Hadoop2.6.5+spark2.3.3+jdk1.8.0+Scala2.11.8
配置spark集群之前,要先安装好jdk和Scala
这里只做简要说明(这两个的安装和配置都类似,大概步骤如下):
1、下载对应的压缩包上传至Linux系统;
2、到对应的目录下解压压缩包
3、配置环境变量
4、使用如下命令查看是否安装配置成功
java -version
scala -version
spark集群的配置部署
1、spark的获取
下载地址https://archive.apache.org/dist/spark/
2、上传安装包到虚拟机的/opt/spark/目录下(事先建好的目录)
3、到该目录下解压压缩包
tar -zxvf spark-2.3.3-bin-hadoop2.6.tgz
4、修改/etc/profile配置文件
vim /etc/profile
加入以下的内容
export SPARK_HOME=/opt/spark/spark-2.3.3-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin
保存后,执行以下命令生效配置
source /etc/profile
5、进入conf目录
将spark-env.sh.template复制一份spark-env.sh,对spark-env.sh进行修改

6、vim spark-env.sh
在该文件中加入以下内容
export JAVA_HOME=/usr/lib/jvm/java #自己的jdk路径 export SPARK_MASTER_IP=master1 #注:这里是当前机器的域名或者IP export SPARK_MASTER_PORT=7077
7、配置slaves文件
cp slaves.template slaves
vim slaves
在slaves文件中加入从节点的主机名或者IP地址

8、将配置同步至Slave1和Slave2
在Master的/opt/目录下使用如下命令
scp -r ./spark/ root@Slave1:$PWD
scp -r ./spark/ root@Slave2:$PWD
9、启动集群
在Master主机执行命令
cd /opt/spark/spark-2.3.3-bin-hadoop2.6/sbin ./start-all.sh
使用jps查看启动情况 主节点出现Master代表启动成功
我们再看看从节点,里面出现Worker代表启动成功。
关闭防火墙
systemctl stop firewalld.service
浏览器访问http://192.168.152.131:8001(默认端口8080,我这里修改过)
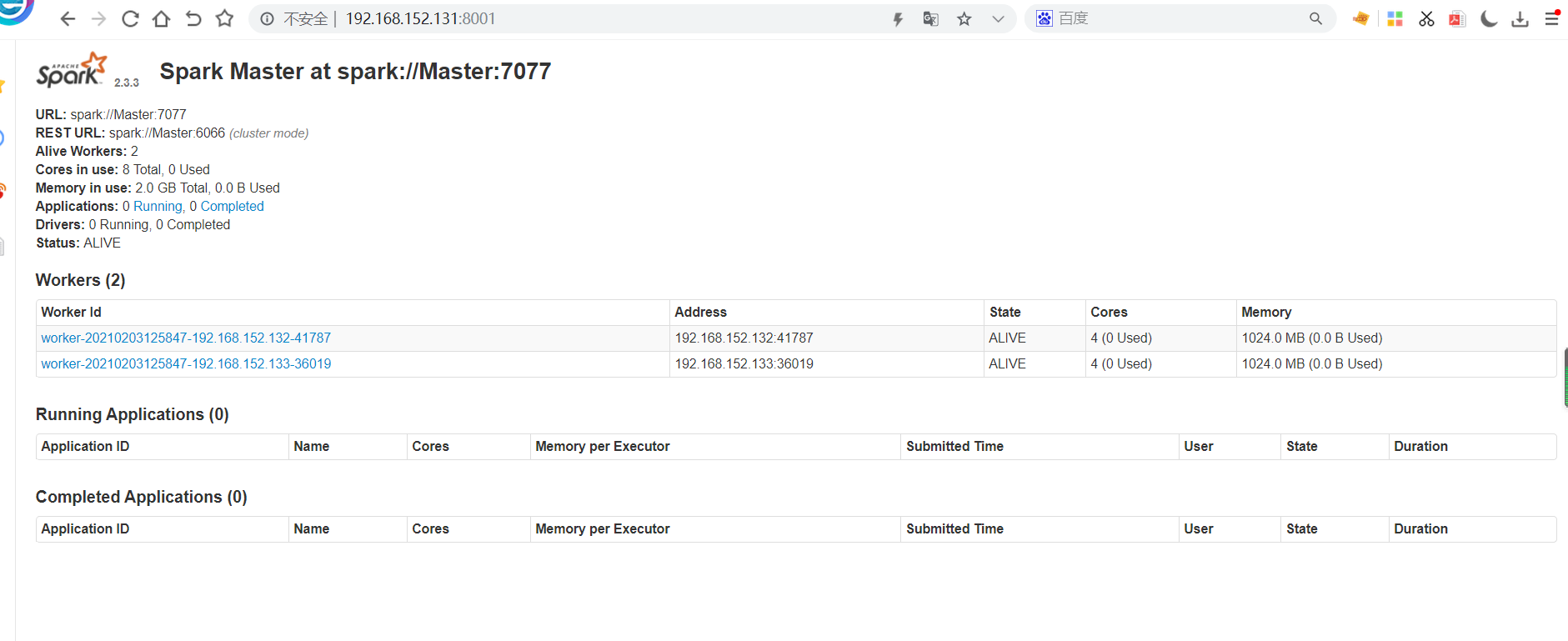
启动成功!
2021-02-03 14:11:48