最近我们广告的曝光量有点少,于是开始查找原因,曝光量少就是广告没有下发,广告没有下发无非就是接口超时和缓存没数据
首先,我们的前端机针对评论流的广告位有六台,在查某条广告的缓存时发现,其中一台可以获取到,其余的几台都获取不到mc的
数据,但是我们连到这台没有缓存数据的机器上发现,可以正常的get或者set数据。那就开始看mc服务器的参数,于是发现正常的
机器参数如下 : echo -e "stats
quit
" | /usr/bin/nc 127.0.0.1 11512
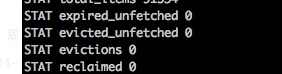
中的evictions为0,其他出现缓存数据没有的机器这个值是:
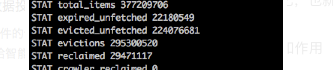
对 evictions的值达到了接近3亿,也就是mc内存不够,启动了lru策略,值就是LRU释放的对象数目
其中详细解释一下其实的参数和作用
pid:mc服务器的进程id
uptime:服务器已经运行的秒数(可以知道mc运行多久了)
time:服务器的当前时间戳
version:mc版本
pointer_size:当前操作系统指针大小,反映了操作系统的位数,64意味着mc服务器是64位的
rusage-user:进程的累积用户时间
rusage_system:进程的累积系统时间
curr_connections:当前打开着的连接数
total_connections:当服务器启动以后曾经打开过的连接数
connection_structures:服务器分配的连接构造数
cmd_get:get命令总请求次数
cmd_set:set命令总请求次数
cmd_flush:flush_all命令总请求次数
get_hit:总命中次数,重要,缓存最重要的参数就是缓存命中率,以get_hits/(git_hits + get_misses)表示
get_misses:总未命中次数
auth_cmds:认证命令的处理次数
auth_errors:认证失败的处理次数
bytes_read:总读取的字节数
bytes_written:总发送的字节数
limit_maxbytes:分配的内存总大小(字节)
accepting_conns:服务器是否达到过最大连接
threads:当前线程数
bytes:当前存储占用的字节数
curr_items:当前存储的数据总数
total_items:启动以来存储的数据总数
evictions:LRU释放的对象数目(如果还有足够内存,那么这个值应该是0或者不再增长) 为了给新的数据项目释放空间,从缓存移除的缓存对象的数目,比如超过缓存大小时根据LRU算法移除的对象以及过期的对象。
以上就是需要知道的使用stats命令查看mc的缓存相关参数
因为我们看到经常丢失的mc的服务器evictions参数都是大于1,说明内存不足
在看一下运维给memcache是实例分配的大小是:

一个G的内存,-m表示所以slab class 可用内存的上限,以MB为单位,现在1024MB也就是分配了1G的内存给MC
现在得出的结果就是内存不够导致的mc使用lru策略删除最近最少使用的key的value值。
那为什么最近刚写入的数据就被清空了呢,按照策略难道不应该是很久之前的数据被清空么?
借鉴网上的一个设计场景:
1、部署一个memcached测试环境,分配比较小的内存
2、设置一条永远不过期的数据到memcached中,然后再get一次,这条数据后续应该存在LRU队尾
3、每隔1s向memcached set并get一次 10000条数据,过期时间设置为3s
4、一段时间后,stats命令现实evictions=1
按照之前我的理解,2步的数据永远不会被踢,因为有足够过期的数据空间可以给新来的数据用,lru淘汰算法应该跳过没过期的数据,但结果证实是错误的,以上业务
的服务器发生被踢的现象是由于保存了大量存活期短的keyvalue,且key是不重复的,另外又有一业务保存了小量不过期的数据,因此导致不过期的数据惨遭被挤到队列踢出
这是网上找到的一段测试用例。
针对上面那个场景总结以下几条解决方式:
- 过期的数据如果没被显式调用get,则也要占用空间。
- 过期的不要和不过期的数据存在一起,否则不过期的可能被踢。
- 从节约内存的角度考虑,即使数据会过期,也不要轻易使用随机字符串作为key,尽量使用定值如uid,这样占用空间的大小相对固定。
- 估算空间大小时候请用slab size计算,不要按value长度去计算。
- 不要把cache当作更快的key value store来用, cache不是storage。
而我遇到的就是因为内存不够而mc使用LRU策略来解决内存不够,因此导致的新写的key也被踢出去了。因为存储已经满了,那旧数据即使没有到过期时间,也会被移除。
下面分别说一下mc的工作原理和工作流程以及优化建议:
mc工作原理:
基本概念:
slab:它是在启动mc实例的时候预处理好的,每个slab对应一个chunk size
page:可以理解为内存页,大小固定事1M,slab会在存储请求时向系统申请page,并将page按照chunk size进行切割
chunk:保存用户数据的最小单位,用户数据item(包括key,value)最终会保存到chunk内。chunk规格时固定的,如果用户数据放进来后还有剩余则剩余部分不做其他用途
mc工作流程:
mc实例启动,根据-f和-n来进行预分配slab,然后每个slab分配一个page。当用户发来存储请求时(key、value)mc会计算key+value的大小,看看属于那个slab,确定slab后看里面
的释放有空闲chunk放key+value。如果不够就再向系统申请一个page,申请后将page按本slab的chunk size进行切割,然后分配一个存放用户数据
注:
1、chunk是在page里面划分的,而page时固定1M,所以chunk最大不能超过1M
2、chunk实际占用内存要加48b,因为chunk数据结构本身需要占用48B
3、如果用户数据大于1M,mc会将其切割,放到多个chunk内
4、已分配出去的page不能回收
优化建议:
1)-n 参数的设置,注意将此参数设置为1024可以整除的数(还要考虑48B的差值),否则余下来的部分就浪费了。
2)不要存储超过1m的数据。因为要拆成多个chunk,计算和时间成本都成倍增加。
3)善用stats命令查看memcached状态。
4)消灭eviction(被删除的数据)。
造成eviction是因为内存不够,有三个思路:
(1)在CPU有余力的情况下开启压缩(PHP扩展);
(2)增加内存;
(3)调整-f参数,减少内存浪费。
5)调整业务代码,提高命中率。
6)缓存小数据。省带宽,省网络I/O时间,省内存。
7)根据业务特点,为数据尺寸区间小的业务分配专用的memcached实例。这样可以调小 -f 参数,使数据集中存在少数几个slab上,内存浪费较少。
启动时最重要的参数:
-m 整个memcached最大内存
-f chunk大小增长因子
-n chunk最小分配空间
-C 禁用CAS
-vvv 打印详细信息
我们通过计算可以看出,每个slab的chunk size大小都是上一个大小的1.25倍,1.25就是memcached启动时制定的-f的值,所以,要根据不同的业务场景调整,既要尽可能少的减少内存浪费,又要存得下我们业务中的数据,再举个例子,加入我们的业务很BT,大小都是200kb,我们该怎么做?那当然是要保证我们申请的chunk大小都是200kb了,虽然memcached并不支持这么做。假如创建了38个slabs,最后数据全都落到了第20-25个slab中,那0-19和26-38的内存就被浪费了,这只是能评估出来的,还有一种情况,加入我们的chunk大小是500kb,数据才200kb,因为每个chunk都只能存储一个,所以一个chunk就会有500kb-200kb的空间浪费,如果有一千万个chunk要存,那将会浪费多少空间?所以,在使用memcached之前,先要评估你的数据,根据它去调整-f因子。
memcached删除机制
memcached通过slab机制不会释放已分配的内存,记录超时或删除后不会释放内存,而是重复利用
mc优先使用超时的记录的内存空间
下面说一下LRU策略底层
当缓存没有内存可以分配给新的元素的时候,memcached会从LRU链表的尾部开始淘汰一个ITEM,不管这个ITEM是否还在有效期都将会面临淘汰。LRU链表插入缓存ITEM的时候有先后顺序,所以淘汰一个ITEM也是从尾部进行 也就是先淘汰最早的ITEM。
这就解释了 我们刚写入的数据,在陆续写入更多后,最先被写入的就被淘汰了,因为内存不够,而LRU策略也是从队尾开始淘汰。
最后总结:很久之前在学习memcache时,也知道LRU策略,因为在面试的时候会问哈哈,但是只是按照书面的理解了一下,在实战中没有遇到,就算遇到之前也是有运维。
但是你这样永远不知道咋回事。所以后来的我每次遇到这些问题,就会在屁股后面跟着
运维,一边时配合运维查问题,确保不是业务逻辑带来的,另一方面也是在学习遇到这种问题看看别人是怎么解决的,然后再网上查一下为什么会这样,最后总结整理一下知识点,加深印象。感谢身边优秀的同学们。