一、为什么查询速度会慢
通常来说:查询生命周期大致可以按顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划、执行,并返回结果给客户端。
执行可以认为是整个生命周期中最重要的阶段,包括大量的检索数据到存储引擎的调用以及调用后的数据处理(排序和分组等)。
二、慢查询基础:优化数据访问
查询性能低下最基本的原因是访问的数据太多。
① 确认应用程序是否在搜索大量超过需要的数据。
② 确认MySQL服务器层是否在分析大量超过需要的数据行。
1、是否向数据库请求了不需要的数据
① 查询不需要的记录
-- 若页面上只有需要10行数据 返回100行甚至更多是得不偿失的 最简单方法 limit select <cols> from table where col_name = 'col_val' limit 10;
常见的错误认识:MySQL只返回需要的结果集,实际上MySQL是先返回全部结果集再进行运算的,
-- 以前公司分页框架 查询count时 select count(*) from (select <cols> from table where ...) -- 这个时候MySQL会查询出全部<cols>然后进行count处理,查询效率很低,可优化为 select count(*) from table where ...
② 总是取出全部的列+多表关联时返回全部的列
查询中应该拒绝使用 '*'
select * from table where ... -- * 会查询所有的列,平常学习或者解决问题时用*没有问题,但不要在生产应用中使用* -- 特别是多表关联时 会查询出所有的表的所有列 数据量巨大
③ 避免重复查询相同的数据
热点数据,最好使用缓存解决。避免重复不断地查询相同的数据。
2、MySQL是否扫描了额外的记录
对于MySQL,最简单的衡量查询的指标:响应时间、扫描的行数、返回的行数。
① 响应时间
在日常开发中,需要重视响应时间。一般公司都会周期统计响应时间过长的SQL。响应时间=服务时间+排队时间。
② 扫描的行数与返回的行数
分析查询时:查看该查询扫描的行数是非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。理想情况下扫描的行数=返回的行数,但实际操作过程中多表联合查询出一行数据是常态。
-- 注意explain sql 返回列表中的rows属性:扫描的行数
③ 扫描的行数和访问类型
-- explain sql 返回列表中的type属性:访问类型 -- 速度从慢到快 扫描的行数也是从小到大
-- all :全表扫描
-- index :索引扫描
-- range :范围扫描 一般要求最少要达到range
-- ref :非唯一索引扫描
-- eq_ref:唯一索引扫描
-- cons :常熟引用
④ 一般MySQL能够使用三种方式应用where条件(extra : using where),从好到坏依次是:
a 在索引中使用where条件过滤不匹配的记录。这是在MySQL存储引擎层完成的
b 使用索引覆盖(覆盖索引)扫描来返回记录(extra :using index),直接从索引中过滤不需要的记录并返回命中的结果。这是由MySQL服务器层完成的。
c 从数据表中返回数据,然后过滤不满足条件的记录(extra : using where)。这也是在MySQL服务器层完成的。
select actor_id,count(1) from sakila.film_actor group by actor_id; -- 误区:应用where条件不是sql中的where -- 当actor_id是二级索引 对应a -- 当actor_id是主键索引(聚簇)对应b -- 当actor_id不是索引 对应c
⑤ 查询需要扫描大量的数据只返回少量的行,通常有下列技巧优化
a 使用索引覆盖扫描,把所有需要返回的列都放到索引中,存储引擎无须回表获取对应的行就可以返回数据了。
b 改变库表结构。使用单独的汇总表
c 重写这个复杂的查询
三、重构查询的方式
1、一个复杂查询还是多个简单查询
设计查询的一个重要问题:是否需要将一个复杂的查询分为多个简单的查询
传统实现中:总是强调需要数据层完成尽可能多的工作,这样做的逻辑在以前总是认为网络通信、查询解析和优化是一件代价很高的事情。
MySQL:MySQL从设计上让连接和断开连接都很轻量级,在返回一个小的查询结果方面很高效。并且现在网络速度比以前要快的多。
实际设计中一个大查询分解成多个小查询是很有必要的。不要害怕这样做,但也要衡量一下开发成本,这样是不是会减少工作量。例如:查询一个很小的表,完全没必要拆分开来。
2、切分查询
有时候对于一个大查询我们需要“分而治之”,将大查询切分为小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
例如:删除旧数据。定期地清理大量数据时,如果用一个大的语句一次性完成的话,可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
这个时候我们可以将delete语句切分为多个较小的查询,尽可能小的影响MySQL的性能。
delete from messages where created < date_sub(now(),interval 3 month); -- 可分治为下面逻辑 delete from messages where created < date_sub(now(),interval 3 month) limit 10000; -- 然后自定义执行时间,多执行几次,例如一个小时一次,一天就是24w数据
3、分解关联查询
很多高性能的应用都会对关联查询进行分解。例如:
select * from tag join tag_post on tag_post.tage_id=tag.id join post on tag_host.post_id=post.id where tag.tag='mysql'; -- 可以分解为 select * from tag where tag='mysql'; select * from tag_post where tag_id= 1234; select * from post where post.id in (123,456,567,9098,8904);
这样重构的优点:
① 让缓存的效率更高,缓存多张表的数据。
② 将查询分解后,执行单个查询可以减少锁的竞争
③ 在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
④ 查询本身效率也可能有所提升。例如控制in()中id顺序查询比随机的关联要更高效。
⑤ 可以减少冗余记录的查询。
⑥ 更进一步,这样做相当于在应用中实现了hash关联,而不是使用MySQL的嵌套循环关联。
四、查询执行的基础
MySQL查询过程:
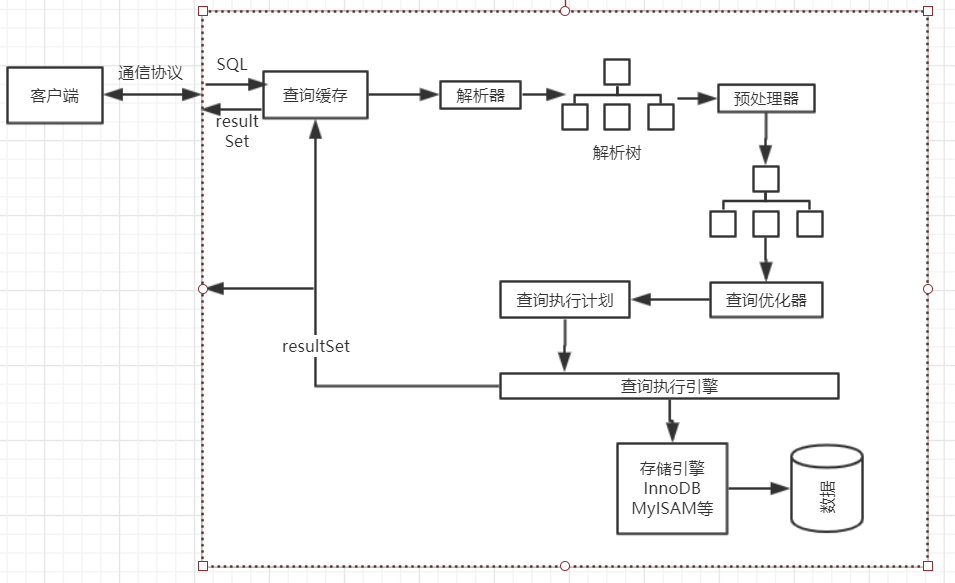
1、客户端/服务器通信协议
① “半双工”通信协议:让MySQL通信简单快速,但有一个明显的限制无法进行流量的控制。
② 对于一个MySQL连接或者说一个线程,任何时候都有一个状态,这个状态表示MySQL当前正在做什么。
-- 由于“半双工”通信协议。了解这些状态含义,可以很快了解处理进度。 -- Sleep :线程正在等待客户端发送新的请求 -- Query :线程正在执行查询或者正在将结果发送给客户端 -- Locked :在MySQL服务器层,该线程正在等待表锁。 -- Analyzing and statistics :线程正在收集存储引擎的统计信息,并生成查询执行计划 -- Coping to tmp table [on disk] :线程正在执行查询,并且将其结果集都复制到一个临时表中,这种状态一般要么是在做group by要么order by 或者是 union操作。 -- Sorting result :线程正在对结果集进行排序。 -- Sending data :这表示多种情况:线程可能在多个状态之间传送数据;生成结果集;在向客户端返回数据
2、查询缓存
在解析一个查询语句之前,如果查询缓存时打开的,MySQL会优先检查这个查询是否命中查询缓存中的数据。
① 这个检查是通过对一个大小写敏感的哈希查找实现的,查询和缓存查询即时一个字节不同,也视作为未命中
② 查询命中缓存后,MySQL还会检查用户权限。
3、查询优化处理
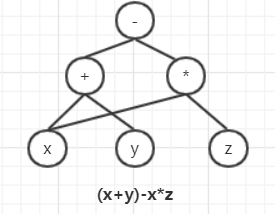
① 语法解析器和预处理:MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”,并且对解析树进行语法规则检查。
一个简单的语法树模型,MySQL中肯定会更复杂
② 查询优化器 :当语法树被认为是合法的,优化器会从很多种执行方式,找到最好的执行计划。
select sql_no_cache count(*) from sakila.film_actor; -- 5462 show status like 'last_query_cost' -- 1040.599000 -- 结果显示MySQL优化器认为大概需要做1040个数据页的随机查找才能完成上面的查询。
一下原因可能会导致优化器选择错误的执行计划:
a 统计信息不准确。
b 执行计划中的成本估算不等同于实际执行的成本
c MySQL的最优可能和你想的最优不一样。时间短 != 执行成本
d MySQL不考虑其他并发执行的查询
e MySQL不是任何时候都是基于成本的优化。又是也会基于一些固定的规则。
f MySQL不会考虑不受其控制的操作的成本
g 优化器有时无法估算所有可能的执行计划,而错过实际最优执行计划
MySQL能够处理的优化类型:
重新定义关联表的顺序:数据表关联并不总是按照查询中指定顺序进行的。
将外连接转化成内连接:并不是所有outer join语句都必须以外连接方式执行。例如where条件、库表结构可能使外连接等价于一个内连接。
使用等价变换规则:MySQL可以使用一些等价变化来简化规范表达式。(5 = 5 and a > 5)改写为 a > 5
优化count()min()和max():索引和列是否可为空通常可以帮助MySQL优化这类表达式。
预估并转化为常数表达式:当MySQL检测到一个表达式可以转化为常数的时候。就会一直把该表达式作为常数进行优化处理
覆盖索引扫描:当索引中的列包含所有查询中需要使用的列的时候,MySQL就可以使用索引返回需要的数据。
子查询优化:MySQL在某些情况下可以将子查询转换一种效率更高的形式。
提前终止查询:在发现以满足查询需求的时候,MySQL总是能够立刻终止查询。limit
等值传播:如果两个列的值通过等式关联,那么MySQL能够把其中一个列的where条件传到另一列上。
列表IN()的比较:在有些数据库系统中in()等同于or,但MySQL不是,in()列表中数据先排序,然后二分查找方式确定列表中值是否满足条件。or=O(n)则in=O(logn)
③ 数据和索引的统计信息
在服务层有查询优化器,却没有保存数据和索引的统计信息。统计信息由存储引擎实现。
④ MySQL如何执行关联查询
MySQL对任何关联都执行嵌套循环关联操作,MySQL先在一个表中循环取出单条数据,然后嵌套循环到下一个表中寻找匹配的行,依次直至执行完毕
⑤ 执行计划
与很多其他关系数据库不同,MySQL并不会生成查询字节码来执行查询,生成查询的一棵指令树。
⑥ 关联查询优化器
MySQL优化器最重要的一部分就是关联查询优化,它决定了多个表关联时的顺序。
⑦ 排序优化
无论如何排序都是一个成本很高的操作,所以从性能角度考虑,应尽可能避免排序或者尽可能避免对大量数据进行排序。
4、查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划完成整个查询。
5、MySQL查询优化器的局限性
① 关联子查询:MySQL的子查询实现得非常糟糕。最糟糕的一类查询时where条件中包含in()的子查询语句。
select * from sakila.film where film_id in ( select film_id from sakila.film_actor where actor_id = 1); -- 我们通常以为会这样执行 select * from sakila.film where film_id in (1,23,25,106...); -- 实际并非如此 select * from sakila.film where exists ( select * from sakila.film_actor where actor_id = 1 and film_actor.film_id = film.film_id); -- 很容易重写这个查询 select film.* from sakila.film inner join sakila.film_actor using(film_id) where actor_id = 1;
② UNION的限制
③ 索引合并优化
④ 等值传递
⑤ 并行执行
⑥ 哈希关联
⑦ 松散索引扫描
⑧ 最大值和最小值优化
⑨ 在同一个表上查询和更新
五、优化特定类型的查询
一、优化count()查询
count()是一个特殊的函数,有两种非常不同的作用:
统计某个列值的数量:在count()的括号中指定了列或者列的表达式,则统计的就是这个表达式有值(不为NULL)的结果数。
统计行数:count(*)中*并不会像我们猜想的那样扩展成所有的列count(*) = count(1),在统计行数时最好使用count(*),这样写意义清晰,性能也很好。
select count(*) from world.city where id > 5; -- 反转一下 select (select count(*) from worldl.city) - count(*) from world.city where id <= 5; select sum(if(color = 'blue',1,0)) as blue,sum(if(color = 'red',1,0)) as red from items; select count(color = 'blue' or null) as blue,count(color = 'red' or null) as red from items;
二、优化关联查询
① 确保on 或者using子句中的列上索引。
② 确保任何group by和order by中表达式只涉及到一个表中的列,这样MySQL才有可能使用索引来优化这个过程
③ 当升级MySQL的时候需要注意:关联语法、运算符优先级等其他可能会发生变化的地方。
三、优化子查询
① 尽可能的使用关联查询替代子查询。
四、优化group by和distinct
① 索引优化是最有效的方法。
② 无法使用索引时,group by使用两种策略来完成:使用临时表或者文件排序来做分组。
select actor.first_name, actor.last_name,count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by actor.first_name, actor.last_name; -- 采用查找表的表示列分组的效率会比其他列更高 select actor.first_name, actor.last_name,count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id;
五、优化limit分页
当偏移量很大时,例如limit 10000,20 查询出10020条记录后只返回20条。代价非常高。
可以使用索引覆盖扫描,而不是查询所有的列。
select film_id,description from sakila.film order by title limit 50,5; -- 延迟关联将大大提高查询效率 select film.film_id,film.description from sakila.film inner join ( select film_id from sakila.film order by title limit 50,5 ) as lim using(film_id); -- 或者根据返回film_id值 select film_id,description from sakila.film where film_id > ? order by title limit 5;
六、优化sql_calc_found_rows
分页的时候,一个更好的技巧是
① 具体页数换成下一页按钮,每页显示20条记录,那么可以每次查询21条记录,仅显示20条,第21条数据用作下一页按钮的判断
② 先获取并缓存较多的数据,例如缓存1000条数据,每次分页从缓存中取数据,如果结果集大于1000,则可以页面上设计一个额外的“找到的结果多于1000条”
七、优化union查询
MySQL总是通过创建并填充临时表的方式来执行union查询。因此很多优化策略在union查询中都没法很好地使用。
除非确实需要服务器消除重复的行,否则一定要使用union all。
八、静态查询分析
九、用户自定义变量
参考《高性能MySQL》