一、spark的序列化
1.1、官网解释
http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization
序列化在任何分布式应用程序的性能中起着重要作用。将对象序列化或消耗大量字节的速度慢的格式将大大减慢计算速度。通常,这将是您应该优化Spark应用程序的第一件事。Spark旨在在便利性(允许您使用操作中的任何Java类型)和性能之间取得平衡。它提供了两个序列化库:
- Java序列化:默认情况下,Spark使用Java ObjectOutputStream框架序列化对象,并且可以与您创建的任何类一起使用java.io.Serializable。您还可以通过扩展来更紧密地控制序列化的性能 java.io.Externalizable。Java序列化是灵活的,但通常很慢,并导致许多类的大型序列化格式。
- Kryo序列化:Spark还可以使用Kryo库(版本2)更快地序列化对象。Kryo比Java序列化(通常高达10倍)显着更快,更紧凑,但不支持所有Serializable类型,并且需要您提前注册您将在程序中使用的类以获得最佳性能。
1.2、Serializable方案
- Serializable方案:你的对象必须继承Serializable接口,类中的属性如果有实例那也必须是继承Serializable 可序列化的。
- 无法序列化:用transient修饰的。java是在修饰属性的最前面使用transient关键字,scala是在修饰属性的最前面使用@transient
- transient的作用是在Serializable序列化的时候,声明某个属性不参与序列化,带来的问题就是如果声明了不参与序列化,那这个属性存储的数据也带不过去了。
1.3、kryo方案
能用于广播变量和shuffle数据传输时候的序列化,外部变量和算子中的代码必须用Serializable
- 设置spark的全序列化:conf.set("spark.serializer", classOf[KryoSerializer].getName)
- 这时spark的全局序列化工具就变成了KryoSerializer而不是默认的Serializable方案了
- 当不设置conf.set("spark.kryo.registrationRequired","true")时,spark的所有对象都默认使用KryoSerializer序列化
- 当设置了conf.set("spark.kryo.registrationRequired","true")时,spark中自定义的类想被KryoSerializer序列化的对象必须得进行注册。
-
val classes: Array[Class[_]] = Array[Class[_]](classOf[ORCUtil],classOf[StructObjectInspector],classOf[OrcStruct]) //classOf[OrcStruct] OrcStruct:注册的类 conf.set("spark.serializer", classOf[KryoSerializer].getName) conf.set("spark.kryo.registrationRequired","true") conf.registerKryoClasses(classes)
-
-
如果对象很大,则可能还需要增加
spark.kryoserializer.bufferconfig。该值必须足够大以容纳要序列化的最大对象。
二、GC对spark性能的影响
2.1、频繁GC的影响

2.2、task运行期间动态创建的对象使用的Jvm堆内存的情况
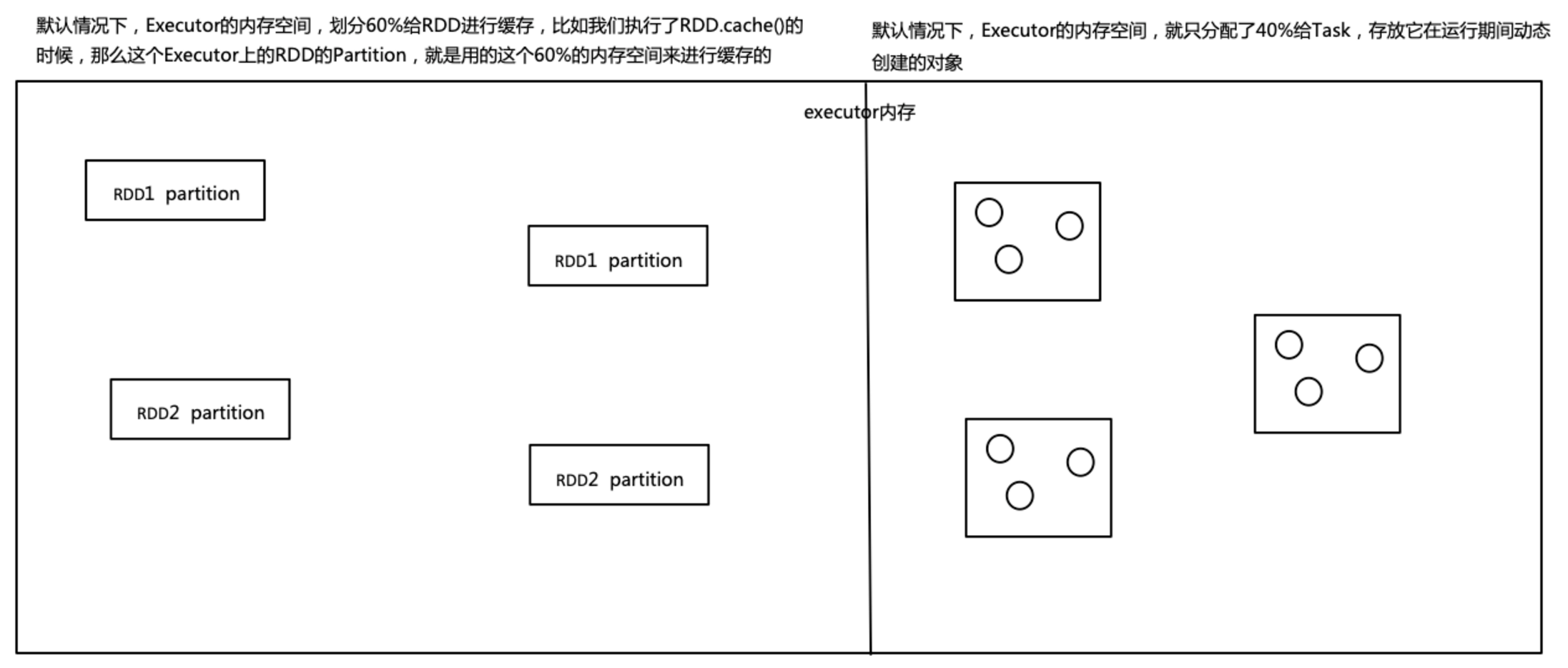
在默认情况下,就是分配给Task运行期间动态创建的内存空间有点小了,就很可能会发生full gc
因为内存小了就会导致,创建的对象很快就把内存空间填满了,然后就会GC了,就是JVM尝试找到那些不再被使用的对象,然后将其回收掉,清除出内存,腾出空间,给Task以后创建的新对象来使用和存放
所以说,如果给Task分配的内存空间小了,可能会频繁的发生GC,从而导致频繁的Task工作线程的停止,从而降低Spark应用程序的性能
解决方法:
- 可以通过调整比例,比如将RDD缓存空间占比调为40%,分配给Task的空间就变为60%,这样的话,至少可以降低GC发生的频率
- 还可以配合降低RDD的使用内存的空间,比如调节序列化的级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,让RDD的partition序列化成一个字节的数组
- 还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量
2.3、JVM的minor gc(小级别)与full gc(大级别)原理
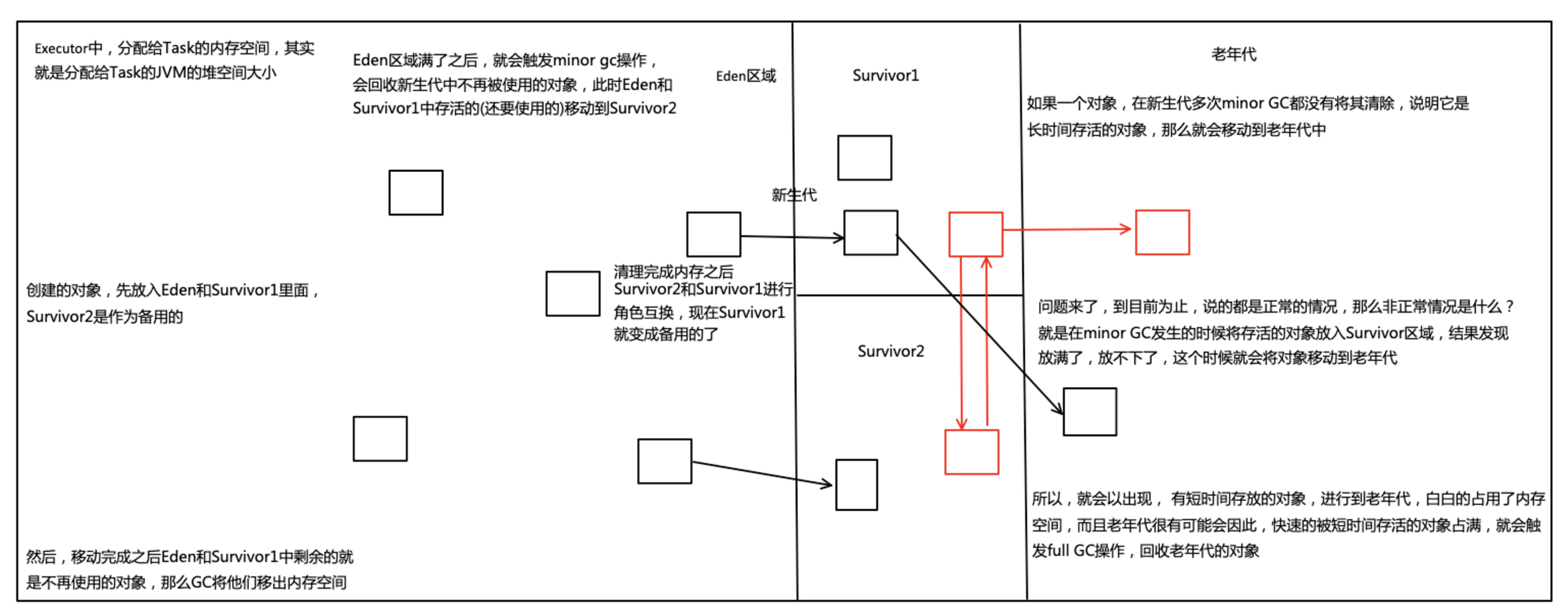
总结:
- 内存分为新生代和老年代,新生代分为Eden和Survivor(有2个)
- 创建的对象,首先放入Eden和Survivor1(可能是短时间)的
- 当Eden满了会启动minor gc,回收新生代中不再使用的对象,还要用的就放到Survivor2中
- 移完之后eden和Survivor1中省下的就是不再使用的对象,就将他们清理掉
- Survivor1和Survivor2交换角色。那就是原来的Survivor1成了备用的了,也就是原来的Survivor2
- 多次在Survivor区没有被清理掉的,说明它是长时间使用的,那么将它移动到老年代,到目前为止世界一切和平
- 由于对象越New越多,minor时发生备用的Survivor区满了,放不进去了,怎么办呢?这个本来可能是短时间生存的对象被放入老年代
- 短时间生存的对象,很可能快速的给老年代占满,白白的浪费老年代的空间,就会触发Full GC,回收老年代的对象