分类器评价指标主要有:
1,Accuracy
2,Precision
3,Recall
4,F1 score
5,ROC 曲线
6,AUC
7,PR 曲线
混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
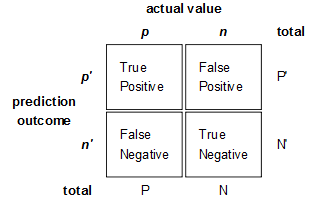
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
假正率(False Positive Rate,FPR) :FPR=FP/(FP+TN),即被预测为正的负样本数 /负样本实际数。
假负率(False Negative Rate,FNR) :FNR=FN/(TP+FN),即被预测为负的正样本数 /正样本实际数。
真负率(True Negative Rate,TNR):TNR=TN/(TN+FP),即被预测为负的负样本数 /负样本实际数
再说PRC, 其全称就是Precision Recall Curve,它以查准率为Y轴,、查全率为X轴做的图。它是综合评价整体结果的评估指标。所以,哪总类型(正或者负)样本多,权重就大。也就是通常说的『对样本不均衡敏感』,『容易被多的样品带走』。
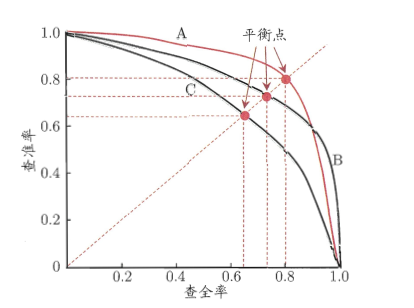
上图就是一幅P-R图,它能直观地显示出学习器在样本总体上的查全率和查准率,显然它是一条总体趋势是递减的曲线。在进行比较时,若一个学习器的PR曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者,比如上图中A优于C。但是B和A谁更好呢?因为AB两条曲线交叉了,所以很难比较,这时比较合理的判据就是比较PR曲线下的面积,该指标在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。因为这个值不容易估算,所以人们引入“平衡点”(BEP)来度量,他表示“查准率=查全率”时的取值,值越大表明分类器性能越好,以此比较我们一下子就能判断A较B好。
BEP还是有点简化了,更常用的是F1度量:
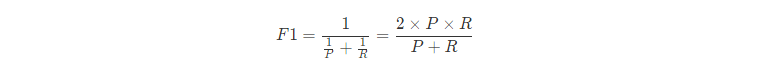
F1-score 就是一个综合考虑precision和recall的指标,比BEP更为常用。
ROC & AUC
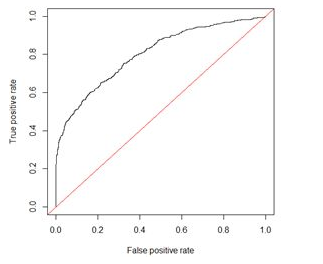
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,ROC曲线以“真正例率”(TPR)为Y轴,以“假正例率”(FPR)为X轴,对角线对应于“随机猜测”模型,而(0,1)则对应“理想模型”。ROC形式如下图所示。
TPR和FPR的定义如下:
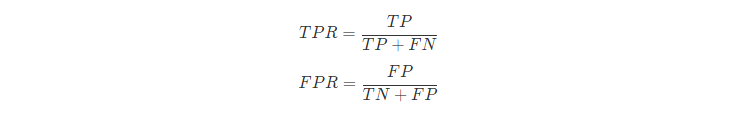
从形式上看TPR就是我们上面提到的查全率Recall,而FPR的含义就是:所有确实为“假”的样本中,被误判真的样本。
进行学习器比较时,与PR图相似,若一个学习器的ROC曲线被另一个学习器的曲线包住,那么我们可以断言后者性能优于前者;若两个学习器的ROC曲线发生交叉,则难以一般性断言两者孰优孰劣。此时若要进行比较,那么可以比较ROC曲线下的面积,即AUC,面积大的曲线对应的分类器性能更好。
AUC(Area Under Curve)的值为ROC曲线下面的面积,若分类器的性能极好,则AUC为1。但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好,上图AUC为0.81。若AUC=0.5,即与上图中红线重合,表示模型的区分能力与随机猜测没有差别。若AUC真的小于0.5,请检查一下是不是好坏标签标反了,或者是模型真的很差。
准确率(Accuracy)
准确率是最常用的分类性能指标
Accuracy = (TP+TN)/(TP+FN+FP+TN),即正确预测的正反例数 /总数
精确率(Precision)
精确率容易和准确率被混为一谈。其实,精确率只是针对预测正确的正样本而不是所有预测正确的样本。表现为预测出是正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP),即正确预测的正例数 /预测正例总数
召回率(Recall)
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN),即正确预测的正例数 /实际正例总数
查全率=检索出的相关信息量 / 系统中的相关信息总量
F1 score
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall
PRC
再说PRC, 其全称就是Precision Recall Curve,它以查准率为Y轴,、查全率为X轴做的图。它是综合评价整体结果的评估指标。所以,哪总类型(正或者负)样本多,权重就大。也就是通常说的『对样本不均衡敏感』,『容易被多的样品带走』。
上图就是一幅P-R图,它能直观地显示出学习器在样本总体上的查全率和查准率,显然它是一条总体趋势是递减的曲线。在进行比较时,若一个学习器的PR曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者,比如上图中A优于C。但是B和A谁更好呢?因为AB两条曲线交叉了,所以很难比较,这时比较合理的判据就是比较PR曲线下的面积,该指标在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。因为这个值不容易估算,所以人们引入“平衡点”(BEP)来度量,他表示“查准率=查全率”时的取值,值越大表明分类器性能越好,以此比较我们一下子就能判断A较B好。
BEP还是有点简化了,更常用的是F1度量:
F1-score 就是一个综合考虑precision和recall的指标,比BEP更为常用。
ROC & AUC
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,ROC曲线以“真正例率”(TPR)为Y轴,以“假正例率”(FPR)为X轴,对角线对应于“随机猜测”模型,而(0,1)则对应“理想模型”。ROC形式如下图所示。
TPR和FPR的定义如下:
从形式上看TPR就是我们上面提到的查全率Recall,而FPR的含义就是:所有确实为“假”的样本中,被误判真的样本。
进行学习器比较时,与PR图相似,若一个学习器的ROC曲线被另一个学习器的曲线包住,那么我们可以断言后者性能优于前者;若两个学习器的ROC曲线发生交叉,则难以一般性断言两者孰优孰劣。此时若要进行比较,那么可以比较ROC曲线下的面积,即AUC,面积大的曲线对应的分类器性能更好。
AUC(Area Under Curve)的值为ROC曲线下面的面积,若分类器的性能极好,则AUC为1。但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好,上图AUC为0.81。若AUC=0.5,即与上图中红线重合,表示模型的区分能力与随机猜测没有差别。若AUC真的小于0.5,请检查一下是不是好坏标签标反了,或者是模型真的很差。
以上文章参考: