1. 函数概述
在编程的语境下,函数 (function) 是指一个有命名的、执行某个计算的语句序列 (sequence of statements) 。函数可以针对某类问题建立通用解决步骤(算法),函数减少了重复代码,从而让程序更简洁、易读、易于操作。
函数由对象、语句、表达式组成。
函数执行特定的操作并返回一个值(无返回值则隐式返回 None)
函数编程是面向过程的。
Python函数代码结构和调用如下:

2. 变量
2.1 局部作用域与全局作用域、global语句
如果全局作用域变量在局部作用域没有被定义(赋值,或者作为参数),则全局作用域变量可以被局部作用域读取
>>> def func(): print(a) # 这种写法是不好的 >>> a = 2 # a是全局作用域变量,但可以被局部作用域读取 >>> func() 2
如果变量在局部作用域中被定义了,则局部作用域不会再读取全局作用域的变量,如果在变量被定义前读取,则会引发错误,下面这个例子,Python 编译函数的定义体时, 会先判断 b 是局部变量, 因为在函数中给它赋值了。
>>> b = 5 >>> def func(a): print(a) print(b) # 尝试打印b变量出错,程序终止 b = 8 >>> func(3) 3 Traceback (most recent call last): File "<pyshell#6>", line 1, in <module> func(3) File "<pyshell#5>", line 3, in func print(b) UnboundLocalError: local variable 'b' referenced before assignment
如果在函数中赋值时想让解释器把 b 当成全局变量, 要使用 global 语句声明:
>>> b = 6 >>> def func(a): global b # global语句声明了变量b为全局变量 print(a) print(b) b = 8 >>> func(3) 3 6
2.2 闭包和自由变量、nonlocal语句
自由变量(free variable),是指未在本地作用域中绑定的变量。如果自由变量绑定的值是可变的,则在闭包中仍然可以操作该变量,如果是不可变的(数字、字符串等),则在闭包中重新绑定自由变量会出错
def make_averager(): count = 0 total = 0 def averager(new_value): count += 1 total += new_value return total / count return averager >>> avg = make_averager() >>> avg(10) Traceback (most recent call last): ... UnboundLocalError: local variable 'count' referenced before assignment
要让闭包把变量标记为自由变量,可以用nonlocal语句声明,nonlocal语句解决了上面的问题
def make_averager(): count = 0 total = 0 def averager(new_value): nonlocal count, total # 声明count、total为自由变量 count += 1 total += new_value return total / count return averager
2.2 变量赋值的一些经验(for循环中)
在下面这个例子中,words = Regex2.sub(replace,words,1) 这一句实际上如同增强赋值,如果将words换为其他名称,如a或b等都得不到想要的结果,而且,这样做也省去后面读写文件的一些麻烦
# (文件读写)疯狂填词2.py ''' 创建一个疯狂填词( Mad Libs)程序,它将读入文本文件, 并让用户在该文本 文件中出现 ADJECTIVE、 NOUN、 ADVERB 或 VERB 等单词的地方, 加上他们自 己的文本。例如,一个文本文件可能看起来像这样: The ADJECTIVE panda walked to the NOUN and then VERB. A nearby NOUN was unaffected by these events. 程序将找到这些出现的单词, 并提示用户取代它们。 Enter an adjective: silly Enter a noun: chandelier Enter a verb: screamed Enter a noun: pickup truck 以下的文本文件将被创建: The silly panda walked to the chandelier and then screamed. A nearby pickup truck was unaffected by these events. 结果应该打印到屏幕上, 并保存为一个新的文本文件。 ''' import re def mad_libs(filename_path, save_path): with open(filename_path,'r') as strings: # 相对路径下的文档 words = strings.read() Regex = re.compile(r'w[A-Z]+') # w :匹配1个任何字母、数字或下划线 finds = Regex.findall(words) for i in finds: replace = input('输入你想替换 {} 的单词: '.format(i)) Regex2 = re.compile(i) words = Regex2.sub(replace,words,1) # 这个变量必须要是words与上面一致否则只打印最后替换的一个,可以画栈堆图跟踪这个变量的值 print(words) # strings.close() 不用这一行,with 上下文管理器会自动关闭 with open(save_path,'a') as txt: txt.write(words + ' ') #分行写 txt.close() # save_txt = open('保存疯狂填词文档.txt','a') # save_txt.write(words) # save_txt.close() if __name__ == '__main__': filename_path = input('输入要替换的txt文本路径:') # '疯狂填词原始文档.txt' save_path = input('输入要保存的文件路径(包含文件名称):') # '保存疯狂填词文档.txt' mad_libs(filename_path, save_path)
3. 参数
3.1 形参和实参
在def语句中,位于函数名后面的变量通常称为形参,而调用函数时提供的值称为实参。在函数内部重新关联参数(即绑定,也就是赋值)时,函数外部的变量不受影响。
>>> def try_to_change(n): ... n = 'Mr. Gumby' ... >>> name = 'Mrs. Entity' >>> try_to_change(name) >>> name 'Mrs. Entity'
4. 栈堆图
参考自《像计算机科学家一样思考Python》
# 栈堆图.py def print_twice ( bruce ): print ( bruce ) print ( bruce ) def cat_twice (part1 , part2 ): cat = part1 + part2 print_twice (cat) line1 = 'Bing tiddle' line2 = 'tiddle bang .' cat_twice (line1 , line2 )
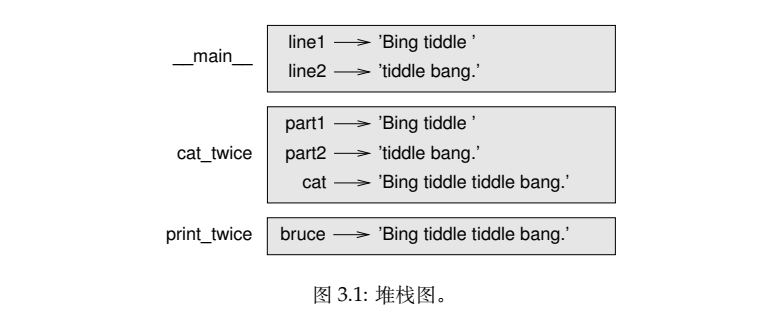
| 1. 每个函数用一个栈帧 (frame) 表示。一个栈帧就是一个线框,函数名在旁边,形参以及 函数内部的变量则在里面。前面例子的堆栈图如图 3.1所示。 2. 这些线框排列成栈的形式,说明了哪个函数调用了哪个函数等信息。在此例中,print_twice 被 cat_twice 调用,cat_twice 又被 __main__ 调用,__main__ 是一个表示最上层栈帧的特殊名 字。当你在所有函数之外创建一个变量时,它就属于 __main__。 3. 每个形参都指向其对应实参的值。因此,part1 和 line1 的值相同,part2 和 line2 的值相 同,bruce 和 cat 的值相同。 4. 如果函数调用时发生错误,Python 会打印出错函数的名字以及调用它的函数的名字,以 及调用后面这个函数 的名字,一直追溯到 __main__ 为止。 例如,如果你试图在 print_twice 里面访问 cat ,你将获得一个 NameError : 5. 这个函数列表被称作回溯 (traceback) 。它告诉你发生错误的是哪个程序文件,错误在 哪一行,以及当时在执行哪个函数。它还会显示引起错误的那一行代码。 回溯中的函数顺序,与堆栈图中的函数顺序一致。出错时正在运行的那个函数则位于回 溯信息的底部。 |
3. 函数代码实践(源自《Python编程快速上手 让繁琐工作自动化》)
''' 编写一个名为 collatz()的函数,它有一个名为 number 的参数。如果参数是偶数,那么 collatz()就打印出 number // 2, 并返回该值。 如果 number 是奇数, collatz()就打印并返回 3 * number + 1。 让用户输入一个整数, 并不断对这个数调用 collatz(), 直到函数返回值1 (令人惊奇的是, 这个序列对于任何整数都有效, 利用这个序列,你迟早会得到 1! 既使数学家也不能确定为什么。 你的程序在研究所谓的“Collatz序列”, 它有时候被称为“最简单的、 不可能的数学问题”)。 在前面的项目中添加 try 和 except 语句,检测用户是否输入了一个非整数的字符串。正常情况下, int()函数在传入一个非整数字符串时,会产生 ValueError 误, 比如 int('puppy')。在 except 子句中,向用户输出一条信息,告诉他们必须输入一个整数。 ''' def collatz(number): if number == 1: return 1 elif number % 2 == 0: numbers = number // 2 print(numbers) collatz(numbers) elif number % 2 == 1: numbers = 3*number + 1 print(numbers) collatz(numbers) try: number = int(input("请输入一个整数->:")) collatz(number) except ValueError: print("please input a integer number")