A100 GPU硬件架构
NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成。
GA100 GPU的完整实现包括以下单元:
- 每个完整GPU 8个GPC,8个TPC / GPC,2个SM / TPC,16个SM / GPC,128个SM
- 每个完整GPU 64个FP32 CUDA内核/ SM,8192个FP32 CUDA内核
- 每个完整GPU 4个第三代Tensor核心/ SM,512个第三代Tensor核心
- 6个HBM2堆栈,12个512位内存控制器
GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
- 7个GPC,7个或8个TPC / GPC,2个SM / TPC,最多16个SM / GPC,108个SM
- 每个GPU 64个FP32 CUDA内核/ SM,6912个FP32 CUDA内核
- 每个GPU 4个第三代Tensor内核/ SM,432个第三代Tensor内核
- 5个HBM2堆栈,10个512位内存控制器
显示了具有128个SM的完整GA100 GPU。A100基于GA100,具有108个SM。
GA100具有128个SM的完整GPU。A100 Tensor Core GPU具有108个SM。
A100 SM架构
新的A100 SM大大提高了性能,建立在Volta和Turing SM体系结构中引入的功能的基础上,并增加了许多新功能和增强功能。
A100 SM。Volta和Turing每个SM具有八个Tensor核心,每个Tensor核心每个时钟执行64个FP16 / FP32混合精度融合乘加(FMA)操作。A100 SM包括新的第三代Tensor内核,每个内核每个时钟执行256个FP16 / FP32 FMA操作。A100每个SM有四个Tensor核心,每个时钟总共可提供1024个密集的FP16 / FP32 FMA操作,与Volta和Turing相比,每个SM的计算能力提高了2倍。
SM的主要功能在此简要介绍,并在本文的后面部分进行详细描述:
- 第三代Tensor核心:
- 加速所有数据类型,包括FP16,BF16,TF32,FP64,INT8,INT4和二进制。
- 新的Tensor Core稀疏功能利用深度学习网络中的细粒度结构稀疏性,使标准Tensor Core操作的性能提高了一倍。
- A100中的TF32 Tensor Core操作提供了一条简单的路径来加速DL框架和HPC中的FP32输入/输出数据,其运行速度比V100 FP32 FMA操作快10倍,而具有稀疏性时则快20倍。
- FP16 / FP32混合精度Tensor Core操作为DL提供了空前的处理能力,运行速度比V100 Tensor Core操作快2.5倍,而稀疏性提高到5倍。
- BF16 / FP32混合精度Tensor Core操作以与FP16 / FP32混合精度相同的速率运行。
- FP64 Tensor Core操作为HPC提供了前所未有的双精度处理能力,运行速度是V100 FP64 DFMA操作的2.5倍。
- 具有稀疏性的INT8 Tensor Core操作为DL推理提供了空前的处理能力,运行速度比V100 INT8操作快20倍。
- 192 KB的组合共享内存和L1数据缓存,比V100 SM大1.5倍。
- 新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过L1缓存,并且不需要使用中间寄存器文件(RF)。
- 与新的异步复制指令一起使用的新的基于共享内存的屏障单元(异步屏障)。
- L2缓存管理和驻留控制的新说明。
- CUDA合作小组支持新的经纱级减少指令。
- 进行了许多可编程性改进,以降低软件复杂性。
比较了V100和A100 FP16 Tensor Core操作,还比较了V100 FP32,FP64和INT8标准操作与相应的A100 TF32,FP64和INT8 Tensor Core操作。吞吐量是每个GPU的总和,其中A100使用针对FP16,TF32和INT8的稀疏Tensor Core操作。左上方的图显示了两个V100 FP16 Tensor核心,因为一个V100 SM每个SM分区有两个Tensor核心,而A100 SM一个。
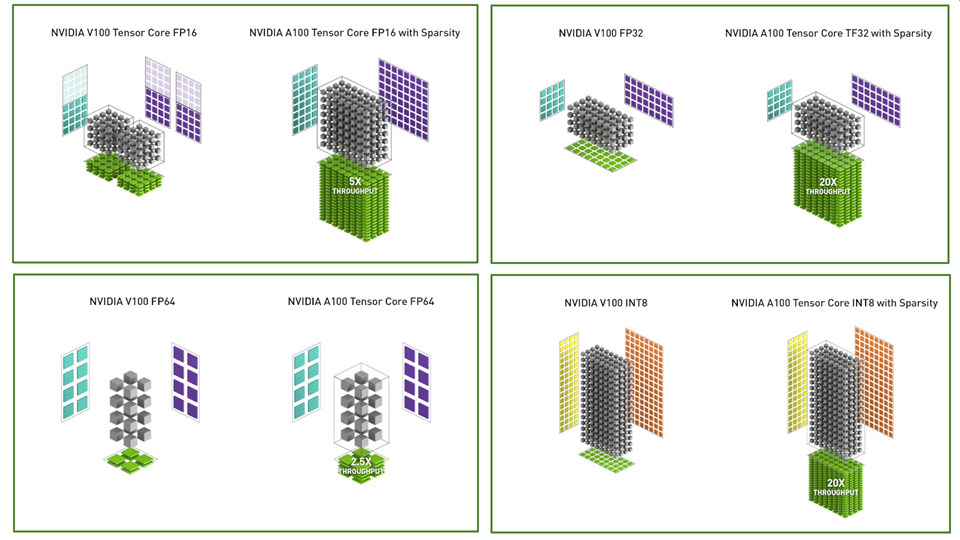
图1.将A100 Tensor Core操作与针对不同数据类型的V100 Tensor Core和标准操作进行比较。
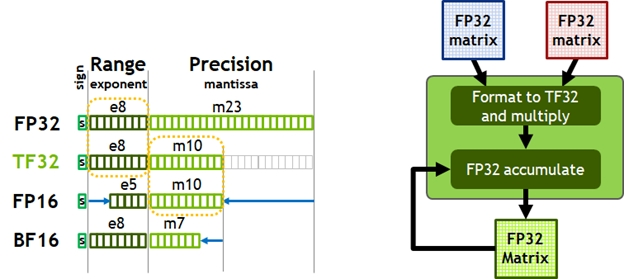
图2. TensorFloat-32(TF32)为FP32的范围提供了FP16的精度(左)。A100使用TF32加速张量数学运算,同时支持FP32输入和输出数据(右),从而可以轻松集成到DL和HPC程序中并自动加速DL框架。
今天,用于AI训练的默认数学是FP32,没有张量核心加速。NVIDIA Ampere架构引入了对TF32的新支持,使AI训练默认情况下可以使用张量内核,而无需用户方面的努力。非张量操作继续使用FP32数据路径,而TF32张量内核读取FP32数据并使用与FP32相同的范围,但内部精度降低,然后再生成标准IEEE FP32输出。TF32包含一个8位指数(与FP32相同),10位尾数(与FP16相同的精度)和1个符号位。
与Volta一样,自动混合精度(AMP)使可以将FP16与混合精度一起用于AI训练,而只需几行代码更改即可。使用AMP,A100的Tensor Core性能比TF32快2倍。
总而言之,用于DL训练的NVIDIA Ampere架构数学的用户选择如下:
- 默认情况下,使用TF32 Tensor Core,不调整用户脚本。与A100上的FP32相比,吞吐量高达8倍,而与V100上的FP32相比,吞吐量高达10倍。
- FP16或BF16混合精度训练应用于最大训练速度。与TF32相比,吞吐量提高了2倍,与A100上的FP32相比,吞吐量提高了16倍,而与V100上的FP32相比,吞吐量提高了20倍。