-
一个Pod一个IP
-
所有的 Pod 可以与任何其他 Pod 直接通信,无需使用 NAT 映射
-
所有节点可以与所有 Pod 直接通信,无需使用 NAT 映射
-
-
网络的命名空间:Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;Docker利用这一特性,实现不同容器间的网络隔离。
-
Veth设备对:Veth设备对的引入是为了实现在不同网络命名空间的通信。
-
Iptables/Netfilter:Docker使用Netfilter实现容器网络转发。
-
网桥:网桥是一个二层网络设备,通过网桥可以将Linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
-
路由:Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。
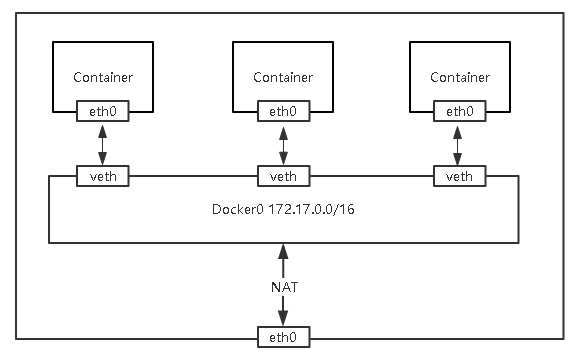
实现:
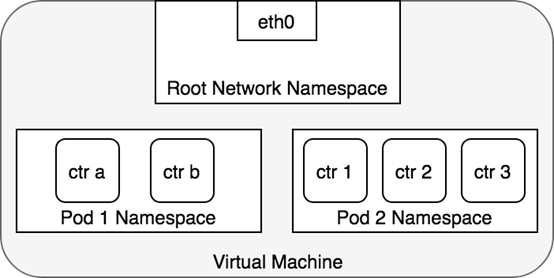
Pod之间通信会有两种情况:
-
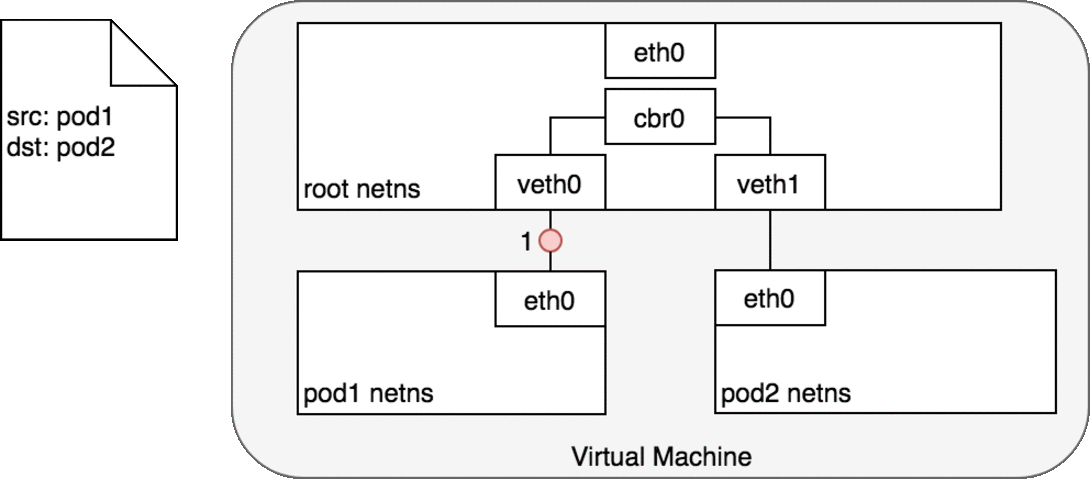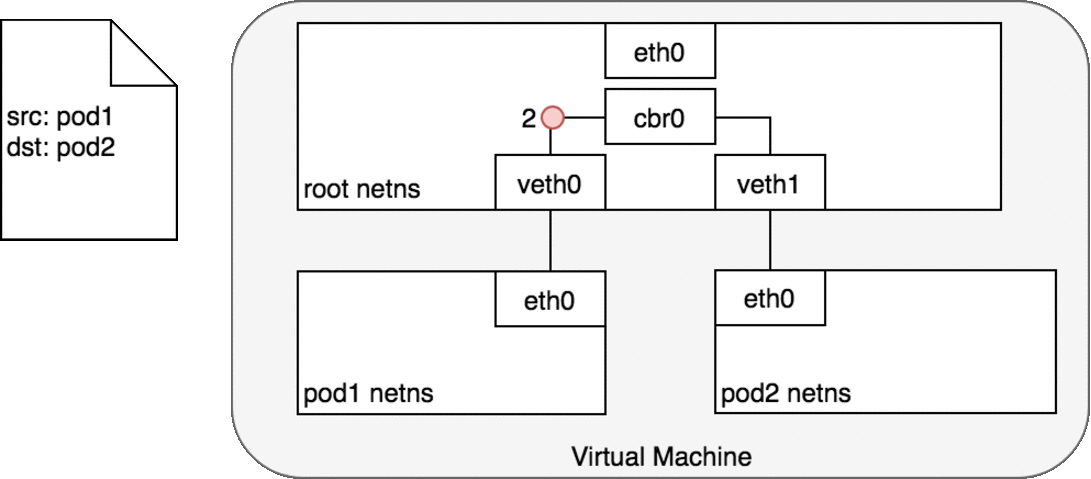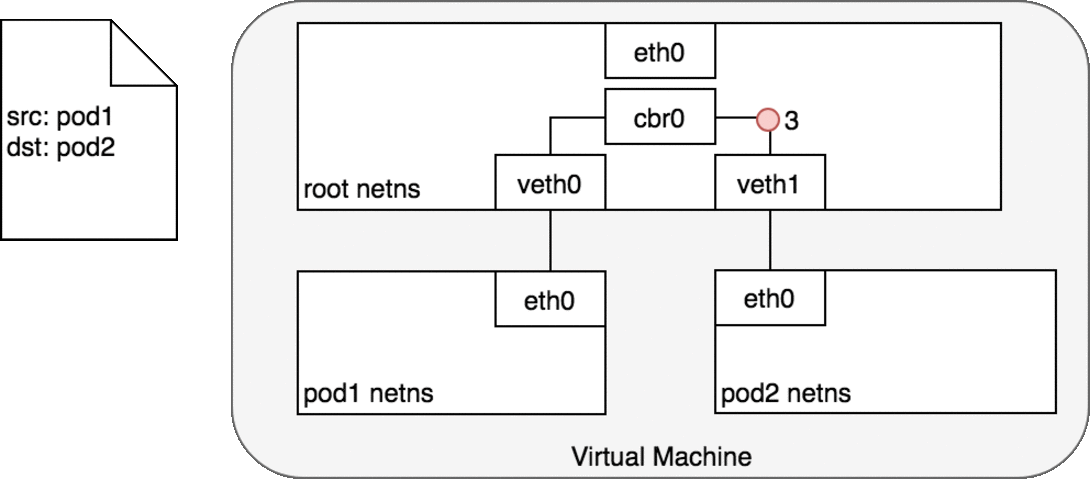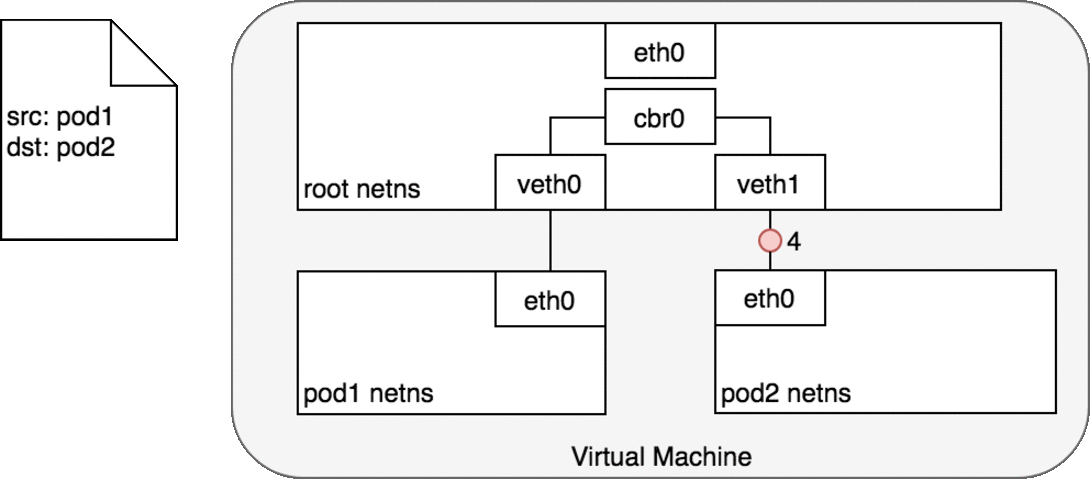
两个Pod在同一个Node上
-
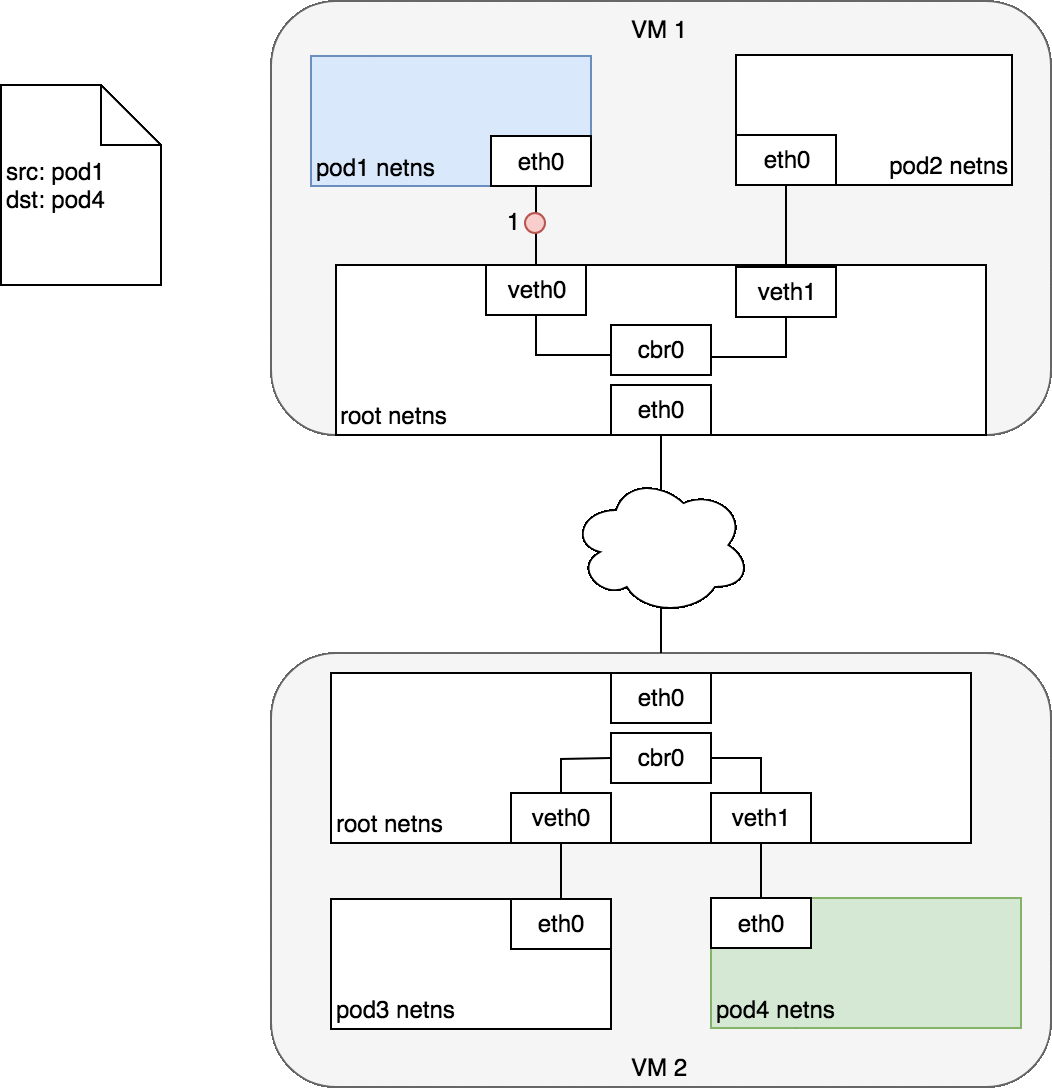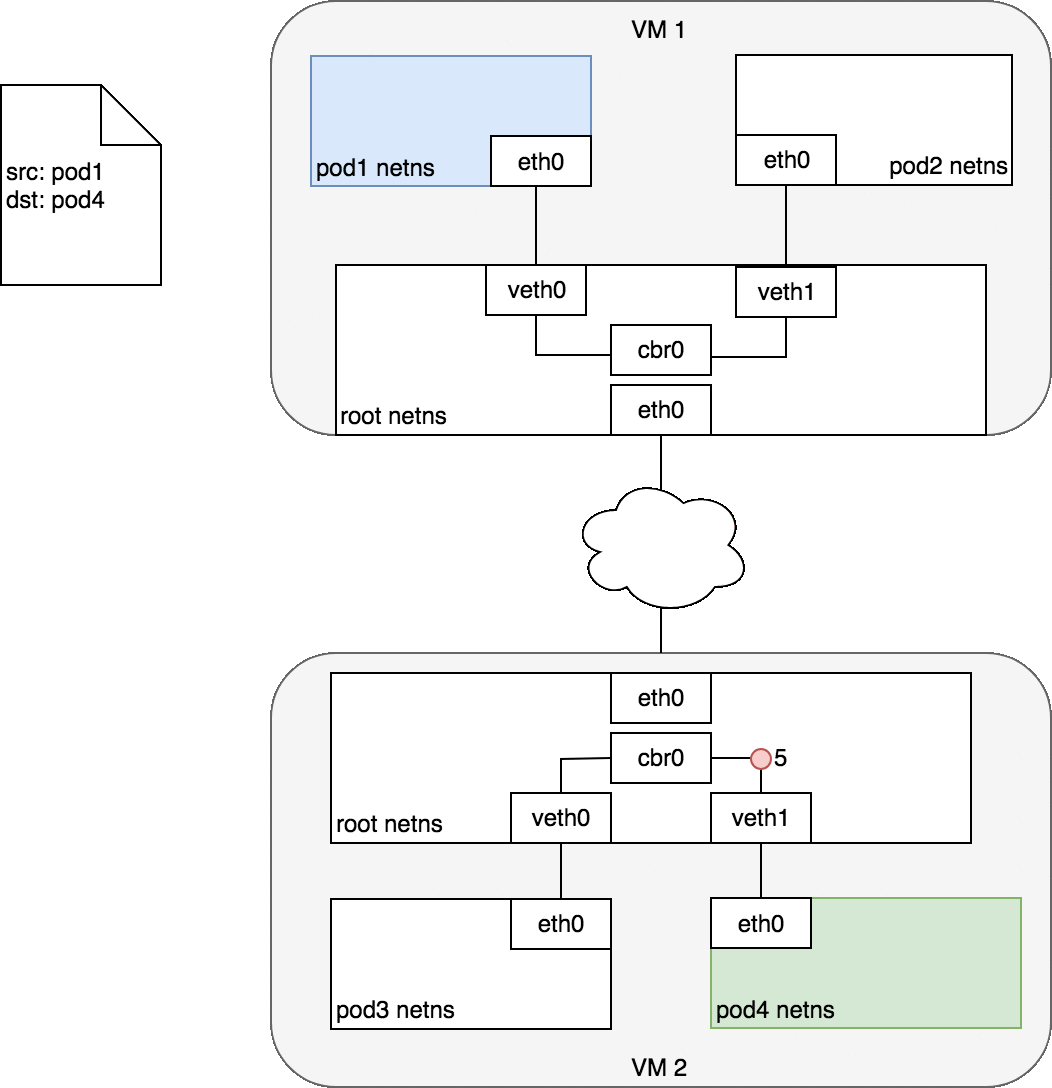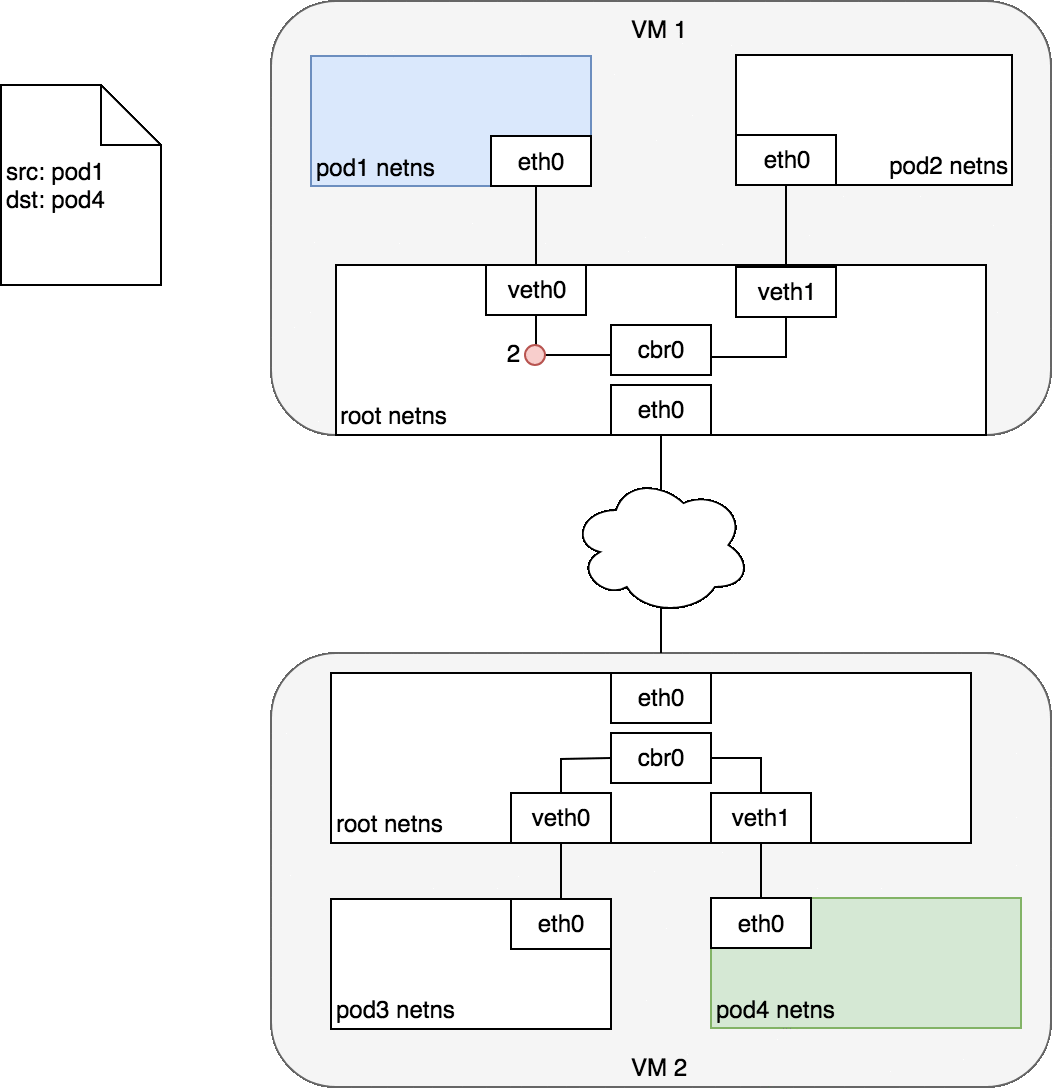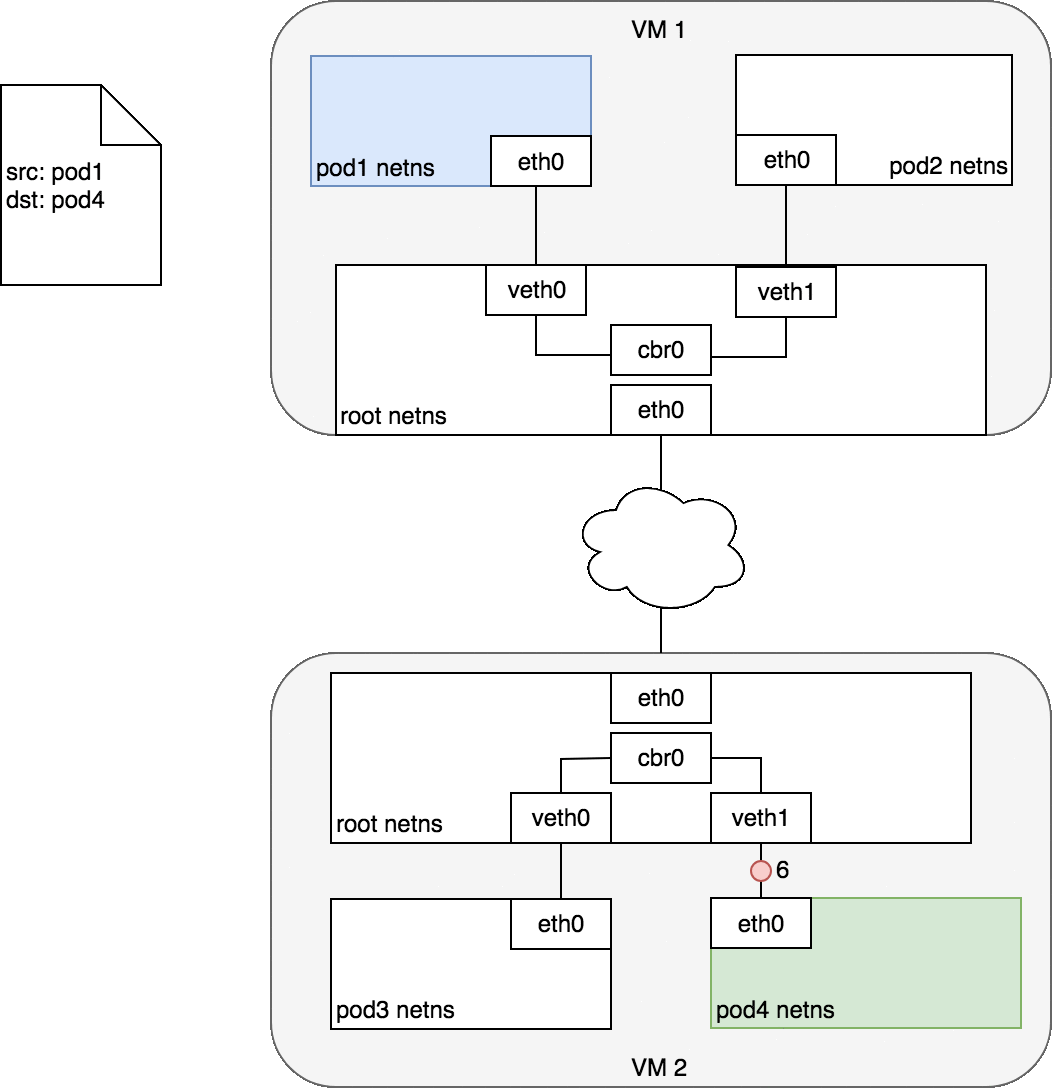
两个Pod在不同Node上
-
-
网桥 cbr0 中为 veth0 配置了一个网段。一旦数据包到达网桥,网桥使用ARP 协议解析出其正确的目标网段 veth1;
-
网桥 cbr0 将数据包发送到 veth1;
-
# ls /opt/cni/bin/
当你在宿主机上部署Flanneld后,flanneld 启动后会在每台宿主机上生成它对应的CNI 配置文件(它其实是一个 ConfigMap),从而告诉Kubernetes,这个集群要使用 Flannel 作为容器网络方案。
/etc/cni/net.d/10-flannel.conflist
--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
-
UDP:最早支持的一种方式,由于性能最差,目前已经弃用。
-
-
Host-GW:Flannel通过在各个节点上的Agent进程,将容器网络的路由信息刷到主机的路由表上,这样一来所有的主机都有整个容器网络的路由数据了。
-
# kubeadm部署指定Pod网段 kubeadm init --pod-network-cidr=10.244.0.0/16 # 二进制部署指定 cat /opt/kubernetes/cfg/kube-controller-manager.conf --allocate-node-cidrs=true --cluster-cidr=10.244.0.0/16 #配置文件 kube-flannel.yml net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } }
为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
如果Pod 1访问Pod 2,源地址10.244.2.250,目的地址10.244.1.33 ,数据包传输流程如下:
1、容器路由:容器根据路由表从eth0发出 # kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-6cd57fd969-4n6fn 1/1 Running 0 61s 10.244.2.50 k8s-master1 <none> <none> web-5675686b8-rc9bf 1/1 Running 0 7m12s 10.244.1.33 k8s-node01 <none> <none> web-5675686b8-rrc6f 1/1 Running 0 7m12s 10.244.2.49 k8s-master1 <none> <none> # kubectl exec -it busybox-6cd57fd969-4n6fn sh / # ip route default via 10.244.2.1 dev eth0 10.244.0.0/16 via 10.244.2.1 dev eth0 10.244.2.0/24 dev eth0 scope link src 10.244.2.51 2、主机路由:数据包进入到宿主机虚拟网卡cni0,根据路由表转发到flannel.1虚拟网卡,也就是,来到了隧道的入口。 # ip route default via 192.168.0.1 dev ens32 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 3、VXLAN封装:而这些VTEP设备(二层)之间组成二层网络必须要知道目的MAC地址。这个MAC地址从哪获取到呢?其实在flanneld进程启动后,就会自动添加其他节点ARP记录,可以通过ip命令查看,如下所示: # ip neigh show dev flannel.1 10.244.0.0 lladdr 06:6a:9d:15:ac:e0 PERMANENT 10.244.1.0 lladdr 36:68:64:fb:4f:9a PERMANENT 4、二次封包:知道了目的MAC地址,封装二层数据帧(容器源IP和目的IP)后,对于宿主机网络来说这个帧并没有什么实际意义。接下来,Linux内核还要把这个数据帧进一步封装成为宿主机网络的一个普通数据帧,好让它载着内部数据帧,通过宿主机的eth0网卡进行传输。 5、封装到UDP包发出去:现在能直接发UDP包嘛?到目前为止,我们只知道另一端的flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。 flanneld进程也维护着一个叫做FDB的转发数据库,可以通过bridge fdb命令查看: # bridge fdb show dev flannel.1 06:6a:9d:15:ac:e0 dst 192.168.0.134 self permanent 36:68:64:fb:4f:9a dst 192.168.0.133 self permanent 可以看到,上面用的对方flannel.1的MAC地址对应宿主机IP,也就是UDP要发往的目的地。使用这个目的IP进行封装。 6、数据包到达目的宿主机:Node1的eth0网卡发出去,发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始二层数据帧包,发送ARP请求,经由cni0网桥转发给container。
# kube-flannel.yml net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "host-gw" } }
当你设置flannel使用host-gw模式,flanneld会在宿主机上创建节点的路由表:
# ip route
default via 192.168.0.1 dev ens32 proto static metric 100
10.244.0.0/24 via 192.168.0.134 dev ens32
10.244.1.0/24 via 192.168.0.133 dev ens32
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.0.0/24 dev ens32 proto kernel scope link src 192.168.0.132 metric 100
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。
# kubectl edit cm kube-flannel-cfg -n kube-system net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" "Directrouting": true } } # kubectl get cm kube-flannel-cfg -o json -n kube-system "net-conf.json": "{ "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" "Directrouting": true } } "
小结:
1、vxlan 不受网络环境限制,只要三层可达就行
2、vxlan 需要二层解封包,降低工作效率
3、hostgw 基于路由表转发,效率更高
4、hostgw 只适用于二层网络(本身网络架构受限,节点数量也受限)
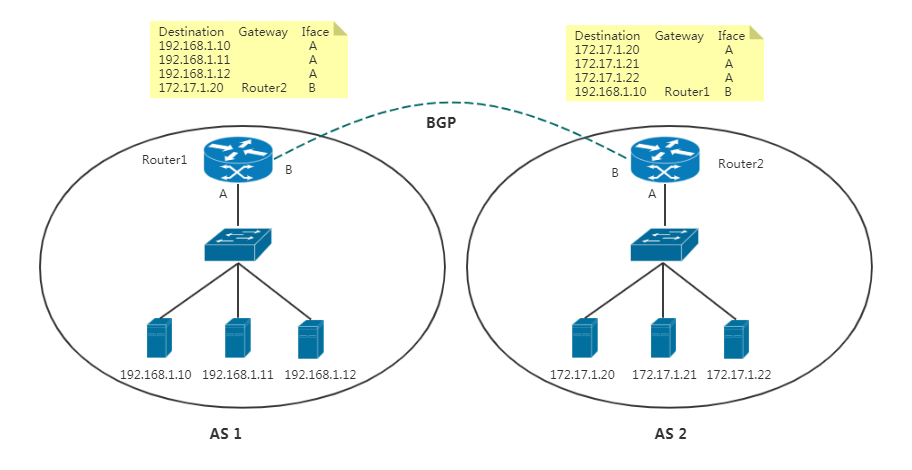
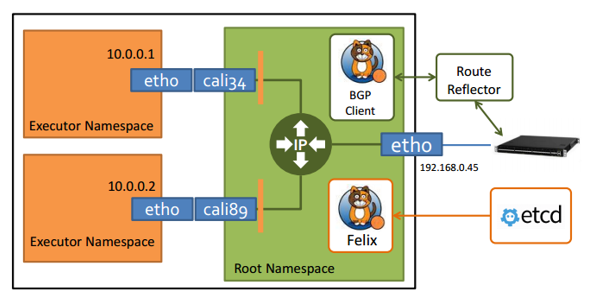
Calico 在每一个计算节点利用 Linux Kernel 实现了一个高效的虚拟路由器( vRouter) 来负责数据转发,而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息向整个 Calico 网络内传播。
BGP英文全称是Border Gateway Protocol,即边界网关协议,它是一种自治系统间的动态路由发现协议,与其他 BGP 系统交换网络可达信息。
-
-
BGP Client(BIRD):主要负责把 Felix 写入 Kernel 的路由信息分发到集群 Calico 网络。
-
Etcd:分布式键值存储,保存Calico的策略和网络配置状态。
-
curl https://docs.projectcalico.org/v3.9/manifests/calico-etcd.yaml -o calico.yaml
具体步骤如下:
-
配置连接etcd地址,如果使用https,还需要配置证书。(ConfigMap,Secret)
-
根据实际网络规划修改Pod CIDR(CALICO_IPV4POOL_CIDR)
-
选择工作模式(CALICO_IPV4POOL_IPIP),支持BGP(Never)、IPIP(Always)、CrossSubnet
# kubectl delete -f kube-flannel.yaml # ip link delete flannel.1 # ip link delete cni0 # ip route del 10.244.2.0/24 via 192.168.0.132 dev ens32 # ip route del 10.244.1.0/24 via 192.168.0.133 dev ens32
应用清单:
# kubectl apply -f calico.yaml
# kubectl get pods -n kube-system
# wget -O /usr/local/bin/calicoctl https://github.com/projectcalico/calicoctl/releases/download/v3.9.1/calicoctl # chmod +x /usr/local/bin/calicoctl # mkdir /etc/calico # vim /etc/calico/calicoctl.cfg apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: datastoreType: "etcdv3" etcdEndpoints: "https://192.168.0.132:2379,https://192.168.0.133:2379,https://192.168.0.134:2379" etcdKeyFile: "/opt/etcd/ssl/server-key.pem" etcdCertFile: "/opt/etcd/ssl/server.pem" etcdCACertFile: "/opt/etcd/ssl/ca.pem"
使用calicoctl查看服务状态:
# calicoctl get node NAME k8s-master k8s-node01 k8s-node02 # calicoctl node status IPv4 BGP status +---------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+-------------------+-------+----------+-------------+ | 192.168.0.133 | node-to-node mesh | up | 07:24:45 | Established | | 192.168.0.134 | node-to-node mesh | up | 07:25:00 | Established | +---------------+-------------------+-------+----------+-------------+ 查看 IPAM的IP地址池: # calicoctl get ippool -o wide NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR default-ipv4-ippool 10.244.0.0/16 true Never Never false all()
-
-
宿主机根据路由规则,将数据包转发给下一跳(网关);
-
到达Node2,根据路由规则将数据包转发给cali设备,从而到达容器2。
# node1 default via 192.168.0.1 dev ens32 proto static metric 100 10.244.0.0/24 via 192.168.0.134 dev ens32 10.244.58.192/26 via 192.168.0.134 dev ens32 proto bird 10.244.85.192 dev calic32fa4483b3 scope link blackhole 10.244.85.192/26 proto bird 10.244.235.192/26 via 192.168.0.132 dev ens32 proto bird # node2 default via 192.168.0.1 dev ens32 proto static metric 100 10.244.58.192 dev calib29fd680177 scope link blackhole 10.244.58.192/26 proto bird 10.244.85.192/26 via 192.168.0.133 dev ens32 proto bird 10.244.235.192/26 via 192.168.0.132 dev ens32 proto bird
# netstat -antp |grep bird tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 23124/bird tcp 0 0 192.168.0.134:44366 192.168.0.132:179 ESTABLISHED 23124/bird tcp 0 0 192.168.0.134:1215 192.168.0.133:179 ESTABLISHED 23124/bird
这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
1、关闭 node-to-node BGP网格
添加 default BGP配置,调整 nodeToNodeMeshEnabled和asNumber:
cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: logSeverityScreen: Info nodeToNodeMeshEnabled: false asNumber: 63400 EOF
ASN号可以通过获取 # calicoctl get nodes --output=wide
为方便让BGPPeer轻松选择节点,通过标签选择器匹配。
kubectl label node k8s-node01 route-reflector=true
然后配置路由器反射器节点routeReflectorClusterID:
# calicoctl get node k8s-node01 -o yaml > rr-node.yaml # vim rr-node.yaml apiVersion: projectcalico.org/v3 kind: Node apiVersion: projectcalico.org/v3 kind: Node metadata: annotations: projectcalico.org/kube-labels: '{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"k8s-node01","kubernetes.io/os":"linux"}' creationTimestamp: 2020-06-04T07:24:40Z labels: beta.kubernetes.io/arch: amd64 beta.kubernetes.io/os: linux kubernetes.io/arch: amd64 kubernetes.io/hostname: k8s-node01 kubernetes.io/os: linux name: k8s-node01 resourceVersion: "50638" uid: 16452357-d399-4247-bc2b-ab7e7eb52dbc spec: bgp: ipv4Address: 192.168.0.133/24 routeReflectorClusterID: 244.0.0.1 orchRefs: - nodeName: k8s-node01 orchestrator: k8s
# calicoctl apply -f bgppeer.yaml
Successfully applied 1 'BGPPeer' resource(s)
现在,很容易使用标签选择器将路由反射器节点与其他非路由反射器节点配置为对等:
# vi bgppeer.yaml apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: peer-with-route-reflectors spec: nodeSelector: all() peerSelector: route-reflector == 'true'
# calicoctl apply -f bgppeer.yaml
Successfully applied 1 'BGPPeer' resource(s)
查看节点的BGP连接状态:
# calicoctl node status Calico process is running. IPv4 BGP status +---------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+---------------+-------+----------+-------------+ | 192.168.0.133 | node specific | up | 09:54:05 | Established | +---------------+---------------+-------+----------+-------------+
# calicoctl get ipPool -o yaml > ipip.yaml # vim ipip.yaml apiVersion: projectcalico.org/v3 items: - apiVersion: projectcalico.org/v3 kind: IPPool metadata: creationTimestamp: 2020-06-04T07:24:39Z name: default-ipv4-ippool resourceVersion: "50630" uid: e6515b21-44eb-4de9-8dc2-42f291da4273 spec: blockSize: 26 cidr: 10.244.0.0/16 ipipMode: Always natOutgoing: true nodeSelector: all() vxlanMode: Never kind: IPPoolList metadata: resourceVersion: "76218" # calicoctl apply -f ipip.yaml Successfully applied 1 'IPPool' resource(s) # calicoctl get ippool -o wide NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR default-ipv4-ippool 10.244.0.0/16 true Always Never false all()
-
数据包从容器1出到达Veth Pair另一端(宿主机上,以cali前缀开头);
-
进入IP隧道设备(tunl0)由Linux内核IPIP驱动封装在宿主机网络的IP包中(新的IP包目的地之是原IP包的下一跳地址),这样就成了Node1 到Node2的数据包;
-
数据包经过路由器三层转发到Node2;
-
Node2收到数据包后,网络协议栈会使用IPIP驱动进行解包,从中拿到原始IP包;
-
# node01 10.244.58.192/26 via 192.168.0.134 dev tunl0 proto bird onlink 10.244.85.192 dev calic32fa4483b3 scope link # node02 10.244.58.192 dev calib29fd680177 scope link 10.244.85.192/26 via 192.168.0.133 dev tunl0 proto bird onlink
不难看到,当 Calico 使用 IPIP 模式的时候,集群的网络性能会因为额外的封包和解包工作而下降。所以建议你将所有宿主机节点放在一个子网里,避免使用 IPIP。
-
需要细粒度网络访问控制?
-
追求网络性能?
-
服务器之前是否可以跑BGP协议?
-
集群规模多大?
-
-
应用程序间的访问控制。例如微服务A允许访问微服务B,微服务C不能访问微服务A
-
开发环境命名空间不能访问测试环境命名空间Pod
-
当Pod暴露到外部时,需要做Pod白名单
-
多租户网络环境隔离
所以,我们需要使用network policy对Pod网络进行隔离。支持对Pod级别和Namespace级别网络访问控制。
Pod网络入口方向隔离
-
基于Pod级网络隔离:只允许特定对象访问Pod(使用标签定义),允许白名单上的IP地址或者IP段访问Pod
-
基于Namespace级网络隔离:多个命名空间,A和B命名空间Pod完全隔离。
Pod网络出口方向隔离
-
-
基于目的IP的网络隔离:只允许Pod访问白名单上的IP地址或者IP段
-
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy namespace: default spec: podSelector: matchLabels: role: db policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978
-
podSelector:用于选择策略应用到的Pod组。
-
-
Ingress:from是可以访问的白名单,可以来自于IP段、命名空间、Pod标签等,ports是可以访问的端口。
-
# kubectl create deployment web --image=nginx # kubectl run client1 --generator=run-pod/v1 --image=busybox --command -- sleep 36000 # kubectl run client2 --generator=run-pod/v1 --image=busybox --command -- sleep 36000 # kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS client1 1/1 Running 0 49s run=client1 client2 1/1 Running 0 49s run=client2 web-5886dfbb96-8mkg9 1/1 Running 0 136m app=web,pod-template-hash=5886dfbb96 web-5886dfbb96-hps6t 1/1 Running 0 136m app=web,pod-template-hash=5886dfbb96 web-5886dfbb96-lckfs 1/1 Running 0 136m app=web,pod-template-hash=5886dfbb96
需求:将default命名空间携带run=web标签的Pod隔离,只允许default命名空间携带run=client1标签的Pod访问80端口
# vim pod-acl.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy namespace: default spec: podSelector: matchLabels: app: web policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: project: default - podSelector: matchLabels: run: client1 ports: - protocol: TCP port: 80 # kubectl apply -f pod-acl.yaml
测试
# kubectl exec -it client1 sh / # wget 10.244.85.192 Connecting to 10.244.85.192 (10.244.85.192:80) saving to 'index.html' index.html 100% |**************************************************************************************************************| 612 0:00:00 ETA 'index.html' saved # kubectl exec -it client2 sh / # wget 10.244.85.192 Connecting to 10.244.85.192 (10.244.85.192:80) wget: can't connect to remote host (10.244.85.192): Connection timed out
Pod对象:default命名空间携带run=web标签的Pod
允许访问端口:80
允许访问对象:default命名空间携带run=client1标签的Pod
# kubectl create ns test namespace/test created # kubectl create deployment web --image=nginx -n test deployment.apps/web created # kubectl run client -n test --generator=run-pod/v1 --image=busybox --command -- sleep 36000 # vim ns-acl.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-from-other-namespaces namespace: default spec: podSelector: {} policyTypes: - Ingress ingress: - from: - podSelector: {} # kubectl apply -f ns-acl.yaml # kubectl get pod -n test -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES client 1/1 Running 0 119s 10.244.85.195 k8s-node01 <none> <none> web-d86c95cc9-gr88v 1/1 Running 0 10m 10.244.235.198 k8s-master1 <none> <none> [root@k8s-master ~]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-5886dfbb96-8mkg9 1/1 Running 0 158m 10.244.235.193 k8s-master1 <none> <none> web-5886dfbb96-hps6t 1/1 Running 0 158m 10.244.85.192 k8s-node01 <none> <none> web-5886dfbb96-lckfs 1/1 Running 0 158m 10.244.58.192 k8s-node02 <none> <none> # kubectl exec -it client -n test sh / # wget 10.244.58.192 Connecting to 10.244.58.192 (10.244.58.192:80) wget: can't connect to remote host (10.244.58.192): Connection timed out / # wget 10.244.235.198 Connecting to 10.244.235.198 (10.244.235.198:80) saving to 'index.html' index.html 100% |**************************************************************************************************************| 612 0:00:00 ETA 'index.html' saved