20182301 2019-2020-1 《数据结构与面向对象程序设计》第7周学习总结
教材学习内容总结
第十二章
- 算法效率:用更少的时间去做同等质量的事情
- 好算法的要求:正确性、可读性、健壮性、通用性、效率与储存空间需求
- 算法效率可以用问题大小(n)和及处理步骤来定义。增长函数表示问题大小与希望优化的值之间的关系,该函数表示算法的时间或空间利用率
- 复杂度(时间、空间)
图:

- 注意:若计算一个算法的阶,其中涉及函数调用时,要把函数里面的调用也算上。
第十四章
- 集合
- 集合是收集并组织其他对象的对象
- 集合定义了访问及管理称为集合元素的其他对象的一种具体方式
- 集合中的元素一般由加入集合的次序或元素之间某些固有的关系而组织
- 集合是隐藏其实现细节的一个抽象名称
- 数据结构是用来实现集合的基本程序设计结构
- 栈集合
- 栈以LIFO的方式处理元素——最后进入的元素最先离开
- 程序员应该选择与所需管理的数据的类型相匹配的结构
| 操作 | 描述 |
|---|---|
| push | 将元素添加到栈顶 |
| pop | 删除栈顶元素 |
| peek | 查看栈顶元素 |
| isEmpty | 是否为空 |
| size | 判定栈中元素 |
- 泛型
- Java允许泛型来定义类
- 不允许泛型实例化
- 当需要Box时,可以用具体的类来取代T,从而实例化它
class Box<T>
{
//T类型对象的声明和操作代码
}
Box<Widge> box1=new Box<Widege>;
- 栈的ADT
- Java接口定义了一组抽象方法,能用来将抽象数据类型概念与它的现实分开
- 栈接口定义为Stack
,是对泛型T进行操作的。接口中方法的各参数的类型及返回值也常常表示为泛型T。实现这个接口,要基于取代T的一个具体类型 - 接口机制可让方法与实现栈的具体的类分开
- 使用栈计算后缀表达式
- 具体代码可看书P325页或者实践作业
图:
- 具体代码可看书P325页或者实践作业

- 异常
if(!theStack.isEmpty())
element = theStack.pop();
try{
element = theStack.pop();
}catch(EmptyCollectionException exception){
System.out.println("No elements available.")
}
- 使用数组实现栈
- 集合操作的实现细节不应该影响使用者与集合进行交互的方式
- 比如:设计集合时的一个重要问题是,将新元素添加到已满的数据结构时要做什么。有三种选择:
- 可以这样实现操作;向集合中添加一个元素时,如果数据结构满了则抛出一个异常。
- 实现add操作时,让它返回一个状态指示符,用户据此来检查add操作是否成功。
- 当需要时自动扩展基本数据结构的容量,所以它永远不会满。
- ArrayStack类
- ArrayStack
是基于数组实现的,可保存泛型T栈的集合 - 注意以下几点:
- 数组是对象引用的数组(栈实例化时才确定类型)
- 栈底总位于数组下标为0的位置,
- 栈中元素按序并连续保存在数组中
- 整型变量count保存栈中栈顶元素下一个位置的下标。
- 不能泛型实例化数组,于是:
- ArrayStack
stack=(T[])(new Object[stack.length*2);
- ArrayStack类数组操作
- push操作
- 确保栈不满
- 数组count位置的引用指向要入栈的对象
- count值加一
- push操作的阶是O(1)
- pop操作
- 确保栈不空。
- 计数器count减1。
- 临时引用指向stack[ count]。
- stack[ count ]置为null。
- 返回临时引用。
- pop操作的阶是O(1)
- peek操作
- peek操作返回对栈顶元素的引用,但不将它移出数组。对于数组实现方式,这意味着返回count-1位置的元素的引用。
- peek方法的阶是O(1)。
- push操作
- 链表
- 链表需要动态变大,本质上没有容量限制
- 链表由对象组成,其中每个链表的对象指向下一个对象
- 访问元素
String searchstring = "Tom Jones ";
Person current = first;
while ( ( not( current . equals ( searchstring)) && (current.next != null) )
current = current. next;
- 插入结点
temp.next=current.next;
current.next=temp;
- 删除结点
- 见代码问题1
第十五章
- 队列是一种先进先出(First In First Out,FIFO)的数据结构,如果你将两个元素加入队列,先加入的元素将在后加入的元素之前出队。
更新队列时,使用术语“入队”和“出队”,但也可能遇到术语“压入”和“弹出”。压入大致相当于入队,而弹出大致相当于出队。
Queue<Integer> queue = new LinkedList<>();
queue.offer(1); //进队
queue.offer(2);
queue.offer(3);
queue.forEach(integer -> {
System.out.println(integer);
});
System.out.println("------------------------");
System.out.println("poll=" + queue.poll());//获取第一个元素并删除
queue.forEach(integer -> {
System.out.println(integer);
});
System.out.println("------------------------");
System.out.println("element=" + queue.element());//获取第一个元素
queue.forEach(integer -> {
System.out.println(integer);
});
System.out.println("------------------------");
System.out.println("peek=" + queue.peek());//获取第一个元素
queue.forEach(integer -> {
System.out.println(integer);
});
教材学习中的问题和解决过程
- 问题1:接口Comparable究竟怎么用?
- 问题1解决方案:(详见链接一)
- 我认为通过代码能够更好地了解:String和Integer这两个类都实现了Comparable接口,都对compareTo方法进行了实现,下面我们通过源码来看一下它们各自对于该方法的具体实现:
private final char value[];//String的底层是字符数组 a.compareTo(b)
public int compareTo(String anotherString) {
int len1 = value.length;//获取调用该方法的字符串的长度a
int len2 = anotherString.value.length;//获取比较字符串的长度b
int lim = Math.min(len1, len2);//(a <= b) ? a : b; min底层代码 这句代码是为了获取较短的字符串的长度
char v1[] = value; //创建两个字符数组,分别指向这两个字符串的所在
char v2[] = anotherString.value;
//循环比较,循环次数,是较短的字符串的长度,如果用较长的字符串的长度,那么会出现nullPointException
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
//比较相对应索引的元素,如果元素不同则比较返回中间差距的顺序,如果相等,那么就继续循环比较
if (c1 != c2) {
return c1 - c2;//字符对应的Unicode码表中的数字,这也就是为什么说String是按照字典书序比较的,如a比b靠前,那么a对应的数字比b小,相减返回负数,差多少顺序,就返回多少
}
k++;
}
//如果两个字符串的长度不同,其它都相同,那么返回的就是长度的差距了
return len1 - len2;
}
//Integer的compareTo方法,底层依据的是compare方法,这个方法是Comparator接口的一个方法
public int compareTo(Integer anotherInteger) {
//实际上Integer的比较是通过Integer中包括的整数来比较的
return compare(this.value, anotherInteger.value);
}
public static int compare(int x, int y) {//a.compateTo(b)
//如果a比b小,那么返回-1,相等就是0,否则就是1
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
-
问题2:列表和链表的区别是什么?
-
问题2的解决方法:(详见链接五)
-
顺序表和链表由于存储结构上的差异,导致它们具有不同的特点,适用于不同的场景。通过系统地学习顺序表和链表我们知道,虽然它们同属于线性表,但数据的存储结构有本质的不同。
- 顺序表存储数据,需预先申请一整块足够大的存储空间,然后将数据按照次序逐一存储,数据之间紧密贴合,不留一丝空隙
- 链表的存储方式与顺序表截然相反,什么时候存储数据,什么时候才申请存储空间,数据之间的逻辑关系依靠每个数据元素携带的指针维持。图:
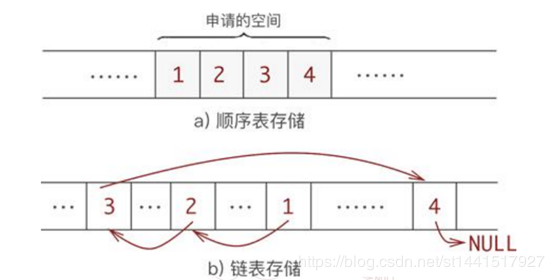
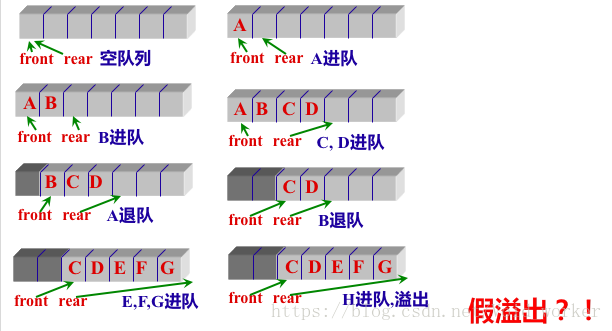
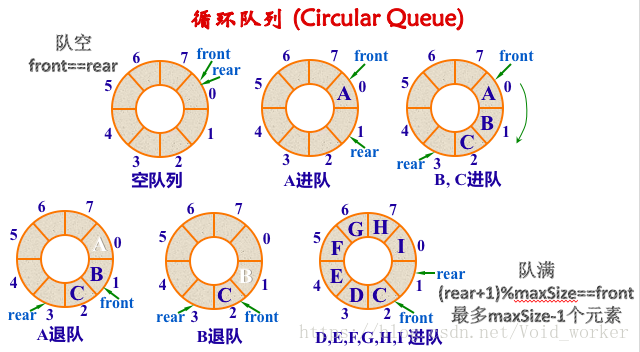
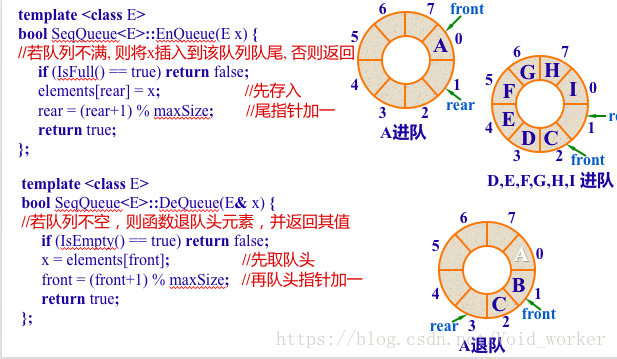
- 问题3:循环链表究竟是空队列还是满队列,是否假溢出?
- 问题3解决方案:(详见链接三)
图

- 问题4:时间复杂度和空间复杂度怎么算?
- 问题4解决方法:(详见链接四)
- 时间复杂度实际上就是一个函数,该函数计算的是执行基本操作的次数
- 大O渐进表示法
- 一个算法语句总的执行次数是关于问题规模N的某个函数,记为分f(N),N称为问题的规模。
- 语句总的执行次数记为T[N],当N不断变化时,T[N]也在变化,算法的执行次数的增长速率和f(N)的增长速率相同。
- 则T[N]=O(f(N)),称O(f(N))为时间复杂度的O渐进表示法。
- 一个程序的空间复杂度是指运行完一个程序所需内存的大小。利用程序的空间复杂度,可以对程序的运行所需要
的内存多少有个预先估计。一个程序执行时除了需要存储空间和存储本身所使用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为现实计算所需信息的辅助空间。程序执行时所需存储空
间包括以下两部分。- 固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间
)、数据空间(常量、简单变量)等所占的空间。这部分属于静态空间。 - 可变空间,这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等。这部分的空间大小与算法
有关。
- 固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间
代码调试中的问题和解决过程
- 问题1:如何删除单链表的第i个结点,两种方法详细介绍
- 问题1解决方案:(详见链接二)
- 第一种
@Override
public void remove(int i) throws Exception
{
// 初始化,p指向首结点,j为计数器
Node p = head;
int j = -1;
// 寻找第i个结点的前驱
while (p.getNext() != null && j < i - 1)
{
p = p.getNext();
++j;
}
if (j > i - 1 || p.getNext() == null)
{
throw new Exception("删除位置不合法");
}
// 修改链指针,使待删除结点从单链表中脱离
p.setNext(p.getNext().getNext());
}
- 第二种
temp.next=temp.next.next;
- 问题2:泛型究竟如何运用?
- 问题2解决方法:(详见链接六)
- 你可以写一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
- 下面是定义泛型方法的规则:
- 所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在方法返回类型之前。
- 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符。
- 泛型方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像int,double,char的等)。
总代码
第十四章
代码托管第十四章
书本代码第十四章
第十五章
代码托管第十五章
书本代码第十五章
(statistics.sh脚本的运行结果截图)

上周考试错题总结
最近无检测,故无错题
点评过的同学博客和代码
- 本周结对学习情况
- 20182326
- 结对照片


- 结对学习内容
- 学习栈
- 学习队列
- 上周博客互评情况
其他(感悟、思考等,可选)
要努力学习把IDEA的代码转到Android,还有Android的布局
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 69/69 | 2/2 | 30/30 | |
| 第二、三周 | 529/598 | 3/5 | 25/55 | |
| 第四周 | 300/1300 | 2/7 | 25/80 | |
| 第五周 | 2665/3563 | 2/9 | 30/110 | 接口与远程 |
| 第六周 | 1108/4671 | 1/10 | 25/135 | 多态与异常 |
| 第七周 | 1946/6617 | 3/13 | 25/160 | 栈、队列 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:30小时
-
实际学习时间:25小时
-
改进情况:
这周的别的事情较多,所以很急,以后一定好好把本次课程复习一下。