问题:某业务系统在运行一段时间后,某个API一定概率偶现Connection reset现象。
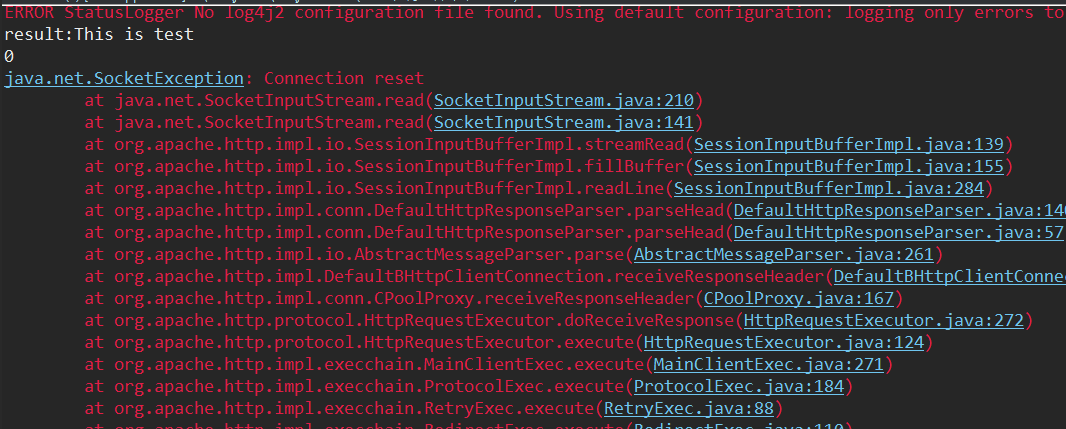
问题定位:
首先想到的是要本地复现出这个问题,但一直复现不出来。
- 同时启动tcp_timestamps和tcp_tw_recycle可能会导致客户端连接不上前提条件是server主动断开过与客户端的连接(可能是服务重启等原因),导致server处于TIME_WAIT状态的socket被快速回收,如果在TCP_PAWS_MSL时间内接收到客户端经NAT发过来的报文的时间戳小于前一个连接保存的时间戳,该报文会被认为是老链路残留的报文而丢弃。进而可以得出:
- 在NAT场景下一定不能启用tcp_tw_recycle;
- NAT场景下单独启动tcp_timestamps不会影响正常使用,连接断链后会在2MSL过后回收socket;
- 生产中不要使用tcp_tw_recycle,即使没有使用到NAT设备,但当前虚拟化环境下用到NAT的地方很多,如kubernetes的service等
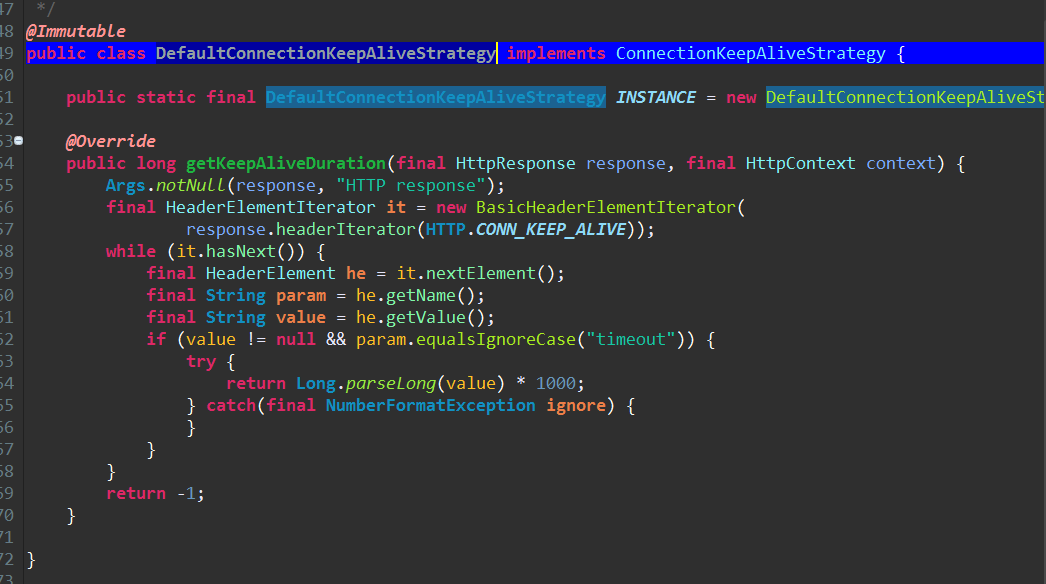
8、但考虑服务端有设置60s的超时时间,不会出现那么大概率的问题
9、可以通过在返回header头中加入timeout时间,强制给客户端设置一个长连接超时时间。如
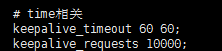
10、去掉默认策略。(因为特殊原因不能让客户端改)仍然不能解决问题。
11、修改测试任务发送的时间,发现sleep时间在30S内不会出现该问题,sleep时间在30-60s会50%概率出现。
12、查询所有链路上的(客户端、lvs、nginx)的相关系统参数超时配置,修改均无效。
13、在设置为32S sleep的场景抓包分析。客户端抓包如下,发现在32S用同一个连接去发送数据后,服务端返回了一个RST(重置连接)信号。但对比服务端nginx日志,并未发现收到该包。怀疑问题出现在LVS
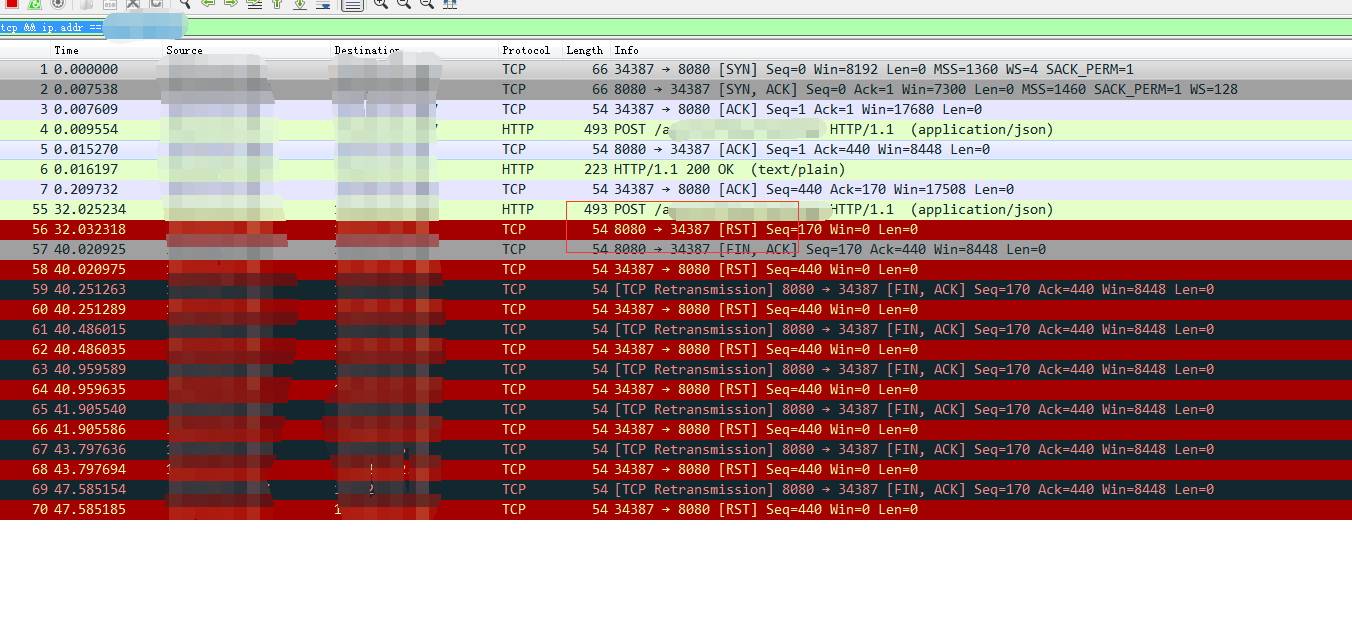
14、LVS上抓包,发现是LVS上回复了RST重置连接的包。检查LVS配置
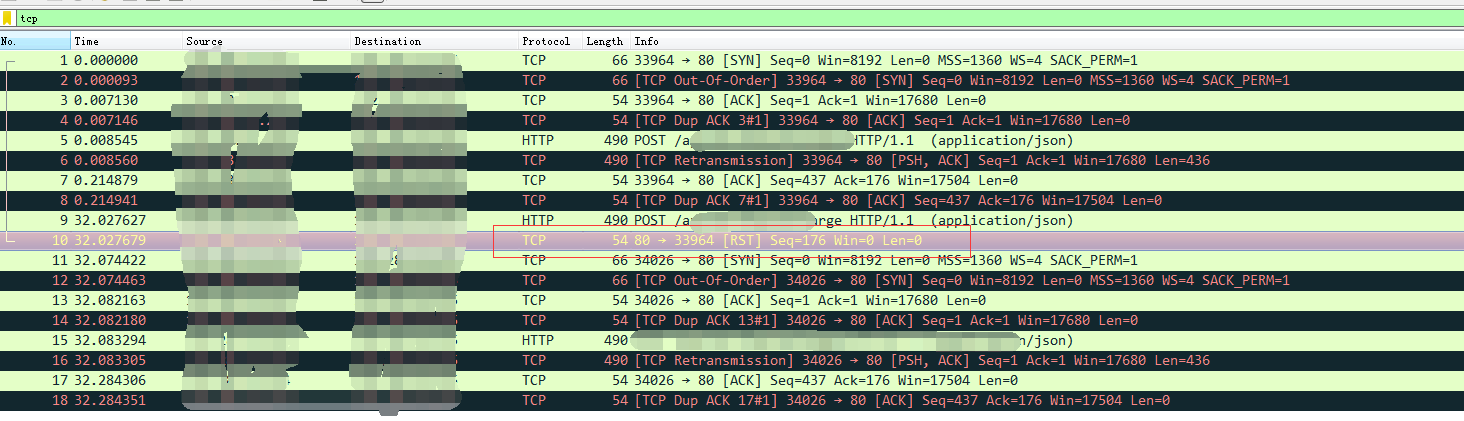
15、发现有个如下设置:
ipvsadm --set 30 6 60

看说明,应该不会影响功能。在抓包的结果中也发现,客户端会重新换个连接,重新发一次请求。
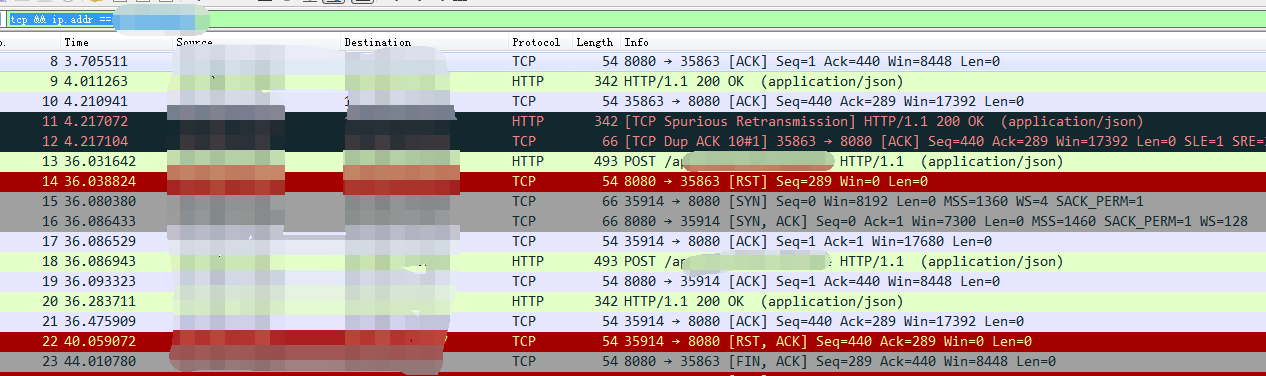
16、思考良久,在测试代码中加入了catch,发现catch后就不会进行重新选取连接重试。导致BUG。
17、查看LVS官方文档,发现三个参数和baidu搜出来的结果不一致。该参数会使TCP连接超时。

18、修改参数为set 60 6 60,(加上参数的目的是为了缓解长连接 的四层tcp耗尽攻击)。问题解决。
至此,问题定位完成。要保证lvs的tcp established超时时间大于nginx的keepalive超时时间。
参考:http://www.austintek.com/LVS/LVS-HOWTO/HOWTO/LVS-HOWTO.ipvsadm.html
https://dongliboyqq.iteye.com/blog/2409122
https://blog.csdn.net/qq_35440040/article/details/83543954