方法类
package com.wxf.Test; import com.wxf.pojo.Goods; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.StringField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.*; import org.apache.lucene.queryparser.classic.ParseException; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.IOException; import java.nio.file.Paths; /** * @Auther: wxf * @Date: 2018/6/29 15:40 */ public class IndexCRUD { private Directory dir; { try { dir = FSDirectory.open(Paths.get( System.getProperty("user.dir")+"\src\main\resources\index")); } catch (IOException e) { e.printStackTrace(); } } /** * 获取IndexWriter实例 * @return * @throws Exception */ public IndexWriter getWriter()throws Exception{ //中文分词器 StandardAnalyzer standardAnalyzer = new StandardAnalyzer(); IndexWriterConfig iwc=new IndexWriterConfig(standardAnalyzer); IndexWriter writer=new IndexWriter(dir, iwc); return writer; } public void setUp() throws Exception { Goods goods=new Goods("123","红色强化门",360); Goods goods2=new Goods("223","黑色强化门",370); Goods goods3=new Goods("333","白色强化门",380); String skuid[]={"123","223","333"}; String name[]={"红色强化门","黑色强化门","白色强化门"}; Object obj[]={goods,goods2,goods3}; IndexWriter writer=getWriter(); for(int i=0;i<skuid.length;i++){ Document doc=new Document(); doc.add(new StringField("skuid", skuid[i], Field.Store.YES)); doc.add(new TextField("name",name[i],Field.Store.YES)); doc.add(new TextField("obj", obj[i].toString(), Field.Store.YES)); writer.addDocument(doc); // 添加文档 } writer.close(); } /** * 测试写了几个文档 * @throws Exception */ public void testIndexWriter()throws Exception{ IndexWriter writer=getWriter(); System.out.println("写入了"+writer.numDocs()+"个文档"); writer.close(); } /** * 测试读取文档 * @throws Exception */ public void testIndexReader()throws Exception{ IndexReader reader=DirectoryReader.open(dir); System.out.println("最大文档数:"+reader.maxDoc()); System.out.println("实际文档数:"+reader.numDocs()); reader.close(); } /** * 查询 * @return */ public void select(String str1,String str2) throws IOException, ParseException { //得到读取索引文件的路径 Directory dir = FSDirectory.open(Paths.get(System.getProperty("user.dir")+"\src\main\resources\index")); IndexReader ireader = DirectoryReader.open(dir); IndexSearcher searcher = new IndexSearcher(ireader); StandardAnalyzer standardAnalyzer = new StandardAnalyzer(); /** * 第一个参数是要查询的字段; * 第二个参数是分析器Analyzer * */ QueryParser parser = new QueryParser(str1, standardAnalyzer); //根据传进来的str2查找 Query query = parser.parse(str2); //计算索引开始时间 long start = System.currentTimeMillis(); /** * 第一个参数是通过传过来的参数来查找得到的query; * 第二个参数是要出查询的行数 * */ TopDocs rs = searcher.search(query, 10); long end = System.currentTimeMillis(); System.out.println("匹配"+str2+",总共花费了"+(end-start)+"毫秒,共查到"+rs.totalHits+"条记录。"); for (int i = 0; i < rs.scoreDocs.length; i++) { Document doc = searcher.doc(rs.scoreDocs[i].doc); System.out.println("skuid:" + doc.getField("skuid").stringValue()); System.out.println("name:" + doc.getField("name").stringValue()); System.out.println("obj:" + doc.getField("obj").stringValue()); } } }
测试类
package com.wxf.Test;
/**
* @Auther: wxf
* @Date: 2018/6/29 15:46
*/
public class Test {
public static void main(String[] args) throws Exception {
IndexCRUD indexCRUD=new IndexCRUD();
// indexCRUD.setUp();
indexCRUD.testIndexWriter();
indexCRUD.testIndexReader();
indexCRUD.select("name", "黑");
}
}
indexCRUD.setUp() 这个方法 调一次就可以了
结果如下

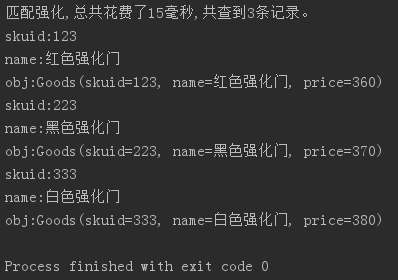
这次换个范围大的查询参数
public class Test {
public static void main(String[] args) throws Exception {
IndexCRUD indexCRUD=new IndexCRUD();
// indexCRUD.setUp();
indexCRUD.testIndexWriter();
indexCRUD.testIndexReader();
indexCRUD.select("name", "强化");
}
}
结果如下:
这里采用一元分词 可以随意匹配