要搭建TensorFlow的GPU版本,首先需要的必备条件就是一块能够支持CUDA的NVIDIA显卡,因为在搭建TensorFlow的GPU版本时,首先需要做的一件事就是安装其基础支持平台CUDA和其机器学习库cuDNN,然后在此基础上搭建TensorFlow GPU版本。
其次还要了解一下不同的TensorFlow版本所需要对应安装的CUDA和cuDNN版本是多少,因为在TensorFlow的GPU版本安装过程中,如果对应的CUDA版本和cuDNN版本不正确的话,是无法正常使用GPU来进行模型训练的。下表整理出了TensorFlow从1.2到最新版本的CUDA和cuDNN所对应的版本集合
要想成功安装tensorflow并提供GPU支持,必须保证tensorflow、cudatoolkit、cudnn版本对应。
查看tensorflow娱cuda cudnn版本对应关系
https://www.tensorflow.org/install/source_windows
Windows系统查看CUDA版本号
检查硬件支持。
点击如图所示的图标打开nvidia控制面板。
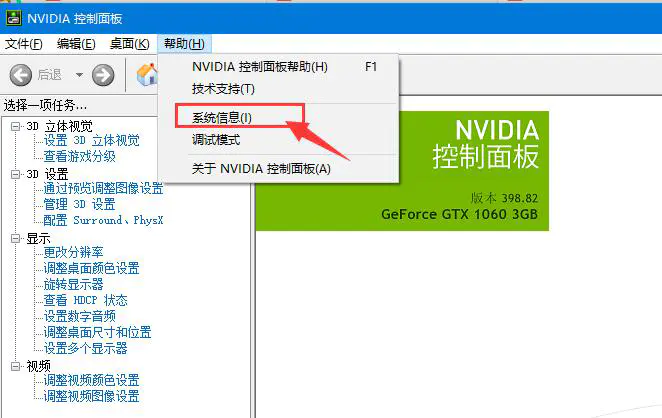
点击组件按钮,如下图红色箭头标注处所示。
在红色方框和红色文字共同标注处则显示当前电脑的CUDA版本号

知道自己电脑的CUDA版本号,则可以 选择合适版本的CUDA Toolkit
安装cuda toolkit
各种历史版本:https://developer.nvidia.com/cuda-toolkit-archive
选择合适的cuda toolkit,下载好,双击下载好的文件,会提示选择目录释放临时文件,直接点击下一步即可。
安装好后,打开anaconda的terminal输入
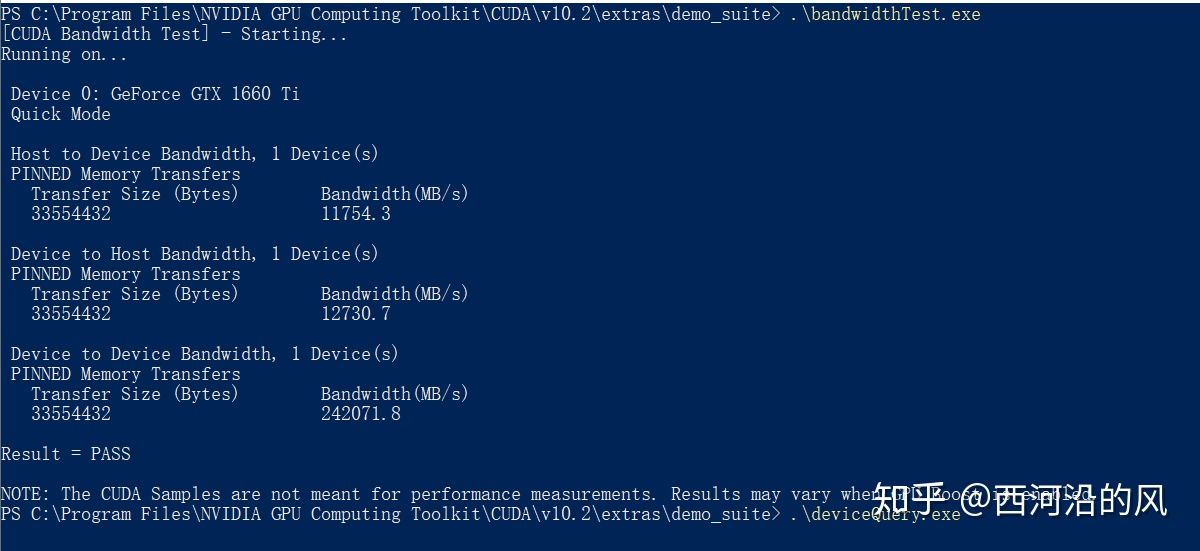
nvcc -V进行测试,如果显示如下,证明你安装成功了。

安装cudnn
cuDNN
是一个SDK,是一个专门用于神经网络的加速包,注意,它跟我们的CUDA没有一一对应的关系,即每一个版本的CUDA可能有好几个版本的cuDNN与之对应,但一般有一个最新版本的cuDNN版本与CUDA对应更好。
- cuDNN与CUDA没有版本绑定的关系。
1、下载cudnn 按图片所示操作即可。注意,可能会要求需要注册账号。
cuddn各种历史版本:
https://developer.nvidia.com/rdp/cudnn-archive
解压cuDNN压缩包,可以看到bin、include、lib目录,
打开 C:Program FilesNVIDIA GPU Computing ToolkitCUDA
将下载文件解压,然后 copy------》past
按照自己的情况来,图中是我的解压和安装路径:(注意是路径中的文件)

需要添加下面两个路径,这就是说为什么要记住你的安装路径了,我使用的是默认的安装路径。
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.2
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.2libx64
注意:选择你安装的路径
5、检查安装结果
打开 C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.2extrasdemo_suite
在此路径下打开powershell
‘
参考:https://zhuanlan.zhihu.com/p/94220564
’https://www.jianshu.com/p/622f47f94784
https://blog.csdn.net/qq_27825451/article/details/89082978
安装tensorflow gpu版本
conda create -n tf2.3
可以先搜索tensorflow-gpu版本有哪些
conda install tensorflow-gpu=2.3
测试:
import tensorflow as tf version = tf.__version__ gpu_ok = tf.test.is_gpu_availableI() print("tf version:",version,"nuse GPU",gpu_ok)
结果 输出了false,为什么?
一篇文章:https://blog.csdn.net/flana/article/details/104772614/
我已经设置了把PhysX设置固定为独立显卡。 但还是false,可能是tf的版本和cuda,cudnn匹配不上。
TensorFlow-GPU简单安装的方法
查看tf对应的cuda和cuddn版本:https://www.tensorflow.org/install/source_windows
建立虚拟环境:
conda create -n your_env_name(虚拟环境名) python=x.x(先要的python版本)
激活虚拟环境:
activate your_env_name(虚拟环境名)
安装TensorFlow对应版本的CUDA和cuDNN:
conda install cudatoolkit=10.1 cudnn=7.6.5
安装对应版本的TensorFlow-GPU:
pip install tensorflow-gpu==xxx -i
我通过这种方法运行测试程序,is gpu ok输出了True,成功。
https://www.bilibili.com/read/cv10593154
cuda卸载:
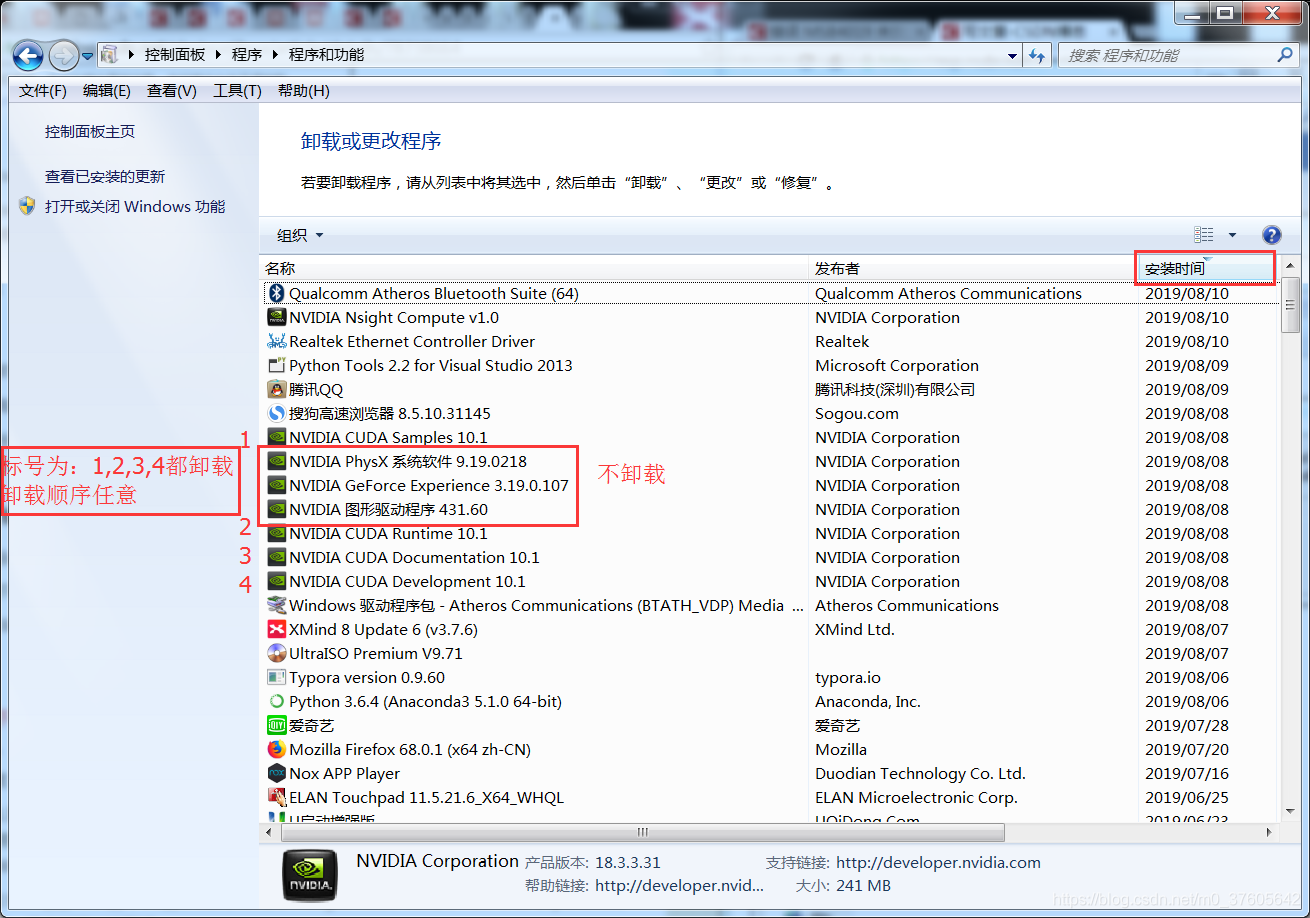
(1)留下:NVIDIA的图形驱动程序、NVIDIA Physx系统软件、NVIDIA GeForce Experience
-
CUDA和显卡驱动是没有版本绑定关系。
显卡驱动下载地址: https://www.nvidia.com/Download/index.aspx?lang=en-us
CUDA的下载地址为:https://developer.nvidia.com/cuda-downloads
- 显卡: 简单理解这个就是我们前面说的GPU,尤其指NVIDIA公司生产的GPU系列,因为后面介绍的cuda,cudnn都是NVIDIA公司针对自身的GPU独家设计的。
- 显卡驱动:很明显就是字面意思,通常指NVIDIA Driver,其实它就是一个驱动软件,而前面的显卡就是硬件。
- gpu架构:Tesla、Fermi、Kepler、Maxwell、Pascal
- 芯片型号:GT200、GK210、GM104、GF104等
- 显卡系列:GeForce、Quadro、Tesla
- GeForce显卡型号:G/GS、GT、GTS、GTX
gpu架构指的是硬件的设计方式,例如流处理器簇中有多少个core、是否有L1 or L2缓存、是否有双精度计算单元等等。每一代的架构是一种思想,如何去更好完成并行的思想
芯片就是对上述gpu架构思想的实现,例如芯片型号GT200中第二个字母代表是哪一代架构,有时会有100和200代的芯片,它们基本设计思路是跟这一代的架构一致,只是在细节上做了一些改变,例如GK210比GK110的寄存器就多一倍。有时候一张显卡里面可能有两张芯片,Tesla k80用了两块GK210芯片。这里第一代的gpu架构的命名也是Tesla,但现在基本已经没有这种设计的卡了,下文如果提到了会用Tesla架构和Tesla系列来进行区分。
而显卡系列在本质上并没有什么区别,只是NVIDIA希望区分成三种选择,GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用于服务器。Tesla的k型号卡为了高性能科学计算而设计,比较突出的优点是双精度浮点运算能力高并且支持ECC内存,但是双精度能力好在深度学习训练上并没有什么卵用,所以Tesla系列又推出了M型号来做专门的训练深度学习网络的显卡。需要注意的是Tesla系列没有显示输出接口,它专注于数据计算而不是图形显示。
最后一个GeForce的显卡型号是不同的硬件定制,越往后性能越好,时钟频率越高显存越大,即G/GS<GT<GTS<GTX。
CUDA名称含义
CUDA
看了很多答案,有人说CUDA就是一门编程语言,像C,C++,python 一样,也有人说CUDA是API。CUDA英文全称是Compute Unified Device Architecture,是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。按照官方的说法是,CUDA是一个并行计算平台和编程模型,能够使得使用GPU进行通用计算变得简单和优雅。

cudnn
这个其实就是一个专门为深度学习计算设计的软件库,里面提供了很多专门的计算函数,如卷积等。从上图也可以看到,还有很多其他的软件库和中间件,包括实现c++ STL的thrust、实现gpu版本blas的cublas、实现快速傅里叶变换的cuFFT、实现稀疏矩阵运算操作的cuSparse以及实现深度学习网络加速的cuDNN等等,具体细节可参阅GPU-Accelerated Libraries
CUDA Toolkit
CUDA Toolkit由以下组件组成:
- Compiler: CUDA-C和CUDA-C++编译器
NVCC位于bin/目录中。它建立在NVVM优化器之上,而NVVM优化器本身构建在LLVM编译器基础结构之上。希望开发人员可以使用nvm/目录下的Compiler SDK来直接针对NVVM进行开发。 - Tools: 提供一些像
profiler,debuggers等工具,这些工具可以从bin/目录中获取 - Libraries: 下面列出的部分科学库和实用程序库可以在
lib/目录中使用(Windows上的DLL位于bin/中),它们的接口在include/目录中可获取。- cudart: CUDA Runtime
- cudadevrt: CUDA device runtime
- cupti: CUDA profiling tools interface
- nvml: NVIDIA management library
- nvrtc: CUDA runtime compilation
- cublas: BLAS (Basic Linear Algebra Subprograms,基础线性代数程序集)
- cublas_device: BLAS kernel interface
- ...
- CUDA Samples: 演示如何使用各种CUDA和library API的代码示例。可在Linux和Mac上的
samples/目录中获得,Windows上的路径是C:ProgramDataNVIDIA CorporationCUDA Samples中。在Linux和Mac上,samples/目录是只读的,如果要对它们进行修改,则必须将这些示例复制到另一个位置。 - CUDA Driver: 运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU和与CUDA工具包兼容的驱动程序。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方安装最新版本的Driver。 目前(2019年10月)的CUDA Toolkit和CUDA Driver版本的对应情况如下:
|
CUDA Toolkit |
Linux x86_64 Driver Version |
Windows x86_64 Driver Version |
|---|---|---|
|
CUDA 10.1 (10.1.105 general release, and updates) |
>= 418.39 |
>= 418.96 |
|
CUDA 10.0.130 |
>= 410.48 |
>= 411.31 |
|
CUDA 9.2 (9.2.148 Update 1) |
>= 396.37 |
>= 398.26 |
|
CUDA 9.2 (9.2.88) |
>= 396.26 |
>= 397.44 |
|
CUDA 9.1 (9.1.85) |
>= 390.46 |
>= 391.29 |
|
CUDA 9.0 (9.0.76) |
>= 384.81 |
>= 385.54 |
|
CUDA 8.0 (8.0.61 GA2) |
>= 375.26 |
>= 376.51 |
|
CUDA 8.0 (8.0.44) |
>= 367.48 |
>= 369.30 |
|
CUDA 7.5 (7.5.16) |
>= 352.31 |
>= 353.66 |
|
CUDA 7.0 (7.0.28) |
>= 346.46 |
>= 347.62 |
nvcc&nvidia-smi
nvcc
这个在前面已经介绍了,nvcc其实就是CUDA的编译器,可以从CUDA Toolkit的/bin目录中获取,类似于gcc就是c语言的编译器。由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,一种是运行在gpu上的device代码,所以nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行。nvcc涉及到的文件后缀及相关意义如下表
|
文件后缀 |
意义 |
|---|---|
|
.cu |
cuda源文件,包括host和device代码 |
|
.cup |
经过预处理的cuda源文件,编译选项--preprocess/-E |
|
.c |
c源文件 |
|
.cc/.cxx/.cpp |
c++源文件 |
|
.gpu |
gpu中间文件,编译选项--gpu |
|
.ptx |
类似汇编代码,编译选项--ptx |
|
.o/.obj |
目标文件,编译选项--compile/-c |
|
.a/.lib |
库文件,编译选项--lib/-lib |
|
.res |
资源文件 |
|
.so |
共享目标文件,编译选项--shared/-shared |
|
.cubin |
cuda的二进制文件,编译选项-cubin |
nvidia-smi
nvidia-smi全程是NVIDIA System Management Interface ,它是一个基于前面介绍过的NVIDIA Management Library(NVML)构建的命令行实用工具,旨在帮助管理和监控NVIDIA GPU设备。
nvcc和nvidia-smi显示的CUDA版本不同?
在我们实验室的服务器上nvcc --version显示的结果如下:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Tue_Jun_12_23:07:04_CDT_2018
Cuda compilation tools, release 9.2, V9.2.148
而nvidia-smi显示结果如下:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:01:00.0 Off | Off |
| N/A 28C P0 26W / 250W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-PCIE... On | 00000000:02:00.0 Off | Off |
| N/A 24C P0 30W / 250W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------