WeTest 导读
一、背景
流控作为容灾体系中必不可少的一环,在请求量超过系统容量的时候,通过拒绝超量请求的方式,防止服务接口的雪崩和系统挂掉。
目前部门只具备单机流控的能力,随着业务的增长和系统复杂度的增加,单机流控越来越不能满足需要,升级流控能力日趋重要。
(一)流控分类
升级流控之前,先简单了解不同流控方式的优缺点:
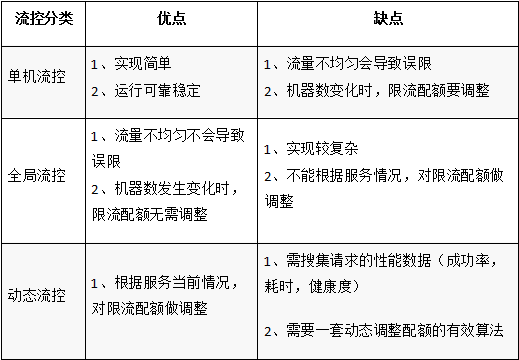
对比可知,全局流控能能弥补单机流控的缺点,而动态流控又是在全局流控的基础上做更精细化的流控。
(二)现有方案分析
目前全局流控方案主要需要解决两个实现问题:
1、全局计数器使用何种存储
全局计数器存储可以使用redis,也可以使用ckv。
分布式流控很关键一点是将流控服务做成原子化。而做流控需要记录两个信息,计数和计时。比如全局流控阈值设置了5w/s的值,计数器记录了当前的请求数(计数),在达到1s时计数器需失效或清零(计时)。
计数和计时要保证原子操作,目前已知的方式有:
1)使用加锁的方式,比如ckv的cas计数,或者redis+lua技术,但在并发量大的时候,加锁的性能比较无法保证;
2)使用incr的方式,由于目前redis和ckv的incr都没支持修改值的同时设置过期时间,要满足要求(计数和计时同时原子操作),需改造redis或ckv,目前已知有团队改造redis支持原子修改值同时设置过期时间的案例。
2、 如何上报请求
一般统计的方式分两种:
1) 请求全量上报,这样要求存储的访问能力足够强大,优点是流控实时性得到保证;
2) 请求定时批量上报,这样存储的访问压力较小,资源消耗也更少,缺点是流控可能不实时;
一般还需要每台机器部署agent来完成上报和流控判断,业务模块与agent之间要实现通讯。
大体的逻辑结构如下:
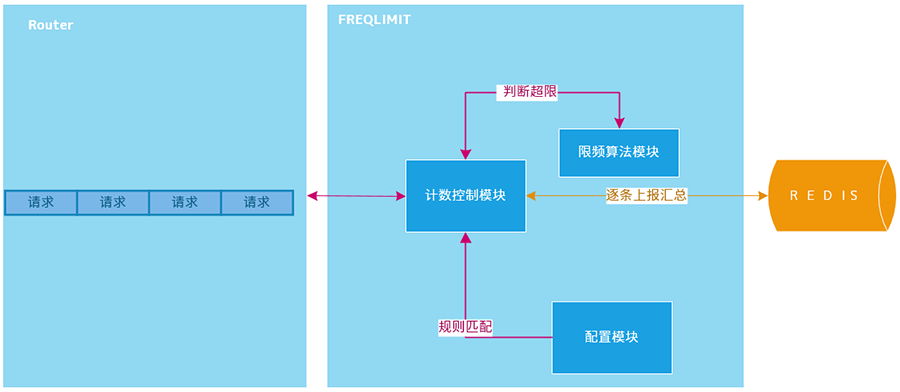
注:图片来自文章《MSDK全局流控介绍》
实现难点:
1)将流控服务做成原子化,目前无论使用redis还是ckv,加锁方式并发下无法保证性能,原生的incr方式要解决过期时间的问题,需要的技术门槛和开发成本都比较高;
2)从上报统计方式看,全量上报对请求量巨大的业务部门来说不大可行,定时批量上报又无法保证实时流控;
3)接入全局流控每台机器都需要部署agent,agent能否正常工作影响全局流控的使用,同时部署及运维的成本不低;
二、方案设计
面对目前困难,我们提出这样的疑问:
有没有一套简单可行的方案,能解决上述问题的同时,保证开发成本较低,部署简单,运行稳定,而且流控准确的呢?
(一)轻量级流控方案
方案要点:
1、计数器的key能“计时“
首先选择使用ckv作为计数器存储,相比redis开发会更熟悉,同时维护也更容易,当然该方案也可以选择redis作为计数器存储。
既然使用ckv的cas用作计数在高并发下有性能瓶颈,那么只能使用incr的方式,同时要解决计时的问题。
方案没有对incr增加过期时间的方式,而是将时间信息写入key,把一天按时间划分(比如1s划分一个key)为若干个key作为计数器。这样每个key既能使用incr方式计数,同时也有”计时“的能力,当超过划分时间(比如1s后),就顺移到下一个key上做计数。
优势:方案用简单的方式将全局流控服务做成原子化(计数和计时原子化),开发门槛低。
2、请求统计用拉取的方式替换上报
对于请求的统计方式,一般全量上报不可行,所有业务的请求量至少1:1上报到ckv,ckv的容量和是个问题,单key也容易成为热点。定时或者定量批量上报,都无法保证实时流控,特别是请求量大的时候,流控延迟的问题会被放大。
方案抛开原有的上报思维定式,引入配额拉取的概念,替换一般统计上报的方式,取而代之的是每个key初始化时写入流控阈值,每个业务机器并非上报请求量,而是访问ckv拉取配额到本地保存,本地配额消耗完毕再次拉取,类似余库存扣减。
优势:方案减少ckv的访问量,同时保证流控的准确性。
3、部署不需要agent
已有的流控方案都需要每台业务机器部署agent,完成上报请求和流控判断的功能。这样做机器都要部署agent,同时agent的正常使用也要纳入维护。
为了做更轻量的方案,我们考虑agent的必要性,分析发现,agent要完成的功能比较简单,主要功能托管到业务流控api。
这样的做法会让业务在调用流控校验时有额外的开销,开销主要是拉取配额访问ckv的时间消耗,正常是<1ms,只要每次拉取配额的值设置合理,分摊到每个请求的耗时就少的可以忽略。
比如拉取配额设置10,即正常10个请求要拉取一次配额,这时流控api会请求一次ckv拉取配额,这个业务请求耗时增加约1ms。
优势:方案不采用agent的方式,部署维护更简单。
4、全局及单机流控同时启用
考虑全局流控不可用的情况,比如ckv挂掉,能否保证业务不受影响且流控可用?
方案对容灾做了充分的考虑,主要解决方式是全局及单机流控同时启用,即基于ckv的全局流控和基于单机共享内存的单机流控都同时工作。
全局流控失效(ckv挂掉或连续超时导致拉取配额失败),流控api判断出这种情况后,暂时停止使用全局流控,而单机流控依然可以正常工作,流控api定期去探查(比如30s)全局流控是否恢复可用,再启动全局流控。
优势:方案有很好的容灾能力,容灾方式简单有效。
5、解决ckv性能瓶颈,流控性能达百万/s
由于使用ckv的incr以及配额拉取的实现方式,全局流控接入服务请求的能力得到成本增长。
目前方案单独申请了一块ckv,容量为6G,使用incr的方式,压测性能达到9w+/s。
对业务空接口(Appplatform框架)做流控压测,使用30台v6虚拟机,单机50进程,压测性能达到50w+/s。
单接口50w/s的请求的服务接入,同样也能满足多接口总体服务请求量50w+/s的全局流控需求。
上述的压测瓶颈主要是Appplatform框架的性能原因,由于拉取配额值是根据流控阈值设定(一般>10),50w+的请求量只有不到5w的ckv访问量,ckv没到瓶颈。
优势:方案使用同等的资源(单独一块6G的ckv),能满足业务的请求量更高,性能达百万/s。
6、支持扩容和动态流控升级
支持平行扩展流控能力,一套全局流控部署能满足流控的服务请求量是达百万/s,更大的服务请求量需要部署多套全局流控。
支持升级到动态流控能力,ckv写入的流控阈值是通过定时管理器完成,目前业务已经做了健康度上报,定时管理器只需要对接健康度数据,分析接口当前请求情况,动态调整流控阈值即可达到动态流控能力。
优势:方案整体简单轻量,扩容和升级都很容易。
接下来详细介绍一下具体方案的实现。
(二)流控逻辑架构
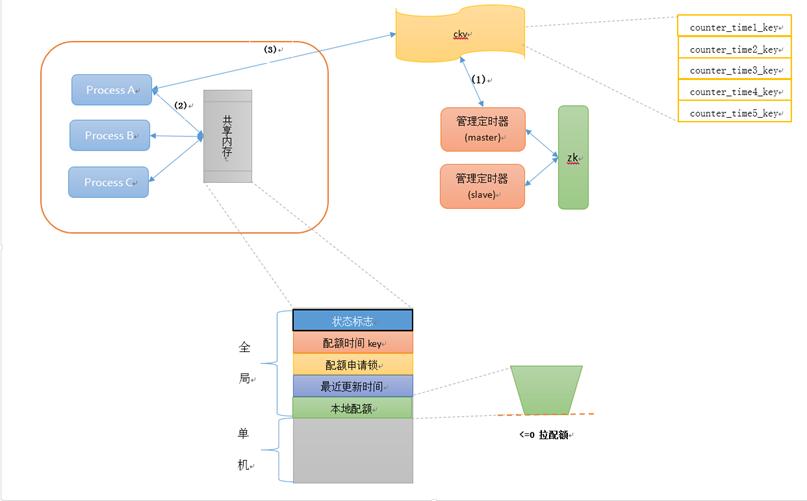
方案涉及几个功能简单、清晰的角色:
1、管理定时器:
根据配置,将频率限制任务的配额值,写入多个带时间信息的key。比如频率限制任务1配了阈值为5000/s的全局流控,那么就以每一秒生成一个kv为例:
key为task1_20170617000000、task1_20170617000001、task1_20170617000002等
value为5000
2、共享内存:
保存每一个任务流控相关的本机信息,包括流控状态、本地配额、配额锁等。
3、流控API:
业务通过流控api,请求先扣减本地配额(原子操作),如果配额<=0,就从ckv拉取配额到共享内存中,如果没配额拉取,就做说明流控生效。
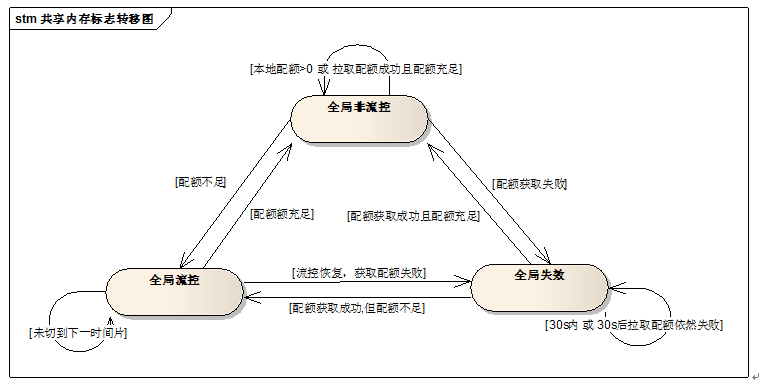
(三)流控状态机
全局流控过程可以抽象出三个主要状态:
1、全局非流控状态指的是全局流控可用的情况下,但还没触发限流,业务请求可以正常通过;
2、全局流控状态指的是业务请求触发限流,请求不能通过;
3、全局失效状态指的是全局流控由于异常不可用,比如ckv访问超时或挂掉,业务请求可以正常通过;
(四)流控关键流程详解
围绕三个流控状态的跳转,抽象出整个全局流控的核心关键流程:
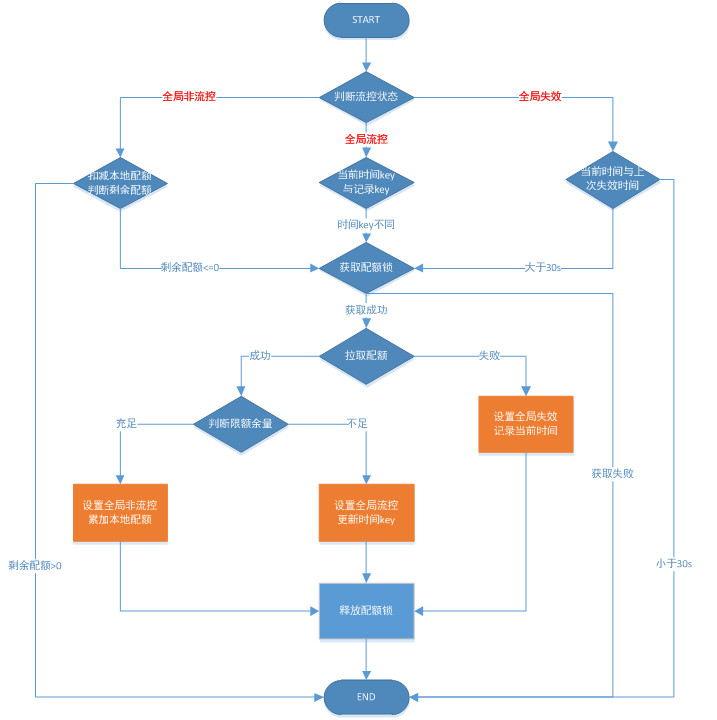
1、当状态为全局非流控,首先会先扣减本地配额,本地配额<=0时,就走拉取配额流程;
2、当状态为全局流控,本地配额<=0时,先判断key是否发生变化,作用是同一个时间间隔内配额已经消耗完,减少无效的拉取;
3、当状态为全局失效,会判断时间是否已经超过一个设定值,在失效时间内不会尝试拉取配额,作用是减少无效的拉取;
4、 拉取配额先获取原子锁,作用是当业务进程并发拉取时,只有获取锁成功的进程,才能拉取赔额额;
整个流程考虑了所有会发生的情况,围绕三个状态的跳转,正常及异常流程处理都很好的统一到一个流程里。
比如发送ckv不可用的故障,通过拉取配额失败的动作,很好的从正常的全局非流控状态切换到全局失效状态,又通过定时拉配额,去探查故障是否消除,如果消除就回复到全局非流控的正常状态。
三、方案关键问题
(一)机器时间不一致
由于以时间间隔做key,划分不同的时间片并写入流控配额,当机器拉取配额面临个机器时间是否一致的问题。
据了解,时间同步是通过ntp服务来完成,精度在1~50ms之间,一般情况是<10ms。
目前的时间间隔都是1s以上,ntp服务的精度已经满足。
换句话说只要保证ntp服务正常运行,全局流控的单个时间片的计数是准确的。
如果ntp服务没正运行,导致机器时间不一致,会导致同一时刻应该访问同一key的机器,访问了多个key,则会造成计数不准确。
由于ntp服务目前处理方式是通过监控流控任务一段时间内的key的变化情况,及时发现机器时间不一致的情况。具体做法是如果发现某一时刻超过两个kv的配额值发生变化,可以确认机器同一时刻访问key的分布超过合理的范围,有时间有不一致的情况。
(二)计数原子化
为了保证并发情况下配计数的准确性,会使用原子操作的方式处理计数,无需加锁。
1、全局配额是用ckv的incr方式,保证配额拉取扣减的准确;
2、本地配额累加或扣减,对共享内存使用gcc提供的__sync_add_and_fetch的原子操作方式;
(三)配额锁发生死锁
拉取配额使用了加锁,锁的方式是对对共享内存使用gcc提供__sync_bool_compare_and_swap的原子操作方式。
极端情况下,获取锁的进程core掉,就会导致锁无法释放,其他进程需要拉取配额时也获取不了锁。死锁不会影响业务请求正常通过,但由于无法拉取配额,会导致全局流控无法使用。
处理这种情况目前的方式是,判断加锁的时长是否超过合理值 ,具体做法是加锁记录当前时间,正常释放清空这个时间值,获取不了锁的进程判断加锁的时长,大于设定值(1min),说明有死锁情况,主动释放锁。
(四)配额拉取值设定
配额拉取的值的设置起到一个很关键的一步,影响流控的准确性,拉取的效率以及ckv访问压力。
拉取配额值合理,既减少ckv访问压力,减轻业务Api额外的拉取耗时(一般<1ms),同时也能保证流控准确。
拉取配额值不合理,设置过大会造成机器剩余的配额浪费,需要配额的机器可能没配额,导致产生错误流控。设置过小会导致本地配额消耗完(本地配额值<0),配额拉取滞后,造成流控生效延后,拉取次数过多,ckv访问压力大,业务api拉取效率低。
配额值的设置是:单机阈值与拉取值的比值为50。比如全局流控阈值 10000/s,机器数20,平均单机流控阈500/s,配额值设定为10。
目前是通过压测观察的经验值得来,拉取值设置是否合理,还有待后续观察和分析。
四、方案运维
(一)部署及扩展
部署:
1、管理定时器的部署,只需单独部署到脚本机上;
2、业务模块添加流控api,已经接入原来单机流控的业务,无需改动业务逻辑代码,只需要替换旧的静态库和依赖的的头文件即可(待给出详细接入);
扩展:
方案支持平行扩展,一套全局流控部署能满足流控的服务请求量是50w+/s,更大的服务请求量需要部署多套全局流控。平行扩展一套主要的变更包括:申请新的ckv,使用新的一块共享内存以及新的流控任务配置。
(二)监控报警
1、对流控任务做了可视化监控
主要监控及跟踪各流控任务的基本使用能够信息,以及当前和历史流量情况
2、机器时间不一致的监控及上报
主要监控流控任务一段时间内的key的变化情况,及时发现机器是否时间不一致
(三) 容灾/故障处理
1、管理定时器接入zk主从切换组件,在单点挂掉的情况下可以切到另外一台机器上,保证timer的可用性。
2、当ckv连接超时或无法访问时,对应的流控状态会变成全局失效,过一段时间会自动重新拉起。所以出现ckv不可用的情况,只需要恢复ckv,接入全局流控的服务会自动恢复可用状态。
五、方案升级
(一)完善监控和告警
目前流控监控只是对流控任务使用情况做了简单的展示,流控的历史情况等其他必要的信息还没能查询及展示。
还有待补充的监控有机器时间不一致监控,监控发现的问题需要告警,以便于人工及时介入。
有待规划的监控和告警后续再补充。
(二)流控方案升级
流控升级下一步是从全局流控升级到动态流控,所需健康度数据已经上报,而接入的方式目前可以直接在管理定时器上面增加配额调整的能力,这个扩展很方便。重点应该是怎么去根据上报的健康数据分析并实现动调整当前配额值。
配额调整大致的思路如下:
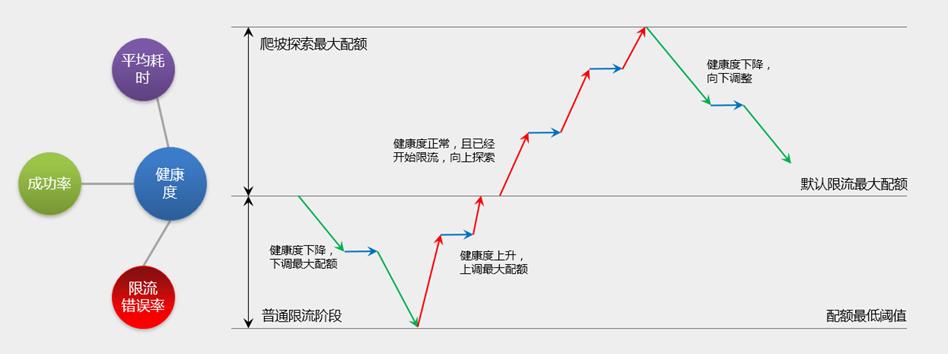
注:图片来自于理财通的《接入层限流介绍》
WeTest压测大师运用了沉淀十多年的内部实践经验总结,通过基于真实业务场景和用户行为进行压力测试,帮助游戏开发者发现服务器端的性能瓶颈,进行针对性的性能调优,降低服务器采购和维护成本,提高用户留存和转化率。
功能目前免费对外开放中,点击链接:http://wetest.qq.com/gaps 即可体验!
如果对使用当中有任何疑问,欢迎联系腾讯WeTest企业qq:800024531