1.常用命令
| 命令 | 说明 | 返回值 | 时间复杂度 |
|---|---|---|---|
| keys */[pattern] | 遍历所有符合条件的key,一般不在生产环境使用 | 所有key | O(n) |
| dbsize | 计算key的总数 | n | O(1) |
| exists key | 判断一个key是否存在 | 0、1 | O(1) |
| del key [key...] | 删除指定的key-value | 0、1 | O(1) |
| expire key seconds | 指定key在seconds秒后过期 | 0、1 | O(1) |
| ttl key | 查询key剩余的过期时间 | 剩余时间(返回-2表示key已经被删除了,-1表示不过期) | O(1) |
| persist key | 去掉key的过期时间 | 0、1 | O(1) |
| type key | 查询key的类型 | string、hash、list、set、zset、none | O(1) |
2.单线程Redis为什么这么快?
- 纯内存
- 非阻塞IO
- 单线程避免了线程切换和竞态消耗
单线程要注意:
- 一次只能运行一条命令
- 拒绝长(慢)命令:keys、flushall、flushdb、slow lua script、mutil/exec、operate big value
2.数据类型
string类型
字符串是Redis中最常用的类型,是一个由字节组成的序列,它在Redis中是二进制安全的,该类型可以接受任何格式的数据。value最多可以容纳的数据长度为512MB。
使用场景:
- 缓存
- 计数器
- 分布式锁
- 分布式id生成
常用命令:
| 命令 | 说明 | 例子 |
|---|---|---|
| get key | 获取key的值 | get name |
| mget key1 key2 ... | 批量获取key1、key2的值 | mget name age |
| set key value | 设置key的值为value,不管key是否存在都设置 | set name mike |
| setnx key value | 设置key的值为value,key不存在才设置 | setnx name mike |
| set key value xx | 设置key的值为value,key存在才设置 | setxx name mike xx |
| mset key1 value1 key2 value2 ... | 批量设置key1的值为value1,key2的值为value2... | mset name lucy age 10 |
| del key | 删除key | del name |
| incr key | key的值加1 | incr age |
| decr key | key的值减1 | decr age |
| incrby key k | key的值加k | incrby age 10 |
| decrby key k | key的值减k | decrby age 10 |
| getset key newvalue | set key newvalue并返回旧的value | getset name alice |
| append key value | 将value追加到旧的value | append name hh |
| strlen key | 获取key的字符串长度(注意中文) | strlen name |
| incrbyfloat key f | 为key的值增加f,用于浮点数据 | incrbyfloat monery 9.9 |
| getrange key start end | 获取字符串指定下标所有的值 | getrange name 1 2 |
| setrange key index value | 设置指定下标所有对应的值 | setrange name 1 aa |
hash类型
一个key中存在多个map。Redis中的hash可以看成具有String key和String value的map容器,可以将多个key-value存储到一个key中。每一个Hash可以存储4294967295个键值对
使用场景:
- 存储用户信息
常用命令:
| 命令 | 说明 | 例子 |
|---|---|---|
| hget key field | 获取hash key下的field的value | hget user name |
| hset key field value | 设置hash key下的field的的值为value | hset user name zhangsan |
| hdel key field | 删除hash key下的field | hdel user name |
| hexists key field | 判断hash key下的field是否存在 | hexists user name |
| hlen key | 获取hash key下的field数量 | hlen user |
| hmget key field1 field2 ... | 批量获取hash key下的field1、field2的值 | hmget user name age |
| hmset key field1 value1 field2 value2 ... | 批量设置hash key下的field1值为value、field2值为value2 | hmset user age 20 phone 15000000000 |
| hgetall key | 获取hash key下的所有field和value | hgetall user |
| hvals key | 获取hash key下的所有field的value | hvals user |
| hkeys key | 获取hash key下的所有field | hkeys user |
| hsetnx key field value | 设置hash key下的field的的值为value(如果field存在则不设置) | hsetnx user name lisi |
| hincrby key field n | 设置hash key下的field的的值加n | hincrby user age 10 |
| hincrbyfloat key field f | 设置hash key下的field的的值加f(浮点数版) | hincrbyfloat user balance 9.9 |
list(列表)类型
Redis的列表是有序的,允许用户从序列的两端推入或者弹出元素,列表由多个字符串值组成的有序可重复的序列,是链表结构,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。List中可以包含的最大元素数量是4294967295
使用场景:
- 微博最新消息排行榜
- 简单的消息队列
常用命令:
| 命令 | 说明 | 例子 | 结果 |
|---|---|---|---|
| lpush key value1 value2 ... | 从列表左端插入值 | lpush list1 c b a | abc |
| rpush key value1 value2 ... | 从列表右端插入值 | rpush list2 a b c | abc |
| linsert key before|after value newValue | 在指定的值前|后插入newValue | linsert list after a A | a b c d => a A b c d |
| lpop key | 从列表左侧弹出一个item | lpop list1 | a |
| rpop key | 从列表右侧弹出一个item | rpop list2 | c |
| lrem key count value | 根据count值,从列表中删除所有value相等的项 1.count>0,从左到右,删除最多count个value相等的项 2.count<0,从右到左,删除最多Math.abs(count)个value相等的项 3.count=0,删除所有value相等的项 |
lrem list 2 a lrem list -2 a lrem list 0 a |
a b a c a d => b c a d a b a c a d => a b c d a b a c a d => b c d |
| ltrim key start end | 按照索引范围修剪列表 | ltrim list 1 4 | a b c d e f => b c d e |
| lrange key start end | 获取列表指定索引范围内的项(包含end) | lrange list 0 1 | a b c d e f => a b |
| lindex key index | 获取列表指定索引的的项 | lindex list 1 | a b c d => b |
| llen key | 获取列表的长度 | llen list | a b c d => 4 |
| lset key index newValue | 设置列表指定索引的值为newValue | lset list 2 x | a b c d => a b x d |
| blpop key timeout | lpop的阻塞版本,timeout是阻塞超时时间,timeout=0为永远不阻塞,如果列表中没有值他会一直等待一个新的值插入 | blpop list 100 | |
| brpop key timeout | rpop的阻塞版本,timeout是阻塞超时时间,timeout=0为永远不阻塞,如果列表中没有值他会一直等待一个新的值插入 | brpop list 100 |
注意:
- lpush + lpop = Stack (实现一个栈的功能)
- lpush + rpop = Queue (实现一个队列功能)
- lpush + ltrim = Capped Collection (实现有固定数量的列表)
- lpush + brpop = Message Queue (实现消息队列)
set(集合)类型
Redis的集合是无序不可重复的。和列表一样,在执行插入和删除以及判断是否存在某元素时,效率是很高的。集合最大的优势在于可以进行交集并集差集操作。Set可包含的最大元素数量是4294967295
使用场景:
- 使用交集求共同好友
- 类似微博好友推荐,可以根据tag求交集
- 利用唯一性,可以统计访问网站的所有独立IP
常用命令:
| 命令 | 说明 | 例子 | 结果 |
|---|---|---|---|
| sadd key element | 向集合中添加element(可以是多个,如果element已存在,则会添加失败) | sadd set a b c | a b c |
| srem key element | 将集合key中的element删除 | srem set a | a b c => d c |
| scard key | 计算集合大小 | scard set | a b c => 3 |
| sismember key value | 判断value是否在集合key中存在 | sismember set a | a b c => 1 |
| srandmember key [count] | 从集合中随机挑选count个元素,默认为1,不会破坏集合 | srandmember key | a b c => b |
| spop key [count] | 从集合中随机弹出count个元素,默认为1,会将元素从集合中删除 | spop set | a b c => a c |
| smembers key | 获取集合中所有元素 | smembers set | a b c => c a b |
| sdiff key1 key2 | 获取key1、key2的差集 | sdiff set1 set2 | a b c d e,a d e f g => c b |
| sinter key1 key2 | 获取key1、key2的交集 | sinter set1 set2 | a b c d e,a d e f g => a d e |
| sunion key1 key2 | 获取key1、key2的并集 | sunion set1 set2 | a b c d e,a d e f g => a b c d e f g |
zset(有序集合)类型
有序集合有顺序,不能重复。元素不能重复,score可以重复。
和Set很像,都是集合,都不允许出现重复的元素。
和Set之间差别在于有序集合中每一个成员都会有一个分数(score)与之关联,Redis正是通过分数来为集合中的成员进行从小到大的排序。尽管有序集合中的成员必须是卫衣的,但是分数(score)却可以重复
使用场景:
- 各种游戏排行榜、音乐排行榜等
常用命令:
| 命令 | 说明 | 例子 | 结果 |
|---|---|---|---|
| zadd key score1 element1 score2 element2 ... | 向有序集合中添加score和element(score可重复,element不可重复) | zadd zset 10 a 20 b | |
| zrem key element1 element2 ... | 删除元素 | zrem zset a b | |
| zscore key element | 返回元素element的分数 | zscore zset a | 10 |
| zincrby key increScore element | 将元素element的score增加increScore | zincrby zset 10 a | 20 |
| zcard key | 返回元素的总个数 | zcard zset | a b => 2 |
| zrank key element | 获取元素element的排名 | zrank zset a | |
| zrange key start end [withscores] | 返回指定索引范围内的升序元素(根据score) | zrange zset 0 100 withscores | 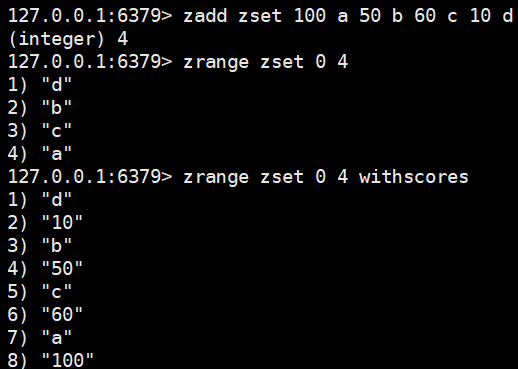 |
| zrangebyscore key minScore maxScore [withscores] | 获取指定分数范围内的升序元素(根据score) | zrangebyscore zset 50 100 withscores | 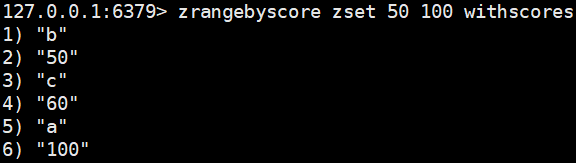 |
| zcount key minScore maxScore | 获取在指定分数范围内的元素个数 | zcount zset 60 100 | 2 |
| zremrangebyrank key start end | 删除指定排名内的升序元素 | zremrangebyrank zset 0 1 | 剩下a c |
| zremrangebyscore key minScore maxScore | 删除指定分数内的升序元素 | zremrangebyscore zset 0 50 | 剩余a c |
| zrevrank key element | 与zrank相反,获取从高到低的排名 | ||
| zrevrange key start end [withscores] | 与zrange相反,返回从高到低的分数排名 | ||
| zrangebyscore key minScore maxScore [withscores] | 与zrangebyscore相反,返回指定分数范围内从高到低的排名 | ||
| zinterstore key1 key2 | 计算两个集合交集 | ||
| zunionstore key1 key2 | 计算两个集合并集 |