目录
客户端接口(Client interface)
回调队列(Callback queue)
关联标识(Correlation Id)
总结
代码整合
在第二个教程中,我们学习了如何使用工作队列在多个worker之间分配耗时的任务。
但是如果我们需要在远程计算机上运行功能并等待结果呢?嗯,这是另外一件事情,这种模式通常被称为远程过程调用(RPC)。
在本教程中我们将使用RabbitMQ的建立一个RPC系统:一个客户端和一个可伸缩的RPC服务器。由于我们没有什么耗时的任务,我们要创建一个返回斐波那契数虚设RPC服务。
客户端接口(Client interface)
为了说明RPC如何使用,我们将创建一个简单的客户端类。它将创建一个名为call的方法——发送RPC请求,并且处于阻塞状态,直到收到应答。
FibonacciRpcClient fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println( "fib(4) is " + result);PRC笔记
尽管PRC是一个常见的模式,它经常受到批评。当程序员不知道他所调用的方法是本地的还是一个缓慢的RPC,问题就出现了。这样的混乱在系统中造成不可预料的结果,并增加了不必要的调试的复杂性,相比于简单的软件,PRC的滥用可能导致造成不可维护的面条式的代码。
考虑到这一点,请参考以下建议:确保能明确分辨出哪些函数是本地的,哪些是远程的。
建立文档,让组件之间的依赖关系更清楚。
处理错误的case,如果RPC服务器挂了很长时间,客户端应该怎么处理?
如果对以上有疑问,请避免使用。如果没有,你也应该使用异步管道,而不是阻塞式的RPC调用,结果被异步地推到下一个计算阶段。
回调队列(Callback queue)
一般来说利用RabbitMQ来做RPC是很简单的。客户端发送请求消息,服务端回复应答消息。为了能收到回复,我们需要发送一个“callback”队列地址在请求里面。我们可以使用默认队列(这是Java客户端独有的):
callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue", props, message.getBytes());
// ... then code to read a response message from the callback_queue ...消息属性
AMQP协议预定义了14个属性去发送消息。大部分的属性都很少使用,但是下列除外:
deliveryMode:标记的消息为持久(值为2)或暂时的(任何其他值)。你可能还记得第二个教程中的此属性。
contentType:用于描述MIME类型的编码。例如,对于经常使用JSON编码,是一个很好的做法,将此属性设置为:application/json。
eplyTo: 常用于命名一个回调队列。
correlationId: 用于关联的RPC响应。
我们需要import:
import com.rabbitmq.client.AMQP.BasicProperties;关联标识(Correlation Id)
在上面介绍的方法中,我们建议为每一个RPC请求建立一个回调队列。这是相当低效的,幸好有一个更好的办法 - 让我们创建每个客户端一个回调队列。
这样产生了一个新的问题,在收到该回调队列的响应的时候,我们并不知道该响应是哪个请求的响应,这就是correlationId属性的用处,我们将它设置为每个请求的唯一值。这样,当我们在回调队列收到一条消息的时候,我们将看看这个属性,就能找到与这个响应相对应的请求。如果我们看到一个未知的correlationId,我们完全可以丢弃消息,因为他不并不属于我们系统。
你也许会问,为什么我们选择丢弃这个消息,而不是抛出一个错误。这是为了解决服务器端有可能发生的竞争情况。尽管可能性不大,但RPC服务器还是有可能在已将应答发送给我们但还未将确认消息发送给请求的情况下死掉。如果这种情况发生,RPC在重启后会重新处理请求。这就是为什么我们必须在客户端优雅的处理重复响应,同时RPC也需要尽可能保持幂等性。
总结
我们的RPC这样工作:
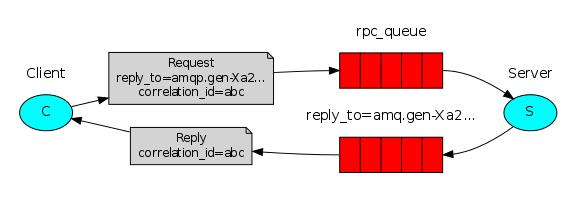
- 当客户端启动的时候,创建一个匿名的独享的回调队列。
- 在RPC请求中,客户端发送带有两个属性的消息:一个是设置回调队列的 reply_to 属性,另一个是设置唯一值的 correlation_id 属性。
- 该请求被发送到rpc_queue队列。
- RPC工作者(又名:服务器)等待请求发送到这个队列中来。当请求出现的时候,它执行他的工作并且将带有执行结果的消息发送给reply_to字段指定的队列。
- 客户端等待回调队列里的数据。当有消息出现的时候,它会检查correlation_id属性。如果此属性的值与请求匹配,将它返回给应用。
代码整合
斐波那契数列任务:
private static int fib(int n) throws Exception {
if (n == 0) return 0;
if (n == 1) return 1;
return fib(n-1) + fib(n-2);
}我们定义一个斐波那契的方法,假定只有有效的正整数输入。(不要指望它为大数据工作,这可能是最慢的递归实现)
我们的RPC服务器RPCServer.java的代码如下:
private static final String RPC_QUEUE_NAME = "rpc_queue";
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(RPC_QUEUE_NAME, false, false, false, null);
channel.basicQos(1);
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(RPC_QUEUE_NAME, false, consumer);
System.out.println(" [x] Awaiting RPC requests");
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
BasicProperties props = delivery.getProperties();
BasicProperties replyProps = new BasicProperties
.Builder()
.correlationId(props.getCorrelationId())
.build();
String message = new String(delivery.getBody());
int n = Integer.parseInt(message);
System.out.println(" [.] fib(" + message + ")");
String response = "" + fib(n);
channel.basicPublish( "", props.getReplyTo(), replyProps, response.getBytes());
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}以上服务端的代码很简单:
- 和通常一样,我们从建立一个连接,一个通道和定义一个队列开始。
- 我们可能需要运行多个服务器进程。为了在多个服务器上均匀分布的负荷,我们需要设置channel.basicQos中的prefetchCount。
- 我们使用basicConsume访问队列。然后,进入while循环中,等待请求消息,完成工作并发送回响应。
RPCClient.java:
private Connection connection;
private Channel channel;
private String requestQueueName = "rpc_queue";
private String replyQueueName;
private QueueingConsumer consumer;
public RPCClient() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
connection = factory.newConnection();
channel = connection.createChannel();
replyQueueName = channel.queueDeclare().getQueue();
consumer = new QueueingConsumer(channel);
channel.basicConsume(replyQueueName, true, consumer);
}
public String call(String message) throws Exception {
String response = null;
String corrId = java.util.UUID.randomUUID().toString();
BasicProperties props = new BasicProperties
.Builder()
.correlationId(corrId)
.replyTo(replyQueueName)
.build();
channel.basicPublish("", requestQueueName, props, message.getBytes());
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
if (delivery.getProperties().getCorrelationId().equals(corrId)) {
response = new String(delivery.getBody());
break;
}
}
return response;
}
public void close() throws Exception {
connection.close();
}客户端的代码稍微复杂:
- 我们建立一个连接,一个通道和一个用于接收回复的回调队列。
- 我们订阅“回调”的队列,这样我们就可以接收RPC响应。
- 我们的call方法发出实际的RPC请求。
- 在这里,我们首先生成一个唯一的correlationID,并保存它 - while循环会使用这个值来捕捉适当的响应。
- 接下来,我们发布请求消息时,具有两个属性:的replyTo和的correlationID。
- 在这一点上,我们可以坐下来,等到适当的响应到达。
- while循环正在做一个很简单的工作,对于每一个响应消息它会检查的correlationID是我们要找的人。如果是,它将保存的响应。
- 最后,我们返回响应给用户。
客户端请求:
RPCClient fibonacciRpc = new RPCClient();
System.out.println(" [x] Requesting fib(30)");
String response = fibonacciRpc.call("30");
System.out.println(" [.] Got '" + response + "'");
fibonacciRpc.close();以上的设计不是唯一可能的实现一个RPC服务的,但它有一些重要的优点:
- 如果RPC服务器速度太慢,则只需运行多个即可。尝试在新的控制台运行的第二RPCServer。
- 在客户端,RPC请求只发送或接收一条消息。不需要像 queue_declare 这样的异步调用。所以RPC客户端的单个请求只需要一个网络往返。
我们的代码依旧非常简单,而且没有试图去解决一些复杂(但是重要)的问题,如:
- 当没有服务器运行时,客户端如何作出反映。
- 客户端是否需要实现类似RPC超时的东西。
- 如果服务器发生故障,并且抛出异常,应该被转发到客户端吗?
- 在处理前,防止混入无效的信息(例如检查边界)
原文地址:https://www.rabbitmq.com/tutorials/tutorial-six-java.html
代码地址:https://github.com/aheizi/hi-mq
相关:
1.RabbitMQ之HelloWorld
2.RabbitMQ之任务队列
3.RabbitMQ之发布订阅
4.RabbitMQ之路由(Routing)
5.RabbitMQ之主题(Topic)
6.RabbitMQ之远程过程调用(RPC)