Tesseract-OCR-03-图片文字识别
本篇介绍使用 Tesseract-OCR 做图片文字识别,识别手写文字的时候,正确率能达到 90%,当训练后正确率是极高的。这里介绍的图片文字识别,可以识别英文,数字和中文等
Tesseract-OCR 图片文字识别
- Tesseract:一款由HP实验室开发由Google维护的开源OCR,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎
- 如果还没有安装 Tesseract-OCR 请参考:
- Windows下 Tesseract-OCR 的安装与 环境变量配置
https://blog.csdn.net/qq_40147863/article/details/82285920
- Windows下 Tesseract-OCR 的安装与 环境变量配置
- 当然配置环境也都下载上面那篇文章了,一步一图很详细
正题 图片文字识别
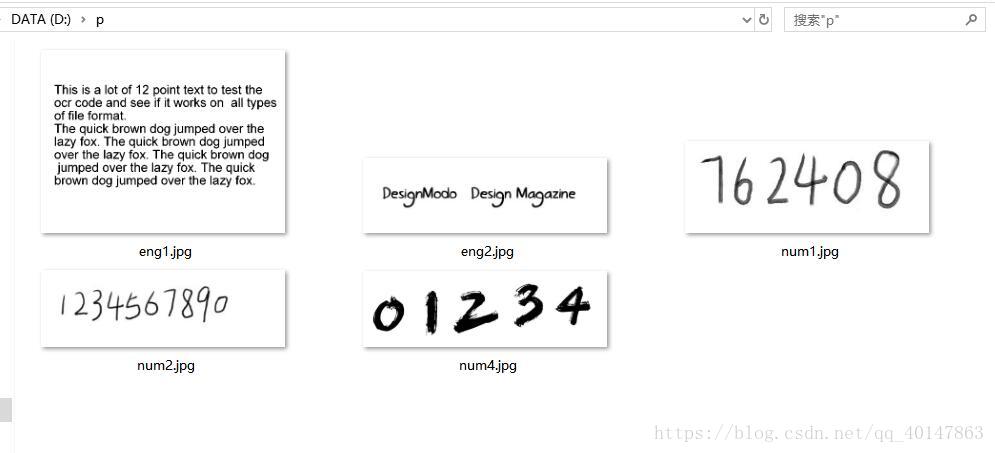
- 我搜集了几个素材,懒得找可以直接下载:
- https://pan.baidu.com/s/10XxYJa19KIa8-ENdQkhhHg
- 这里我是将图片放在了:D:p
- 我们需要在 cmd 进入此目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
- 使用 Tesseract 命令:
tesseract 文件名 保存的txt文件名 -l eng 例:
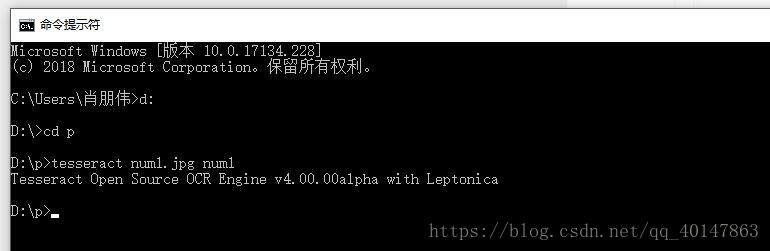
tesseract num1.jpg num1
- 这里 -l eng 是设置语言,不写的话,默认是 eng 也就是英语
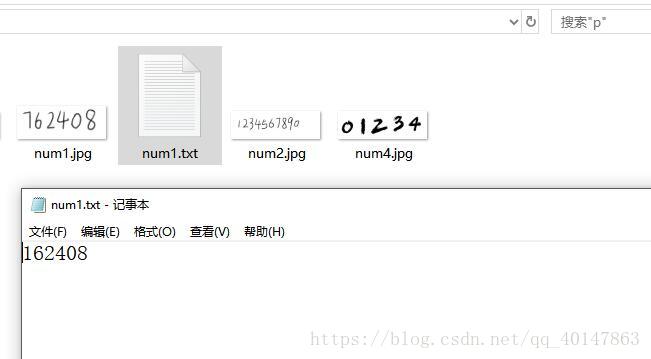
- 结果:
- 注意:
- 1.这里如果报错 Tesseract 不是内部或外部命令,就是环境变量没有配置好参照:
https://blog.csdn.net/qq_40147863/article/details/82285920 - 2.如果识别的图片文字是中文会提示,0个文字
- 1.这里如果报错 Tesseract 不是内部或外部命令,就是环境变量没有配置好参照:
识别手写英文
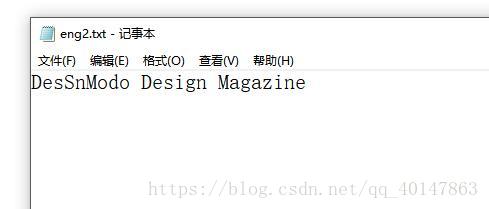
- 识别图片 eng2.jpg
- 输入命令:保存为 eng2.txt
- 我们对比一下结果:
- 这里是识别错了一个字母,把 ig 错误的识别成 S,包括上面那张 数字也是错了一个
- 那也就是我们要努力的方向了


识别中文
- 这里识别中文只需要将 -l 参数改成 chi_sim 例如:
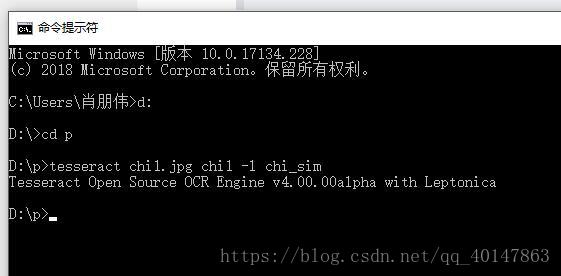
- 对 有中文文字的图片 chi1.jpg ,进入图片路径,使用一下命令:
**tesseract chi1.jpg chi1 -l chi_sim **
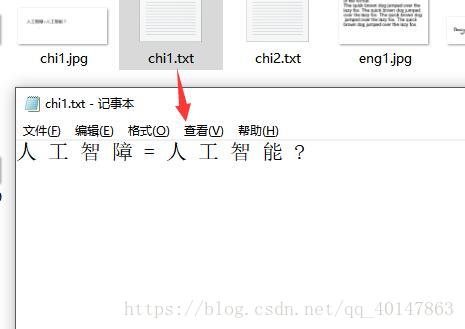
- 图片样式:
- 执行命令:
- 运行结果:

识别英文和数字夹杂验证码
- 例如:
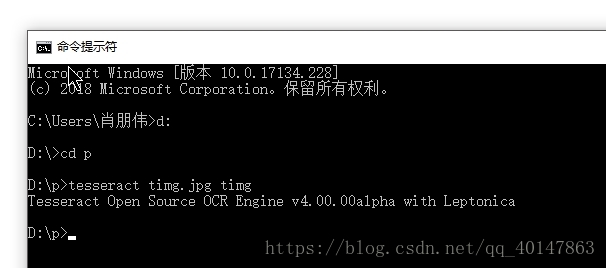
- 对 图片 timg.jpg ,进入图片路径,使用一下命令:
tesseract timg.jpg timg
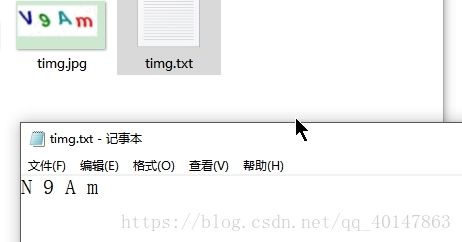
- 图片样式:
- 执行命令:
- 运行结果:

Tesseract 训练:
- 我们可以通过重复的训练,用更多的数据去训练,就可以达到更多高的识别正确率
- 我们使用 jTessBoxEditor 训练
- 由于 jTessBoxEditor 的安装和训练,内容比较多,我再整理一篇
更多文章链接:Tesseract 随笔
- 本笔记不允许任何个人和组织转载