谱聚类的原理参考https://www.cnblogs.com/pinard/p/6221564.html
clear all
clc
%% 产生非线性可分的数据, Mr. Mohammadi's program
N1 = 100;
N2 = 200;
r1=0.5;
X1=r1*randn(N1,2);% 返回标准正态分布随机数组成的N1*2的矩阵
r2=3;
r3=4;
R=unifrnd(r2,r3,[N2 1]);% 生成(连续)均匀分布的随机数 返回N2 *1的矩阵
theta=unifrnd(-pi/2,+3*pi/2,[N2 1]);
X2=[R.*cos(theta) R.*sin(theta)];
X=[X1; X2];
figure(1);hold off
plot(X(:,1),X(:,2),'ko');
%% 计算W矩阵
% X 300*2
N = size(X,1);
W = zeros(N);
for n = 1:N
for n2 = 1:N
W(n,n2) = exp(-sum((X(n,:)-X(n2,:)).^2)); % Gaussian
end
end
%% 计算D矩阵
D = zeros(N);
for i = 1:N
D(i,i) = sum(W(i,:),2);
end
%% 计算标准化的L矩阵
L = zeros(N);
I= eye(N);
D = D^(-1/2);
L = I - D*W*D;
%% 初始
K = 2;
H = repmat([1 0],N,1);
% H分簇信息
cols = {'r','g'};
%% 特征值分解
% 特征值
U = zeros(K);
[H,U] = eigs(L,K,'sm');
%% 对H标准化
for i = 1:N
o = (H(i,1)^2+ H(i,2)^2)^(1/2);
H(i,1) = H(i,1)/o;
H(i,2) = H(i,2)/o;
end
%% K-means
Z = kmeans(H,K);
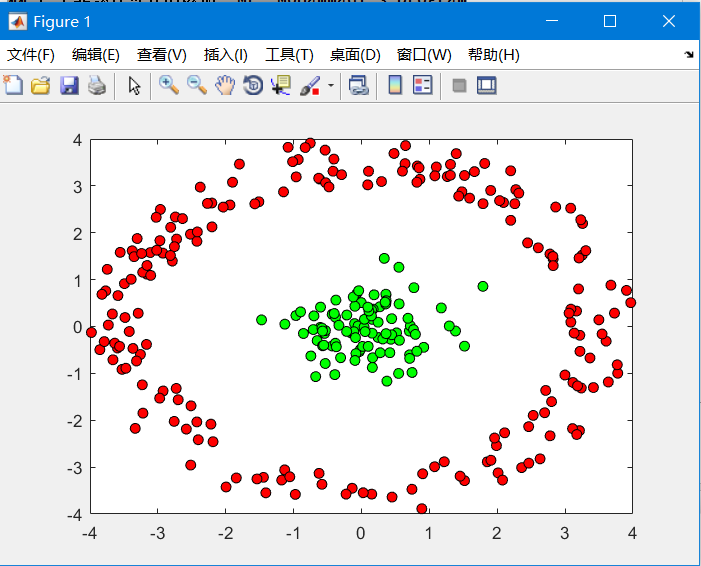
%% 画图
figure(1);hold off
for i=1:N
if(Z(i,1)==1)
plot(X(i,1),X(i,2),'ko','markerfacecolor',cols{1});
else
plot(X(i,1),X(i,2),'ko','markerfacecolor',cols{2});
end
hold on
end
% 'markerfacecolor'数据点的实心填充
pause(1)
效果图