什么是大数据运维工程师
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出现,将是改变IT业务模式的一种技术。另外,很多小伙伴可能还搞不明白云和Hadoop有什么关系,事实上这是两种截然不同的技术。今天我们就来聊一聊大数据运维工程师。
一.Linux发展与学习线路
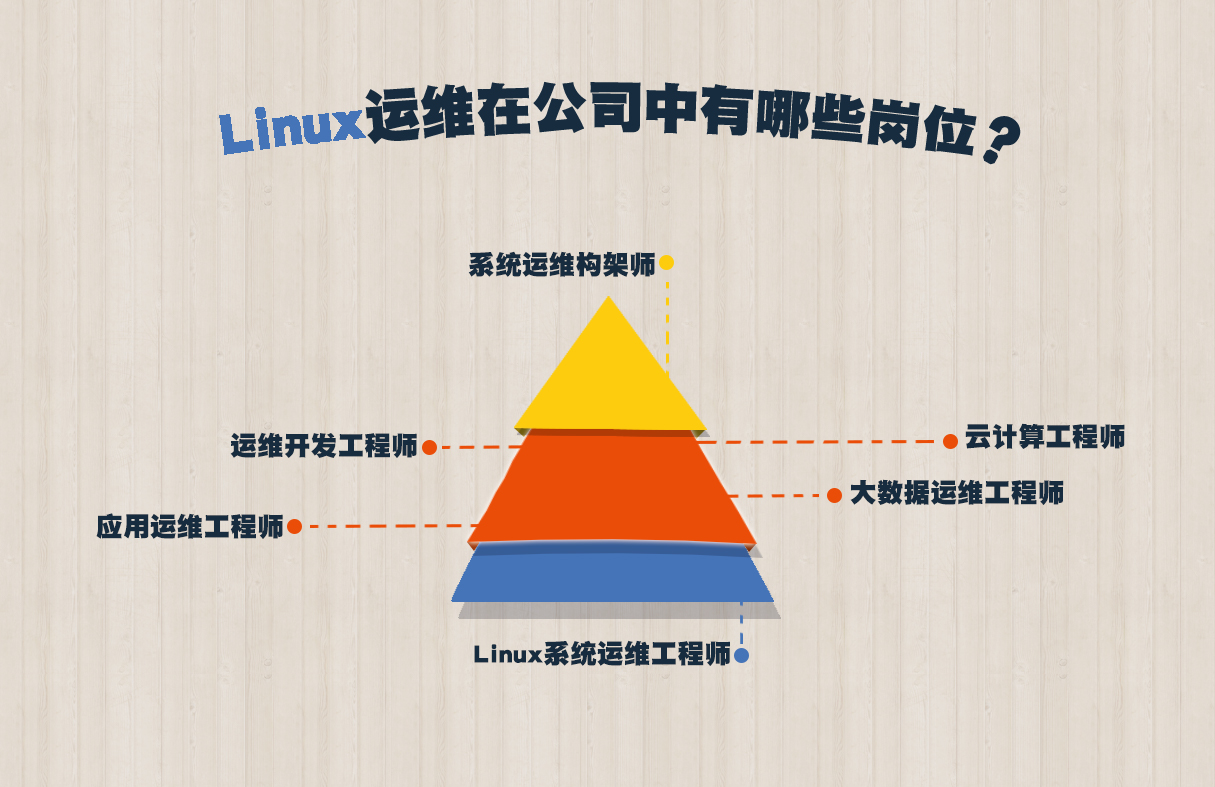
二.大数据运维的工作职责
一.集群管理 大数据需要分布式系统,也就是集群:Hadoop,Hbase,Spark,Kafka,Redis等大数据生态圈组建。 二.故障处理 1>.商用硬件使用故障是常态。 2>.区分故障等级,优先处理影响实时性业务的故障。 三.变更管理 1>.以可控的方式,高效的完成变更工作; 2>.包括配置管理和发布管理; 四.容量管理 1>.存储空间,允许链接数等都是容量概念; 2>.在多租户环境下,容量管理尤其重要; 五.性能调优 1>.不同组建的性能概念不一样,如kafka注重吞吐量,Hbase注重实用性可用性; 2>.需要对组建有深刻的理解 六.架构优化 1>.优化大数据平台架构,支持平台能力和产品的不断迭代; 2>.类似架构师的工作;
三.大数据运维所需的能力
一.DevOps DevOps(英文Development和Operations的组合)是一组过程,方法和系统的统称,用于促进开发(应用程序/软件工程),技术运营和质量保障(QA)部门之间的沟通,写作与整合。 二.硬件,OS,网络,安全的基础知识 大数据平台和组建设计范围广,各种都需要懂一点,这些知识出问题的时候不可能问人,因为别人也有自己的工作要做。 三.脚本语言能力 Shell,SQL(DDL),Python.Java(加分) 四.大数据各个组件知识 设计思想。使用范围,底层架构,常用命令,常用配置或参数,常见问题处理方法。 五.工具能力 Zabbix,Open Falcon,Ganglia,ELK等,企业自研工具。我推荐使用集群自带的工具。 六.Trouble shooting能力 搜索能力(搜索引擎,stackoverflow等),java能力(异常堆栈要看得懂,最好能看懂源码),英文阅读能力。 七.意识,流程 良好的意识,什么能做什么不能做。同用的流程如ITIL,各企业也有自己的流程。
四.大数据运维的主要工作
一.运维三板斧 三板斧可以解决90%以上的故障处理工作。 1>.重启 重启有问题的机器或经常,使其正常工作。 2>.切换 主备切换或主主切换,链接正常工作的节点。 3>.查杀 查杀有问题的进程,链接等。 4>.三板斧的问题 第一:只能处理故障处理问题,不能解决性能调优,架构优化等问题; 第二:只能治标,不能治本; 5>..大数据运维和传统运维的不同 第一:传统运维面对的底层软硬件基本稳固,大数据运维面对的是商用硬件和复杂linux版本; 第二:传统运维面对的是单机架构为主,大数据运维面对复杂的分布式架构; 第三:传统运维大多维护闭源商业版系统,大数据运维通常面对开源系统,文档手册匮乏,对阅读源码要求高。 第四:大数据运维对自动化工具的依赖大大增加; 二.Iaas层(基础设置及服务)运维工作 一般中大型企业有自己的基础设施维护团队,这部分工作不会交给大数据运维来做。小公司可能需要大数据运维键值这部分工作,主要关注三个方面: 1>.硬件 大数据系统大多使用廉价PC Server或虚拟机,硬件故障是常态,通过告警,日志,维护命令等识别故障,并支持硬件更换。 2>.存储 大多使用PC Server挂本磁盘的存储方式,极少情况会使用SAN(存储区域网络)或NAS(网络附属存储),熟悉分区,格式化,巡检等基本操作。 3>.网络 网络的配置变更更需要比较专业的知识,如有需要可学习CCNA,CCNP等认证课程,但网络硬件和配置出问题概率很低,主要关注丢包,延时。 三.HDFS运维工作 1>.容量管理 第一:HDFS空间我使用超过80%要警惕,如果是多租户环境,租户的配额空间也能用完; 第二:熟悉hdfs,fsck,distcp等常用命令,会使用DataNode均衡器; 2>.进程管理 第一:NameNode的进程是重点 第二:熟悉dfsadmin等Ingles。怎么做NameNode高可用。 3>.故障管理 Hadoop最常见的故障就是硬盘损坏。 4>.配置管理 hdfs-site.xml中的参数设置。 四.MapReduce运维工作 1>.进程管理 第一:jobtracker进程故障概率比较低,有问题可以通过重启解决; 第二:了解一下HA的做法; 2>.配置管理 mapred-site.xml中的参数设置。 五.Yarn运维工作 1>.故障管理 主要是当任务异常这中止时看日志排查,通茶故障原因会集中在资源问题,权限问题中的一种。 2>.进程管理 ResourceManager主要是学会配置HA NodeManager进程挂掉不重要,重启即可。 3>.配置管理 yarn-site.xml中的参数设置,主要分三块配置,scheduler的,ResourceManager的,NodeManager的。 六.Hive/Impala运维工作 1>.SQL问题排查 第一:结果不对,主要原因可能是SQL错误,数据不存在,UDF错误等,需要靠经验排查 第二:慢SQL,这类问题开发经常会找运维排查,有可能是劣势SQL,数据量大,也有可能是集群资源紧张; 2>.元数据管理 Hive和Impala公用的元数据,存在关系型数据库中。 七.其它组件 根据组件用途,特性,关注点的不用,运维工作也各不相同,如: 1>.HBase关注读写性能,服务的可用性 2>.Kafka关注吞吐量,负载均衡,消息不丢机制 3>.Flume关注屯度量,故障后的快速恢复
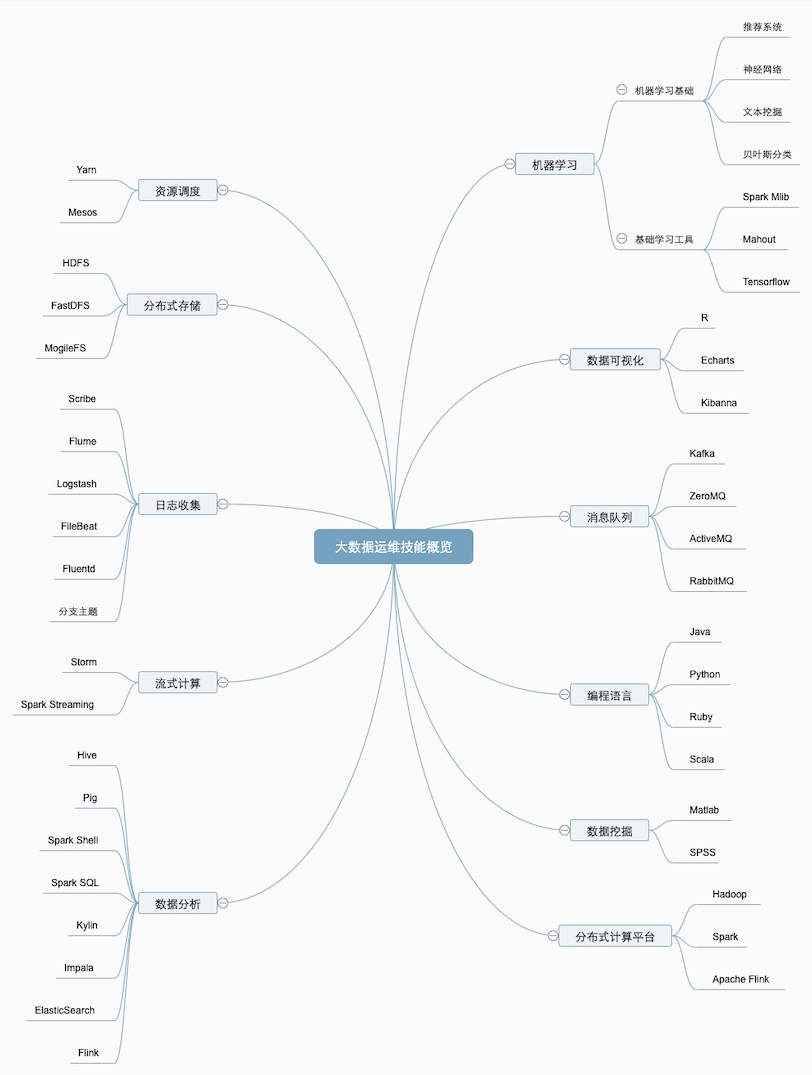
五.大数据运维技能概览
六.大数据运维职业素养
1>.人品 2>.严谨 3>.细心 4>.心态 5>.熟悉操作系统 6>.熟悉业务(开发) 7>.熟悉行业 8>.喜欢大数据生态圈