这一周看完尚学堂的视频,偶然看到毕向东老师的文档,就跟着在梳理一下
在我的文件有他的PDF
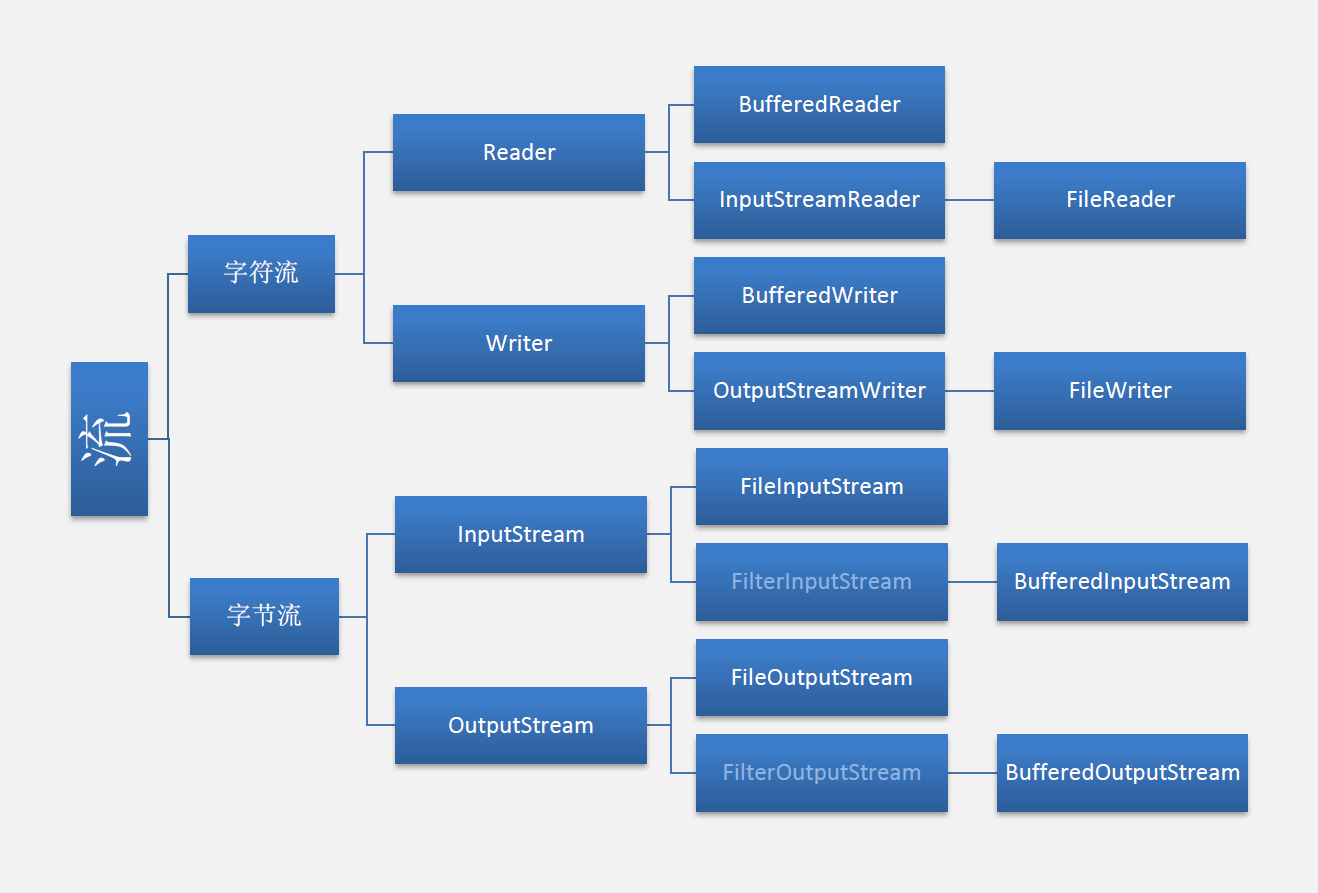

IO 流:用于处理设备上的数据。
设备:硬盘,内存,键盘录入。
IO 有具体的分类:
1,根据处理的数据类型不同:字节流和字符流。
2,根据流向不同:输入流和输出流。
字符流的由来:
因为文件编码的不同,而有了对字符进行高效操作的字符流对象。
原理:其实就是基于字节流读取字节时,去查了指定的码表。
字节流和字符流的区别:
1,字节流读取的时候,读到一个字节就返回一个字节。字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,在 UTF-8 码表中是 3 个字节)时。先去查指定的编码表,将查到的字符返回。
2,字节流可以处理所有类型数据,如图片,mp3,avi。
而字符流只能处理字符数据。
结论:只要是处理纯文本数据,就要优先考虑使用字符流。除此之外都用字节流。
IO 的体系。所具备的基本功能就有两个:读 和 写。
1.字节流
InputStream 读和 OutputStream 写
2.字符流
Reader 读 和Writer 写
基本的读写操作方式
因为数据通常都以文件的形式存在
所以就要找到IO体系中可以用于操作文件的流对象 通过名称可以更容易获取该对象
因为 IO 体系中的子类名后缀绝大部分是父类名称。而前缀都是体现子类功能的名字。
Reader
|--InputStreamReader
|--FileReader:专门用于处理文件的字符读取流对象。

Writer
|--OutputStreamWriter
|--FileWriter:专门用于处理文件的字符写入流对象。

FileWriter:
该类没有特有的方法。只有自己的构造函数。
该类特点在于,
1,用于处理文本文件。
2,该类中有默认的编码表,
3,该类中有临时缓冲。
构造函数:在写入流对象初始化时,必须要有一个存储数据的目的地。 FileWriter(String filename):
该构造函数做了什么事情呢?
1,调用系统资源。
2,在指定位置,创建一个文件。
注意:如果该文件已存在,将会被覆盖。
FileWriter(String filename,boolean append):
该构造函数:当传入的 boolean 类型值为 true 时,会在指定文件末尾处进行数据的续写。
FileReader:
1,用于读取文本文件的流对象。
2,用于关联文本文件。
构造函数:在读取流对象初始化的时候,必须要指定一个被读取的文件。
如果该文件不存在会发生 FileNotFoundException.
FileReader(String filename);
1.将文本数据存储到一个文件中
public class Demo{ public static void main(String[] args) throws IOException { FileWriter fw = new FileWrier("demo.txt"); fw.write("abcdec"); fw.flush(); fw.write("kkkk"); fw.close(); } }
注意:对于读取或者写入流对象的构造函数,以及读写方法,还有刷新关闭功能都会抛出 IOException 或其子类
2.完整的异常处理方式。
public class Demo{ public static void main(String[] args){ FileWriter fw = null; try { fw = new FileWrier("z:\demo.txt"); fw.write("abcdec"); fw.flush(); fw.write("kkkk"); } catch(IOException e) { System.out.println(e.toString()); } finally { if(fw!=null) { try { fw.close(); } catch(IOException e) { System.out.println("close:"+e.toString()); } } } } }
当指定绝对路径时,定义目录分隔符有两种方式:
1,反斜线 但是一定要写两个。\ new FileWriter("c:\demo.txt");
2,斜线 / 写一个即可。 new FileWriter("c:/demo.txt");
3.读取一个已有的文本文件,将文本数据打印出来。
public class Demo{ public static void main(String[] args) throws IOException { FileReader fr = new FileReader("demo.txt"); int ch = 0;//一次读一个字符。 while((ch=fr.read())!=-1) { System.out.print((char)ch); } fr.close(); } }
4.读一个字符就存入字符数组里,读完 1Kb 再打印
public class Demo{ public static void main(String[] args){ FileReader fr = null; try { fr = new FileReader("demo.txt"); char[] buf = new char[1024];//该长度通常都是 1024 的整数倍。 int len = 0; while((len=fr.read(buf))!=-1) { System.out.println(new String(buf,0,len)); } } catch(IOException e) { System.out.println(e.toString()); } finally { if(fr!=null) { try { fr.close(); } catch(IOException e) { System.out.println("close:"+e.toString()); } } } } }
字符流的缓冲区:
缓冲区的出现提高了对流的操作效率。
原理:其实就是将数组进行封装。
对应的对象:
BufferedWriter:
特有方法:
newLine():跨平台的换行符。
BufferedReader:
特有方法:
readLine():一次读一行,到行标记时,将行标记之前的字符数据作为字符串返回。当读到末尾时,返回 null。
在使用缓冲区对象时,要明确,缓冲的存在是为了增强流的功能而存在,所以在建立缓冲区对象时,要先有流对象存在。
其实缓冲内部就是在使用流对象的方法,只不过加入了数组对数据进行了临时存储。为了提高操作数据的效率。
代码上的体现:
写入缓冲区对象。
//建立缓冲区对象必须把流对象作为参数传递给缓冲区的构造函数。 BufferedWriter bufw = new BufferedWriter(new FileWriter("buf.txt"));
bufw.write("abce");//将数据写入到了缓冲区。
bufw.flush();//对缓冲区的数据进行刷新。将数据刷到目的地中。
bufw.close();//关闭缓冲区,其实关闭的是被包装在内部的流对象。
1.读取缓冲区的对象
BufferedReader bufr = new BufferedReader(new FileReader("buf.txt")); String line = null; //按照行的形式取出数据。取出的每一个行数据不包含回车符。 while((line=bufr.readLine())!=null) { System.out.println(line); } bufr.close();
2.通过缓冲区的形式,对文本文件进行拷贝。
public static void main(String[] args) { BufferedReader bufr = new BufferedReader(new FileReader("a.txt")); BufferedWriter bufw = new BufferedWriter(new FileWriter("b.txt")); String line = null; while((line=bufr.readLine())!=null) { bufw.write(line); bufw.newLine(); bufw.flush(); } bufw.close(); bufr.close(); }
readLine():方法的原理:
其实缓冲区中的该方法,用的还是与缓冲区关联的流对象的 read 方法。
只不过,每一次读到一个字符,先不进行具体操作,先进行临时存储。
当读取到回车标记时,将临时容器中存储的数据一次性返回。
既然明确了原理,我们也可以实现一个类似功能的方法。
public class MyBufferedReader{ private Reader r; MyBufferedReader(Reader r){ this.r = r; } public String myReadLine()throws IOException { //1,创建临时容器。 StringBuilder sb = new StringBuilder(); //2,循环的使用 read 方法不断读取字符。 int ch = 0; while((ch=r.read())!=-1) { if(ch==' ') continue; if(ch==' ') return sb.toString(); else sb.append((char)ch); } if(sb.length()!=0) return sb.toString(); return null; } public void myClose()throws IOException { r.close(); } public static void main(String[]args) { MyBufferedReader myBufr = new MyBufferedReader(new FileReader("a.txt")); String line = null; while((line=myBufr.myReadLine())!=null) { System.out.println(line); } myBufr.close(); } }
它的出现基于流并增强了流的功能。
这也是一种设计模式的体现:装饰设计模式。
对一组对象进行功能的增强。
该模式和继承有什么区别呢?
它比继承有更好的灵活性。
//转载来自https://blog.csdn.net/BOKEhhh/article/details/107644060
通常装饰类和被装饰类都同属与一个父类或者接口。
装饰设计模式有4个角色,由组件和装饰者组成。
有四大组成部分:
1、抽象组件:需要装饰的抽象对象(一般是接口或则抽象父类)
2、具体组件:需要装饰的对象(刚才的Person人)
3、抽象装饰类:内部包含了对抽象组件的引用以及装饰者共有的方法
4、具体装饰类:被装饰的对象
public class Test { public static void main(String[] args) { Drink coffee = new Coffee(); Drink coffee2 = new Coffee(); Drink milk = new Milk(coffee);//装饰 System.out.println(milk.info() + "-->" + milk.cost()); Suger suger = new Suger(coffee2);//装饰 System.out.println(suger.info() + "-->" + suger.cost()); milk = new Milk(suger);//装饰 System.out.println(milk.info() + "-->" + milk.cost()); } } //抽象组件 interface Drink{ double cost();//费用 String info();//说明 } //具体组件 class Coffee implements Drink{ private String name = "原味咖啡"; @Override public double cost() { return 10; } @Override public String info() { return name; } } //抽象装饰类 abstract class Decorate implements Drink{ //对抽象组件的引用 private Drink drink; public Decorate(Drink drink) { this.drink = drink; } @Override public double cost() { return this.drink.cost(); } @Override public String info() { return this.drink.info(); } } //具体装饰类 class Milk extends Decorate{ public Milk(Drink drink) { super(drink); } @Override public double cost() { return super.cost() * 4; } @Override public String info() { return super.info() + "加入了牛奶"; } } //具体装饰类 class Suger extends Decorate{ public Suger(Drink drink) { super(drink); } @Override public double cost() { return super.cost() * 2; } @Override public String info() { return super.info() + "加入了蔗糖"; } }
字节流:

需求:copy 一个图片。 BufferedInputStream bufis = new BufferedInputStream(new FileInputStream("1.jpg")); BufferedOutputStream bufos =new BufferedOutputStream(new FileOutptStream("2.jpg")); int by = 0; while((by=bufis.read())!=-1) { bufos.write(by); } bufos.close(); bufis.close()

转换流:
特点:
1,是字节流和字符流之间的桥梁。
2,该流对象中可以对读取到的字节数据进行指定编码表的编码转换。
什么时候使用呢?
1,当字节和字符之间有转换动作时。
2,流操作的数据需要进行编码表的指定时。
具体的对象体现:
1,InputStreamReader:字节到字符的桥梁。
2,OutputStreamWriter:字符到字节的桥梁。
这两个流对象是字符流体系中的成员。
那么它们有转换作用,而本身又是字符流。所以在构造的时候,需要传入字节流对象进来。
构造函数:
InputStreamReader(InputStream):通过该构造函数初始化,使用的是本系统默认的编码表GBK。
InputStreamReader(InputStream,String charSet):通过该构造函数初始化,可以指定编码表。
OutputStreamWriter(OutputStream):通过该构造函数初始化,使用的是本系统默认的编码表 GBK。
OutputStreamWriter(OutputStream,String charSet):通过该构造函数初始化,可以指定编码表。
操作文件的字符流对象是转换流的子类。
Reader
|--InputStreamReader
|--FileReader
Writer
|--OutputStreamWriter
|--FileWriter
转换流中的 read 方法。已经融入了编码表,
在底层调用字节流的 read 方法时将获取的一个或者多个字节数据进行临时存储,并去查指定的编码表,如果编码表没有指定,查的是默认码表。那么转流的 read 方法就可以返回一个字符比如中文。
转换流已经完成了编码转换的动作,对于直接操作的文本文件的 FileReaer 而言,就不用在重新定义了,
只要继承该转换流,获取其方法,就可以直接操作文本文件中的字符数据了。
注意:
在使用 FileReader 操作文本数据时,该对象使用的是默认的编码表。
如果要使用指定编码表时,必须使用转换流。
FileReader fr = new FileReader("a.txt");//操作 a.txt 的中的数据使用的本系统默认的 GBK。
操作 a.txt 中的数据使用的也是本系统默认的 GBK。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"));
这两句的代码的意义相同。
如果 a.txt 中的文件中的字符数据是通过 utf-8 的形式编码。
那么在读取时,就必须指定编码表。那么转换流必须使用。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"utf-8");
InputStreamReader是从字节流到字符流的桥梁。它读取的是字节。它指定charset 字符集将其解码(decode)为字符。
OutputStreamWriter是从字符流到字节流的桥梁:使用指定的charset将写入的字符编码(encoded)为字节。
1,构造函数:
File(String filename):将一个字符串路径(相对或者绝对)封装成 File 对象,该路径是可存在的,也可以是不存在。
File(String parent,String child);
File(File parent,String child);
2,特别的字段:separator:跨平台的目录分隔符。
例子:File file = new File("c:"+File.separator+"abc"+File.separator+"a.txt");
3,常见方法:
1,创建:
boolean createNewFile()throws IOException:创建文件,如果被创建的文件已经存在,则不创建。
boolean mkdir(): 创建文件夹。
boolean mkdirs(): 创建多级文件夹。
2,删除:
boolean delete():可用于删除文件或者文件夹。
注意:对于文件夹只能删除不带内容的空文件夹,
对于带有内容的文件夹,不可以直接删除,必须要从里往外删除。
void deleteOnExit(): 删除动作交给系统完成。无论是否反生异常,系统在退出
时执行删除动作。
3,判断:
boolean canExecute():
boolean canWrite():
boolean canRead();
boolean exists():判断文件或者文件夹是否存在。
boolean isFile(): 判断 File 对象中封装的是否是文件。
boolean isDirectory():判断 File 对象中封装的是否是文件夹。
boolean isHidden():判断文件或者文件夹是否隐藏。在获取硬盘文件或者文件夹时,
对于系统目录中的文件,java 是无法访问的,所以在遍历,可以避免遍历隐藏文件。
4,获取:
getName():获取文件或者文件夹的名称。
getPath():File 对象中封装的路径是什么,获取的就是什么。
getAbsolutePath():无论 File 对象中封装的路径是什么,获取的都是绝对路径。
getParent(): 获取 File 对象封装文件或者文件夹的父目录。
注意:如果封装的是相对路径,那么返回的是 null.
long length():获取文件大小。
long lastModified():获取文件或者文件最后一次修改的时间。
static File[] listRoots():获取的是被系统中有效的盘符。
String[] list():获取指定目录下当前的文件以及文件夹名称。
String[] list(Filenamefilter): 可以根据指定的过滤器,过滤后的文件及文件夹名称。
File[] listFiles():获取指定目录下的文件以及文件夹对象。
5,重命名:
renameTo(File):
File f1 = new File("c:\a.txt");
File f2 = new File("c:\b.txt");
f1.renameTo(f2);//将 c 盘下的 a.txt 文件改名为 b.txt 文件。

1,打印流。
PrintStream:
是一个字节打印流,System.out 对应的类型就是 PrintStream。
它的构造函数可以接收三种数据类型的值。
1,字符串路径。
2,File 对象。
3,OutputStream。
PrintWriter:
是一个字符打印流。构造函数可以接收四种类型的值。
1,字符串路径。
2,File 对象。
对于 1,2 类型的数据,还可以指定编码表。也就是字符集。
3,OutputStream
4,Writer
对于 3,4 类型的数据,可以指定自动刷新。
注意:该自动刷新值为 true 时,只有三个方法可以用:println,printf,format.
//如果想要既有自动刷新,又可执行编码。如何完成流对象的包装?
PrintWrter pw = new PrintWriter(new OutputSteamWriter(new FileOutputStream("a.txt"),"utf-8"),true);
//如果想要提高效率。还要使用打印方法。
PrintWrter pw = new PrintWriter(new BufferdWriter(new OutputSteamWriter(new FileOutputStream("a.txt"),"utf-8")),true);



注意:因为 Enumeration 是 Vector 中特有的取出方式。而 Vector 被 ArrayList 取代。所以要使用 ArrayList 集合效率更高一些。那么如何获取 Enumeration 呢? ArrayList<FileInputStream > al = new ArrayList<FileInputStream>(); for(int x=1; x<4; x++) al.add(new FileInputStream(x+".txt")); Iterator<FileInputStream> it = al.iterator(); Enumeration<FileInputStream> en = new Enumeration<FileInputStream>() { public boolean hasMoreElements() { return it.hasNext(); } public FileInputStream nextElement() { return it.next(); } };
//多个流就变成了一个流,这就是数据源。 SequenceInputStream sis = new SequenceInputStream(en); //创建数据目的。 FileOutputStream fos = new FileOutputStream("4.txt"); byte[] buf = new byte[1024*4]; int len = 0; while((len=sis.read(buf))!=-1) { fos.write(buf,0,len); } fos.close(); sis.close();
//如果要一个对文件数据切割。一个读取对应多了输出。 FileInputStream fis = new FileInputStream("1.mp3"); FileOutputStream fos = null; byte[] buf = new byte[1024*1024];//是一个 1MB 的缓冲区。 int len = 0; int count = 1; while((len=fis.read(buf))!=-1) { fos = new FileOutputStream((count++)+".part); fos.write(buf,0,len); fos.close(); } fis.close(); //这样就是将 1.mp3 文件切割成多个碎片文件。想要合并使用 SequenceInputStream 即可。 对于切割后,合并是需要的一些源文件的信息。 可以通过配置文件进行存储。该配置可以通过键=值的形式存在。 然后通过 Properties 对象进行数据的加载和获取。
//这个就随便

我觉得我看了一下感觉...............????????????不太行
我在总结一个 就今晚哈哈哈 今晚不加班