操作;
(3)普通用户无法查看或使用没有权限的数据库、没有权限的表(需要扩展现有的权限机制);
(4)管理员可将数据库dataset中的表(视图)查询权限赋予某个角色或某个用户;
(5)普通用户是自己用户主(从)库的所有者,即拥有库内所有表(视图)的所有权限;
(6)普通用户可以将自己拥有的权限赋予给其它角色或用户。
数据仓库中目前仅有一个超级用户hdfs,需要将我们的管理员qixing、yurun加入角色admin,如下:

注意:这里我们使用Kerberos进行认证,并通过beeline连接至HiveServer2。
将管理员qixing、yurun加入角色admin:

注意:需要将hdfs用户的“当前角色”切换至admin才可以执行此操作,否则会引发下述异常:

创建数据集数据库dataset,

从上面的描述信息可以看出数据库dataset的所有者为超级用户hdfs,很多数据表的维护工作(表的添加、修改、删除)都需要数据库“所有者”权限,因此将数据库dataset的所有者修改为角色admin,这样所有管理员(所有管理员都属于角色admin)均可以参与数据库dataset维护工作,如下:

为team1和team2中的用户创建数据库,并设置各自的数据库所有者为对应的用户(此操作应该在用户注册时完成):



每一个团队中的成员大多数情况下需要的分析的业务数据表是相同的,为了方便授权的维护管理,对业务表的授权多数基于角色(每一个团队就是数据仓库中的一个角色)进行,个别情况下基于用户授权。
建立角色team1和team2,并关联相应的用户:
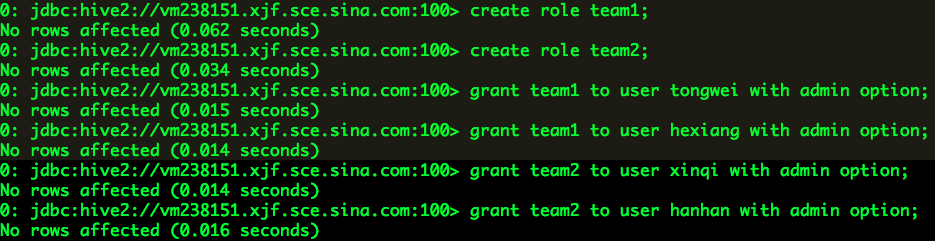
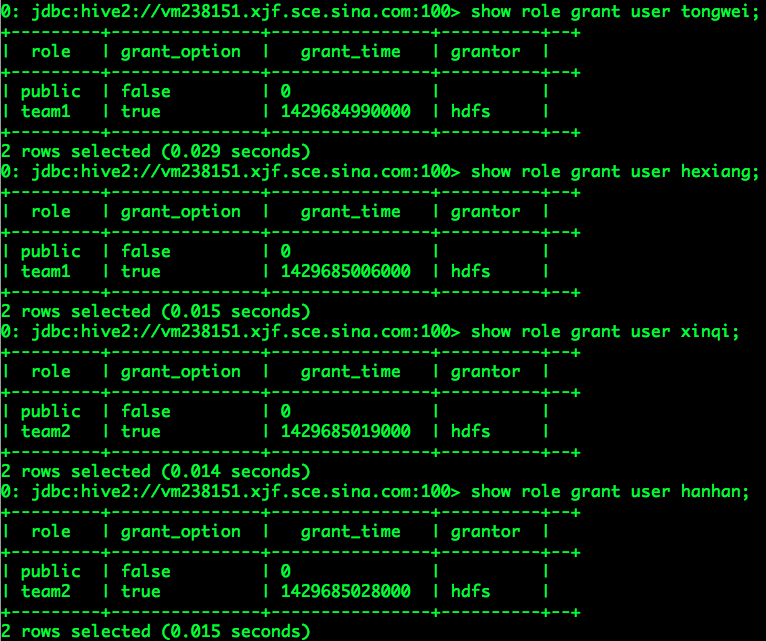
注:在将管理员qingxi、yurun添加至角色admin之后,上述所有操作均可以以qingxi、yurun登录并完成。
以yurun账号登录并创建业务数据表data_a:

注:因为数据库的所有者为角色admin,需要先将“当前角色”切换至角色admin,yurun才可以完成建表操作。
接着创建业务数据表data_b、data_c:

现在假设team1中的用户tongwei、hexiang需要分析业务数据表data_a,以用户tongwei为例登录系统后,
可以看到所有的数据库名称(注意此时用户tongwei只可以通过认证登录系统,还没有被赋予任何权限):
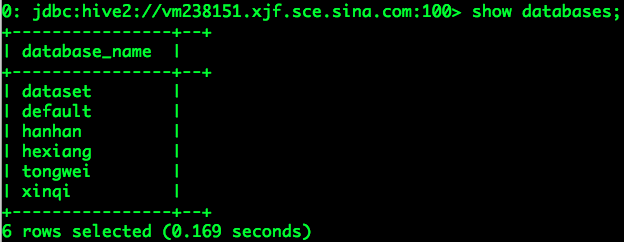
可以进入任意一个数据库:

可以看到所有的业务数据表:
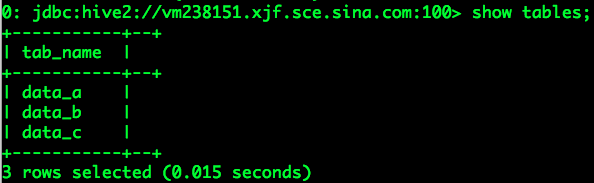
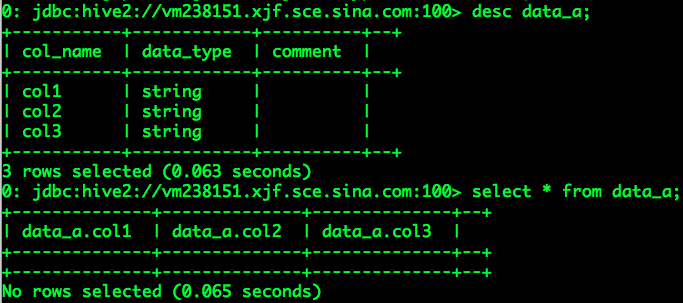
但是,当用户tongwei执行describe或select语句时出现了错误提示,

由上可以看出,“SQL Standards Based Authorization in HiveServer2”无法对show databases、use databaseName、show tables操作进行权限控制(关于这几点我们需要扩展完成权限控制),但它可以对表(视图)的describe、select、insert、update、delete进行权限控制。
考虑到team1中的所有成员都需要分析业务数据表data_a,管理员yurun将业务数据表data_a的查询权限赋予给角色team1,

此时用户tongwei便可以顺利执行describe或select语句,
但因为用户tongwei仅仅被赋予业务数据表data_a的select权限(其实是将select权限赋予给角色team1,角色team1成员均有data_a的select权限),他是无法完成其它非select操作的,比如试图删除业务数据表data_a,

他也没有办法将自己的“当前角色”切换至角色admin,

假设现在业务数据表data_b有一个特殊分析需求,领导指定只有team1中的tongwei可以参与分析,则我们需要将业务数据表data_b的select权限仅赋予tongwei,

此时tongwei登录系统后即可以完成data_b的相关分析,与data_a相同,不再赘述。
当用户hexiang登录系统后,他可以完成业务数据表data_a的分析,却没有权限分析业务数据表data_b,
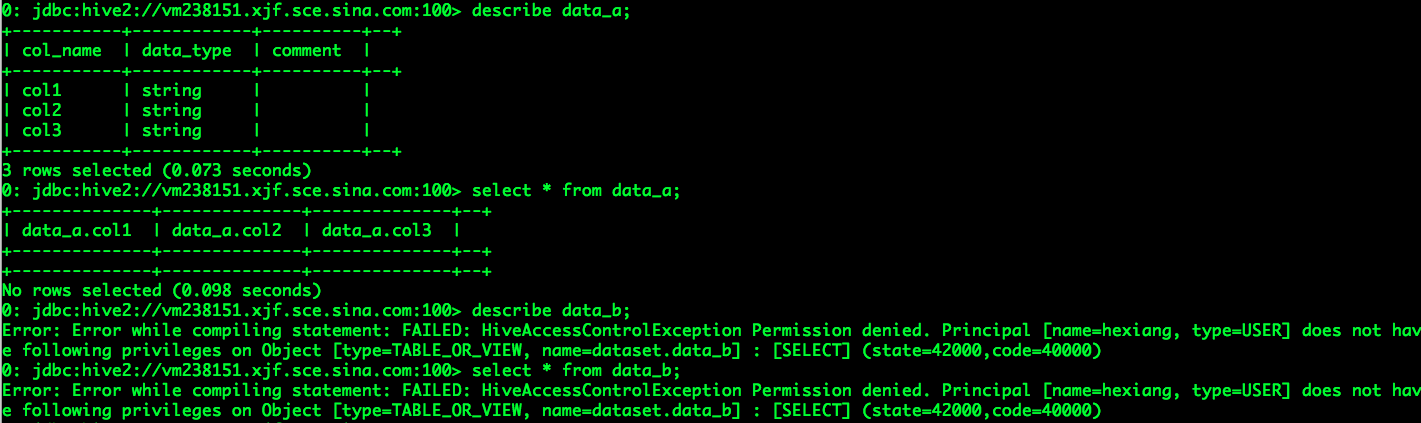
用户tongwei和hexiang均没有权限分析业务数据表data_c,


由上所述,我们已经基本完成用户(部门,即角色)与业务数据表之间的授权,用户(部门,即角色)最多只可以拥有业务数据表的select权限,业务数据表的相关维护工作由超级用户或平台管理员完成。
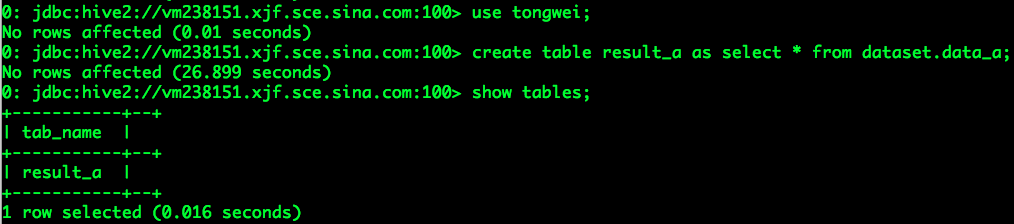
假设用户tongwei基于业务数据表data_a完成一个分析需求,并将结果保存至结果表result_a,
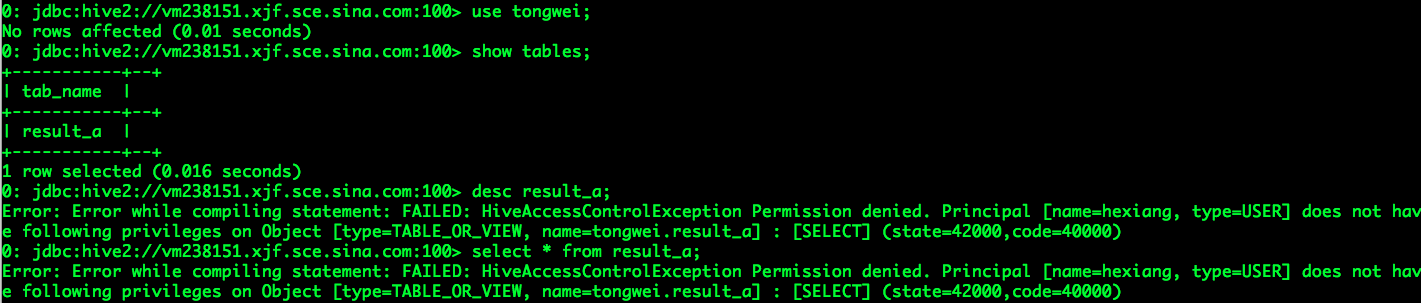
某一时刻,同一个团队(team1)的hexiang需要借助tongwei的分析结果result_a完成分析,此时hexiang发现他自己没有结果表result_a的select权限,
此时,hexiang可以请求管理员或者tongwei(tongwei是结果表result_a的所有者,可以进行result_a的授权)赋予自己结果表的select权限(以tongwei授权为例),
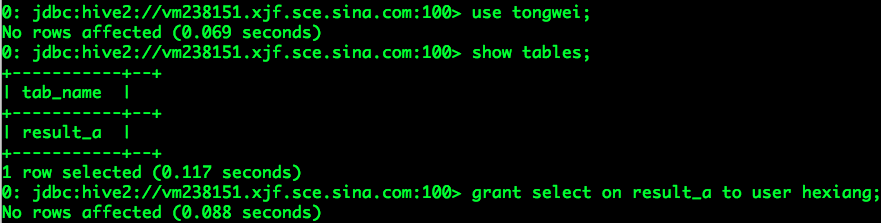
如果result_a是整个团队成员都需要权限进行分析的,tongwei可以将权限赋予给团队的角色,即team1,

而且因为tongwei是result_a的所有者,因此授权范围可以包括select、insert、update、delete、all。
完成授权后,hexiang便可以使用tongwei.result_a进行分析,
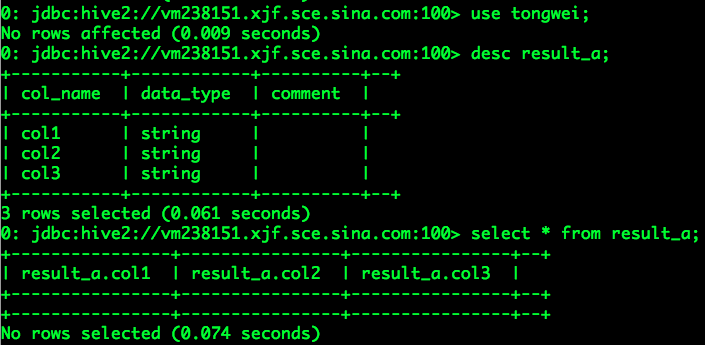
由上所述,我们可以完成同一个团队成员之间的数据(表或视图)共享。不同团队成员之间的数据(表或视图)共享也可以参考上述方式进行,不再赘述。
官方文档Objects小节中有这样一句话:
The privileges apply to table and views. The above privileges are not supported on databases.
也就是说权限的赋予是以表级别或视图级别进行的,不支持数据库级别的授权。这可能会带来同一个团队成员之间或不同团队成员之间共享数据不方便,均需要以表或视图进行相应的授权,但好处是用户的数据(表或视图)更安全。