RabbitMQ概述
MQ的应用场景:异步,削峰,解耦
RabbitMQ是遵从AMQP协议的 通信协议都设计到报文交互,换句话说RabbitMQ就是AMQP协议的Erlang的实现。
AMQP说到底还是一个通信协议从low-level层面举例来说,AMQP本身是应用层的协议,其填充于TCP协议的数据部分。
从high-level层面来说,AMQP是通过协议命令进行交互的。命令类似HTTP中的方法(GET PUT POST DELETE等)。
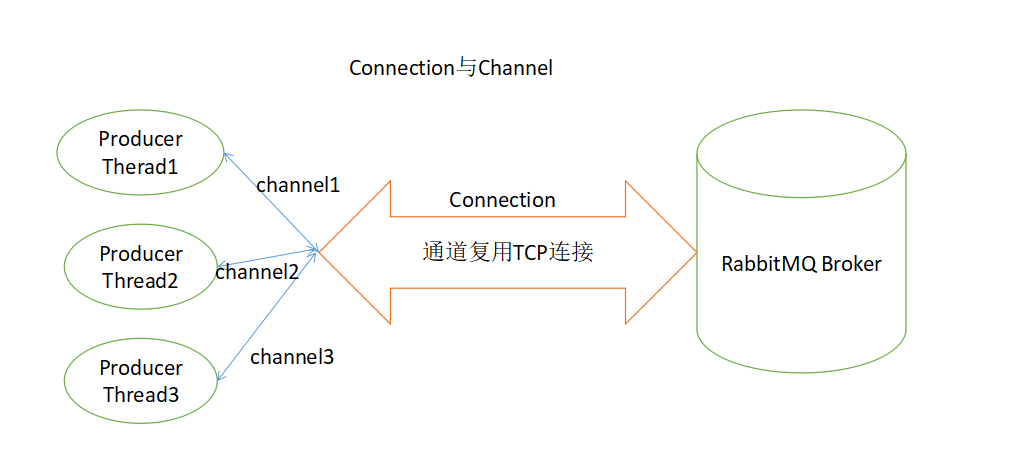
信道(Channel)在AMQP是一个很重要的概念,大多数操作都是在信道这个层面展开的
我们完全可以用Connection就能完成信道的工作,为什么还要引入信道?
试想:一个程序中有很多个线程需要从RabbitMQ中消费消息,或者生产消息,那么必然需要建立很多个Connection,也就是多个TCP连接。
建立和销毁TCP连接开销很昂贵。所以RabbitMQ采用类似NIO的做法,选择TCP连接复用。不仅可以减少性能开销,同时也便于管理。
我们知道无论是生产者还是消费者,都需要和 RabbitMQ Broker 建立连接,这个连接就是一条 TCP 连接,也就是 Connection。
一旦 TCP 连接建立起来,客户端紧接着可以创建一个 AMQP 信道(Channel),每个信道都会被指派一个唯一的 ID。
信道是建立在 Connection 之上的虚拟连接,RabbitMQ 处理的每条 AMQP 指令都是通过信道完成的。
发布订阅模式
广播模式 fanout
所谓广播指的是一条消息将被所有的消费者进行处理。
直连模式 director
直连模式的特点主要就是routingkey的使用,如果现在该消息就要求指定一个具备有指定Routingkey的操作者进行处理,那么只需要两个的Routingkey匹配即可。
可以将Routingkey比喻一个唯一标记,这样就可以将消息准确的推送到消费者手中了。
主题模式 topic
主题模式类似于广播模式与直连模式的整合操作,所有的消费者都可以接收到主题信息,但是如果要想进行正确的处理,则一定需要有一个匹配的Routingkey完成操作。
可以使用通配符模糊匹配("#"匹配一个或多个词,"*"匹配不多不少一个词)
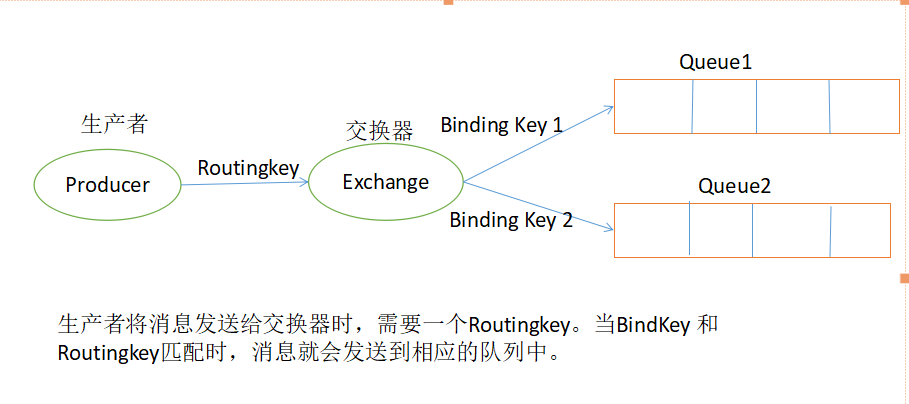
交换器相当于投递包裹的邮箱(一方面接收生产者发送的消息,另外一方面负责向队列进行消息的推送),Routingkey相当于包裹的地址,BindingKey相当于包裹的目的地。
当填写在包裹上的地址和要投递的地址相匹配时,那么这个包裹就会正确投递到目的地,最后这个目的地的主人(队列)可以保留这个包裹。
如果填写地址出错,邮递员不能正确的投递到目的地,包裹可能被退回给寄件人,也有可能被丢弃。
RabbitMQ官方文档和API都把Routingkey和BingdingKey都看做Routingkey下面代码中红色部分 就都当Routingkey使用
消息生产者
public class MessageProducer { private static final String EXCHANGE_NAME ="com.sunkun.topic";//消息队列名称 private static final String HOST="192.168.1.105"; private static final int PORT=5672; public static void main(String[] args) throws Exception { ConnectionFactory factory = new ConnectionFactory();//建立一个连接工厂 factory.setHost(HOST); factory.setPort(PORT); factory.setUsername("sunkun"); factory.setPassword("123456"); //factory.setVirtualHost(virtualHost) 使用虚拟主机的最大好处 可以区分不同用户的操作空间 每一个虚拟主机有一个自己的空间管理 Connection conn = factory.newConnection();//定义一个新的RabbitMQ的连接 Channel channel = conn.createChannel();//创建一个通讯的通道 //定义该通道要使用的队列名称 此时队列已经创建过了 //第一个参数 队列名称(这个队列可能存在也可能不存在) //第二个参数 是否持久保存 //第三个参数 此队列是否为专用的队列信息 //第四个参数 是否允许自动删除 //channel.queueDeclare(QUENE_NAME, true, false, true,null); channel.exchangeDeclare(EXCHANGE_NAME, "topic",true); long start = System.currentTimeMillis(); System.out.println("消息开始"+start); for(int i=0;i<1000;i++){ String message = "sk - "+i; if(i%2==0){ //MessageProperties.PERSISTENT_TEXT_PLAIN 消息持久化 channel.basicPublish(EXCHANGE_NAME, "sk1", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());//进行消息发送 }else{ channel.basicPublish(EXCHANGE_NAME, "sk2", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());//进行消息发送 } } long end = System.currentTimeMillis(); System.out.println("消息花费时间"+(end-start)); channel.close(); } }
消息消费者
public class MessageConsumer { private static final String EXCHANGE_NAME ="com.sunkun.topic";//消息队列名称 private static final String HOST="192.168.1.105"; private static final int PORT=15672; public static void main(String[] args) throws Exception { ConnectionFactory factory = new ConnectionFactory();//建立一个连接工厂 factory.setHost(HOST); factory.setPort(PORT); factory.setUsername("sunkun"); factory.setPassword("123456"); Connection conn = factory.newConnection();//定义一个新的RabbitMQ的连接 Channel channel = conn.createChannel();//创建一个通讯的通道 channel.exchangeDeclare(EXCHANGE_NAME, "topic"); String queueName = channel.queueDeclare().getQueue();//通过通道获取一个队列名称 channel.queueBind(queueName, EXCHANGE_NAME, "sk2");//进行绑定处理 //在RabbitMQ里面,所有的消费者信息是通过一个回调方法完成的 Consumer consumer = new DefaultConsumer(channel){//需要复写指定的方法实现消息处理 @Override public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties, byte[] body) throws IOException { String message = new String(body); System.out.println("消费者sk2:"+message);//可以启动多个消费者 super.handleDelivery(consumerTag, envelope, properties, body); } }; channel.basicConsume(queueName,consumer); } }
RabbitMQ可靠性投递—保证消息成功发出
持久化可以提高RabbitMQ的可靠性,防止在异常情况(重启,关闭,宕机)下的数据丢失。
持久化可分为三个部分:交换器的持久化,队列的持久化和消息的持久化。从上面的代码可以看到,生产者如果往交换器发消息,然后和消费者和队列绑定,是不需要我们显示的声明队列的(也就没必要设置队列的持久化)。
交换器的持久化:是通过声明交换器时将druable参数设置为true来实现的。如果交换器不设置持久化,那么在RabbitMQ重启之后相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器中了。
对于一个长期使用的交换器来说,建议其置为持久化。(消息不直接往队列发,先往exchange发送 可以实现广播模式)
队列的持久化:是通过声明队列时将durable参数置为true实现的(和交换器的持久化类似)。如果队列不设置持久化,那么在RabbitMQ服务重启之后,相关队列的元数据会丢失,此时数据也会丢失。
消息的持久化:因为队列的持久化能保证其本身的元数据不会因为异常情况而丢失,但是不能保证内部存储的消息不会丢失。要确保消息不会丢失,需求将其设置为持久化。
消息的持久化是指当消息从交换机发送到队列之后,被消费者消费之前,服务器突然宕机重启,消息仍然存在。消息持久化的前提是队列持久化,假如队列不是持久化,那么消息的持久化毫无意义。
消息的持久化是设置Properties为MessageProperties.PERSITANT_TEXT_PLAIN,
RabbitMQ集群—保证mqbroker节点的成功接收
在持久化的消息正确存入到RabbitMQ之后 还需要一段时间(虽然时间很短,但不可忽视)才能存入磁盘中,如果这段时间发生了宕机,消息保存还没来得及落盘,那么这些消息将会丢失。
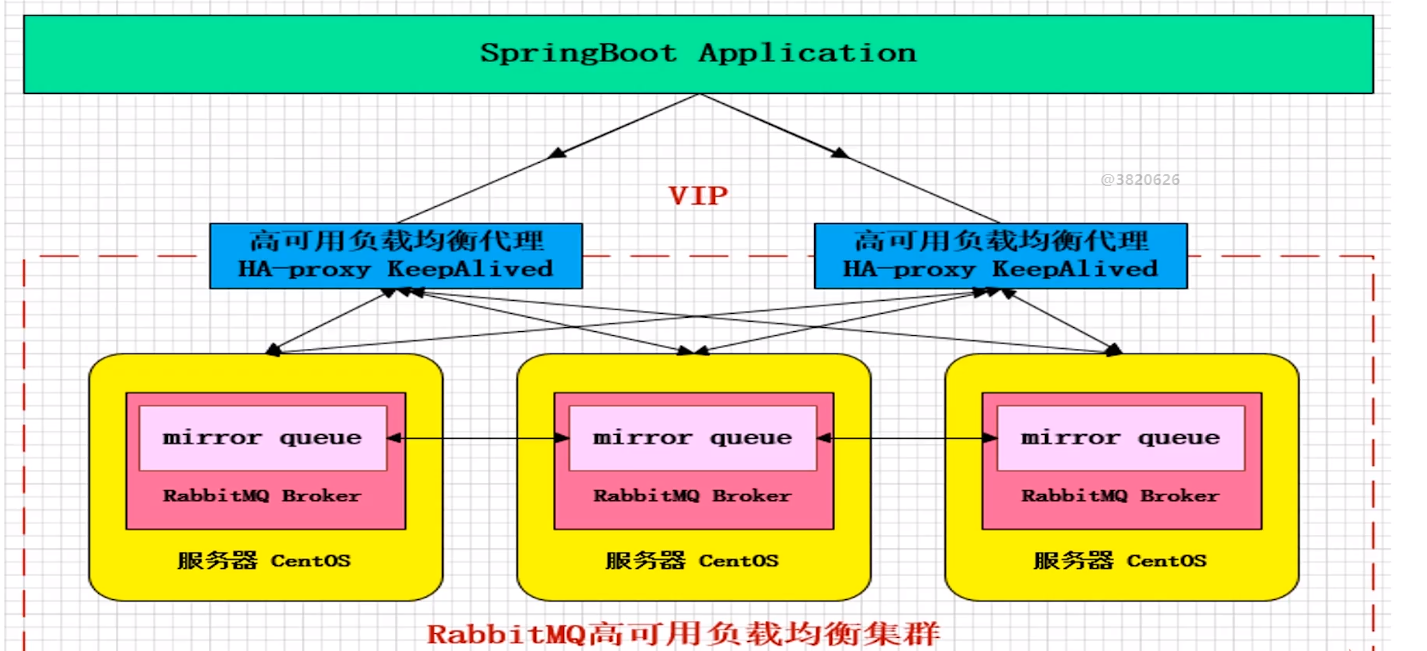
可靠性投递,是为了保证消息能够100%到达mqbroker,而镜像队列是为了保证mqbroker出现意外情况,断电,宕机,磁盘损耗而不丢失数据。保障MQ节点成功接收
本文主要讲镜像队列
镜像队列只是进行数据的副本拷贝 (主从集群仅仅是数据备份,做不到故障转移),当外部发送过的消息首先落到我们的主服务器上,然后主服务器把数据同步到另外的两个节点上,
这就是镜像队列,可以保证数据百分之百的不丢失(主节点挂了还有两个从节点)
如果想要安全的使用RabbitMQ就要继续追加负载均衡组件,列如HAProxy LVS等等,如果要保证负载均衡组件的高可用,还应该继续追加KeepAlive或者ZooKeeper组件。
生产者确认—发送端收到MQ节点(Broker)确认应答
除上面两个问题外 我们还遇到一个新问题:当消息的生产者将消息发送出去之后,消息到底有没有正确的到达服务器呢?
如果消息到达服务器之前就丢失,那么持久化也解决不了问题,因为消息就没有到达服务器,何谈持久化呢。
通常会有两种方法解决此问题一时事物机制,只有消息被成功接收,事物才能提交成功,否则便可在捕获异常之后进行事物回滚,于此同时可以进行消息重发。
但使用事物机制会大大降低RabbitMQ的性能,我们一般采取发送方确认机制。
发送方确认机制:生产者将信道设置成confirm模式(channel.confirmSelect()),一旦信道进入confirm模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1开始),
一旦消息被投递到所有的匹配队列之后,RabbitMQ就会发送一个确认给生产者(包含消息的唯一ID),这就使得生产者知晓消息已经到达目的地了(生产者会添加监听addConfirmListener)。
如果消息和队列是持久化的,那么消息确认会在消息写入磁盘后发出。
可以通过com.rabbitmq.client.Envelope实现应答处理
./rabbitmq-server -detached 后台启动rabbitMQ
推荐文章:RabbitMQ教程
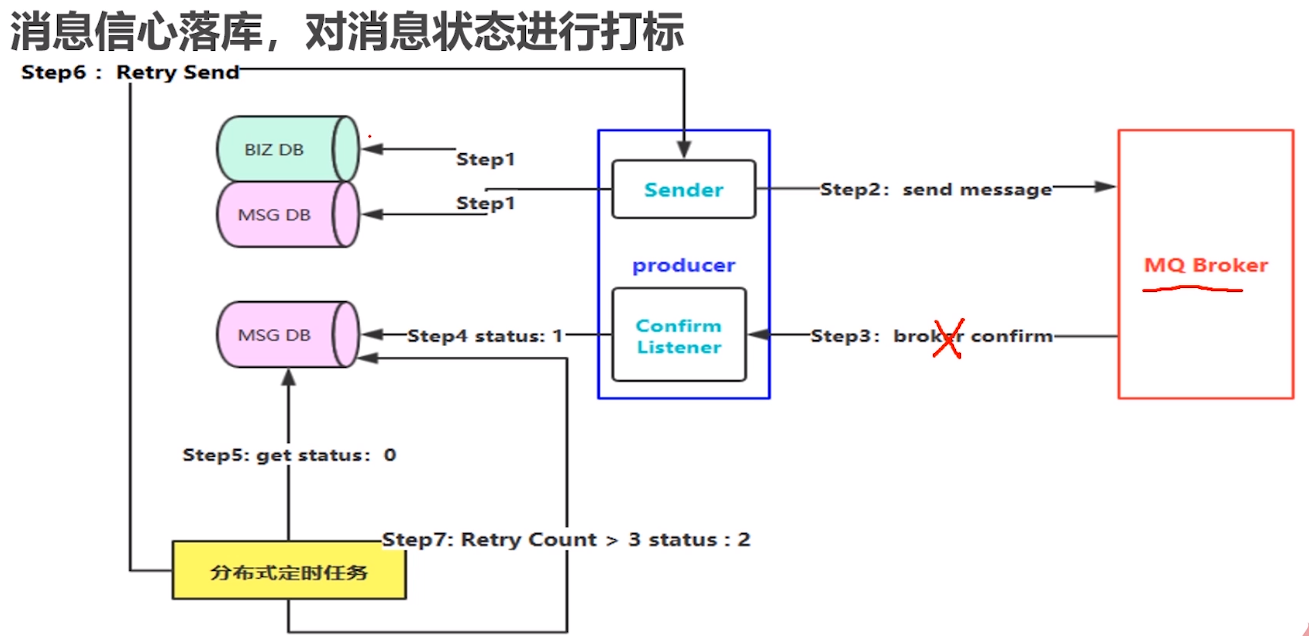
消息信息落库,对消息状态进行打标—防止回ACK的时候失败(网络抖动)
RabbitMQ 消息的持久化,集群,生产者确认,这些RabbitMQ内部的功能应该已经可以保证消息不会被丢失而且正常接收了吧。为什么还要做消息落库这么麻烦呢
因为回ack的时候可能会出现失败,网络抖动问题。
所以采用消息落地到数据库 发送消息的时候 同时insert一条消息记录状态设置为0,如果ack成功了,把消息状态设置为1
如果ack失败了, 落地到数据库的消息没有更新,可以采用定时任务(消息存在了xx min状态还是0,就重新发送)
-
进行数据的入库
比如我们要发送一条订单消息,首先把业务数据也就是订单信息进行入库,然后生成一条消息,把消息也进行入库,这条消息应该包含消息状态属性,并设置初始值比如为0,表示消息创建成功正在发送中,这种方式缺陷在于我们要对数据库进行持久化两次。 -
首先要保证第一步消息都存储成功了,没有出现任何异常情况,然后生产端再进行消息发送。如果失败了就进行快速失败机制。
-
MQ把消息收到的结果应答
(confirm)给生产端 -
生产端有一个
Confirm Listener,去异步的监听Broker回送的响应,从而判断消息是否投递成功,如果成功,去数据库查询该消息,并将消息状态更新为1,表示消息投递成功。
假设第二步OK了,在第三步回送响应时,网络突然出现了闪断,导致生产端的Listener就永远收不到这条消息的confirm应答了,也就是说这条消息的状态就一直为0了。
-
此时我们需要设置一个规则,比如说消息在入库时候设置一个临界值timeout,5分钟之后如果还是0的状态那就需要把消息抽取出来。这里我们使用的是分布式定时任务,去定时抓取DB中距离消息创建时间超过5分钟的且状态为0的消息。
-
把抓取出来的消息进行重新投递
(Retry Send),也就是从第二步开始继续往下走(此时消息可能出现重复投递的情况,需要消费者那边幂等性防止重复消费) -
当然有些消息可能就是由于一些实际的问题无法路由到Broker,比如routingKey设置不对,对应的队列被误删除了,那么这种消息即使重试多次也仍然无法投递成功,所以需要对重试次数做限制,比如限制3次,如果投递次数大于三次,那么就将消息状态更新为2,表示这个消息最终投递失败。
如何保证消息不会被重复消费(消息的幂等性)
在海量订单产生的消息高峰期(高并发情况下),如何避免消息的重复消费问题,消息端实现幂等性就意味着,我们的消息永远不会消费多次,即时我们收到了多条一样的消息。
解决办法
1)唯一ID加指纹吗(业务规则或者时间戳等) 机制,利用数据库主键去重
好处:实现简单
坏处:高并发下有数据库写入的性能瓶颈
解决方案:根据ID进行分库分表 算法路由
2)利用redis原子性(setnx命令)
消费端的限流策略(削峰)
当我们的RabbitMQ有数万条未处理的消息时,我们随便打开一个消费者客户端,巨量的消息全部推送过来,但是我们的客户端无法同时处理这么多数据。
解决办法
RabbitMQ提供了一种qos(服务质量保证)功能,即在非自动确认消息的前提下,如果一定数目的消息未被确认前(通过consumer或者channel设置qos的值),不进行新的消息
autoask=false(不让它自动签收)的情况下才生效,即在自动应答的情况下 这两个值是不生效的。
死信队列
Dead-Letter-Exchange:当消息在一个队列中变成死信(dead message)之后,它能被重新publish到另一个Exchange,
这个Exchange就是DLX,它会把消息路由到它锁绑定的队列上(消费端可能有一个监听去监听这个队列),这样我们可以对一些死信的消息进行后续的处理。
消息变为死信的情况:
1)消息被拒绝并且requeue=false
2)消息TTL过期
3)队列达到最大长度
工作中死信队列非常重要:死信队列就是用来处理一些 消息没有消费者消费 但已经处于死信的情况,我们可以做一些更完善的补偿机制