教学大纲:


教学内容 大型互联网三大问题-高并发,高可用,大数据量 第一天内容如下: 1:什么是高并发? 2:为什么要解决高并发 3:画图分析: 1) 多用户访问单台App服务器及数据库时,性能分析,瓶颈在哪里? 2) 提出解决办法:加App服务器 3) 随之出现更多问题 问题1:用户访问IP多了 怎么解决? 问题2:数据库出现瓶颈 怎么办? 4) 问题1 采用负载均衡解决 5) 问题2: • 采用缓存 • 采用读写分离+主从复制解决,需要多台数据库,画图说明解决方案(系统级别解决) • 更好的解决方案是分库分表,库表散列(应用级别解决) 目前 :高并发网站架构设计方案 • 网页HTML 静态化(需要CMS项目支持) • 图片服务器分离(常用解决方案) • 数据库集群和库表散列(终级解决方案) • 缓存(常用解决方案) • 镜像(下载较多) • 负载均衡(终级解决方案) 4:介绍什么是负载均衡? 5:负载均衡原理—画图说明 –总结它的功能 6:负载均衡的种类 7:本节课采用LVS负载均衡演示? 8:为什么采用LVS? 1)此时要先讲解网络七层相关东西。之后说明LVS工作在四层上,而Nginx,apache工作在七层上 2) 四层与七层对服务器CPU,内存等性能的消耗进行说明 9:搭建负载均衡环境准备—4台虚拟服务器,4个IP, 10:需要安装的软件 11:开始搭建---演示效果 12:讲解keepalived配置参数参数 13:讲解linux lo接口VIP绑定脚本参数说明 14:什么是高可用? 15: 搭建备用负载均衡---演示主机挂掉,备机自动接管工作,主机恢复,重新接管工作,备机进入等待 第二天内容如下: 16:什么是大数据量? 17:为什么不演示读写分离?采用读写分离只能解决数据库并发问题,但随着每天数据量的增加,如果使用的是Mysql,mysql的数据量达到千万级时,即使使用读写分离,mysql查询数据的速度也慢的要命,此时,很多公司会更换oracle来解决这个问题,但oracle是按CPU收费的。采用读写分离必定是多台数据库,多台oracle是一笔不小的费用,费用还是其次,随着每天数据量的增加,oracle也有顶不住的一天 18:oracle顶不住怎么办? 答案1:hadoop集群 答案2:分库分表,库表散列 目前形势简介:大多公司都会走上hadoop集群这条路上来,因为分库分表,库表散列是需要在项目初期时,公司高管就要有懂这方面人才存在,但现实当中,这样的人很少,包括淘宝,刚开始也不是分库分表,库表散列,而后来采用了oracle,再后来成立了自己的研究院,才解决了分库分表,库表散列的设计,但麻烦的事情也随之而来,就是老数据怎么迁移进新库中,还要平滑的迁移,平滑指的是网站正常运转,随时都会有新数据进来,怎么将时刻动态变化的数据迁移到新库中来,难度非常大。采用的办法是:全量+增量 运维人员写三个脚本,分别是导数据脚本,read log脚本,对比数据脚本 采用分库分表,库表散列 好处: (一) 可使用免费的mysql集群即可,可节省出orcal集群的大笔费用 (二) 当数据量增多到当前数据库集群不能容纳时,也支持动态添加新库来应对 (三) 可使用非常廉价服务器来安装mysql 什么是分库? 什么是分表? 什么是库表散列? 本节课演示案例:演示的内容来自于阿里研究院,已经运行三年以上,较为成熟 支持数据库容灾、备份 实现级别? 应用级别实现 采用什么架构实现? Spring + mybatis + mysql 实现 搭建环境准备 开发工具:myeclipse ,jdk 演示效果 详细讲解如何配置 (见意不对外给源码) 资料篇:
企业的划分:
选择成熟企业还是创业企业
小公司看老板——老板靠谱,愿意分享,空间无限。
中公司看制度——制度合理,空间可见,成长阶段。
大公司看文化——文化适合,空间有限,平台价值。
面对创业型、发展型、成熟型的企业,该如何选择?
创业型企业意味着更艰苦的条件和更大的风险,但是也意味着更大的机会,只是这种机会比较渺茫而已。
因为它的成活率很低,成活后能发展为伟大企业的几率就更低,而且你要伴随它很长时间才能知道你的选择是否正确。
这些都是你要掂量的,这也是很多学生不愿去那些美名曰“创新工作”的企业的原因。
发展型企业已经没有成活的风险,最艰苦的日子已过,也积累了相当的市场和组织基础,
只是与成熟型企业相比,制度、福利待遇或者技能培训体系有可能还不足够完善。
如果你能参与其中的建设和完善工作,未来在这个组织中,你必将有自己的位置。
成熟型企业自有它的优势,比如已经形成的企业文化,老中青相结合的组织队伍,成熟的晋升体制,相当规模的市场基础等。
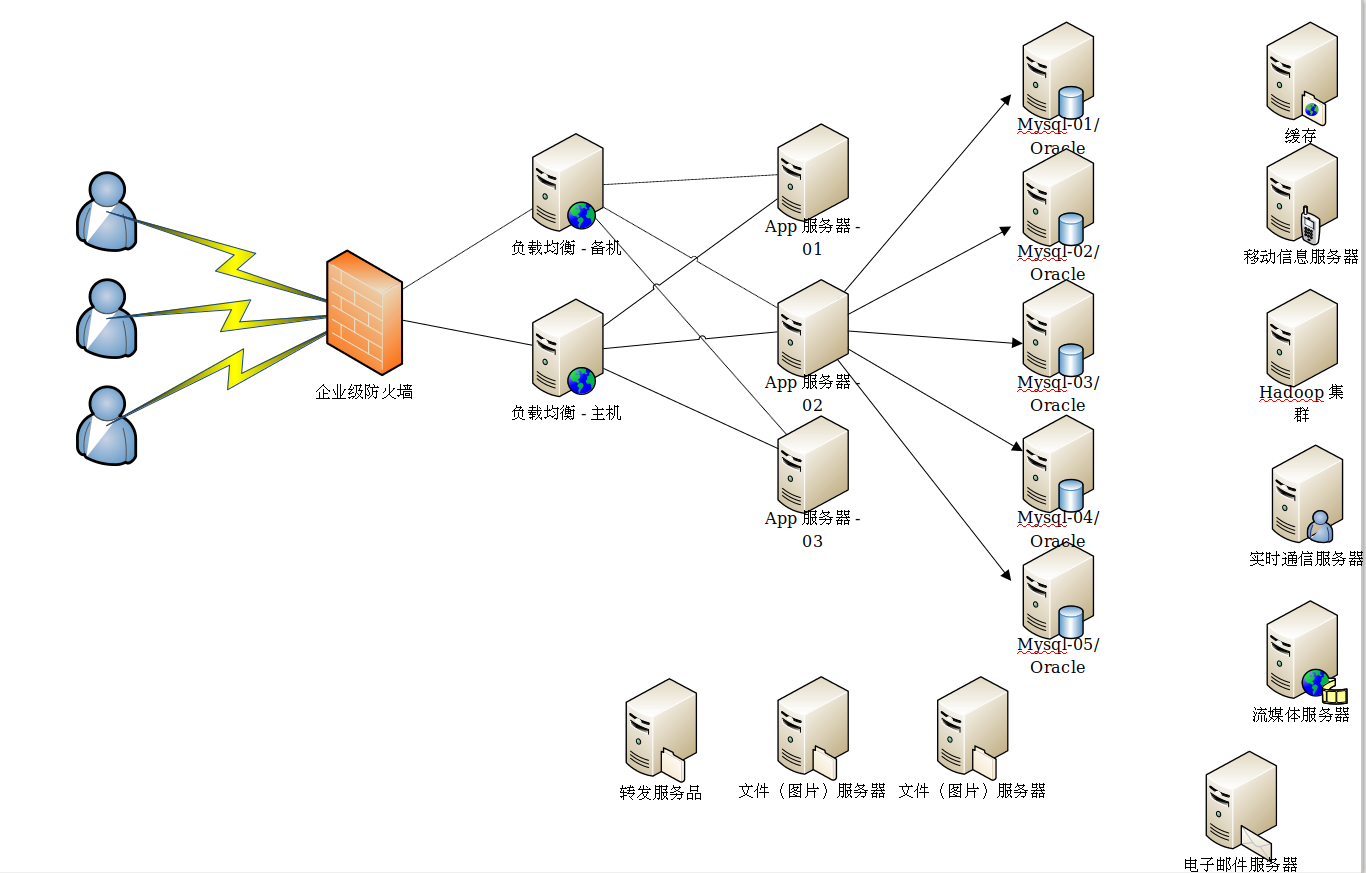
企业的架构图:
高并发:
什么是高并发呢?
多个进程或线程同时(或着说在同一段时间内)访问同一资源会产生并发问题。
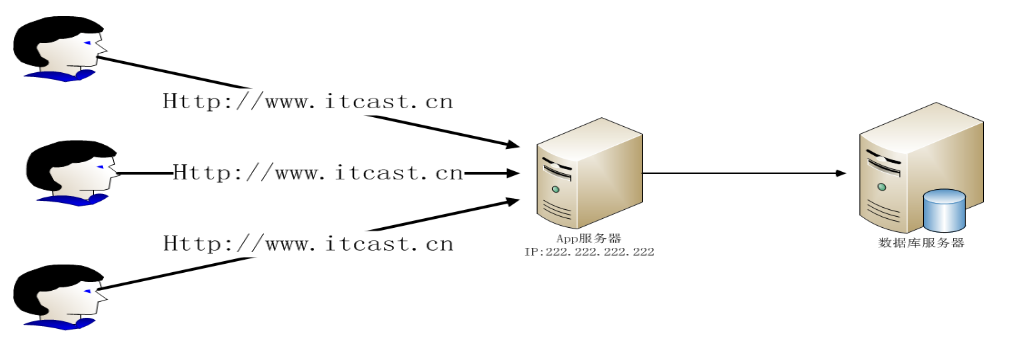
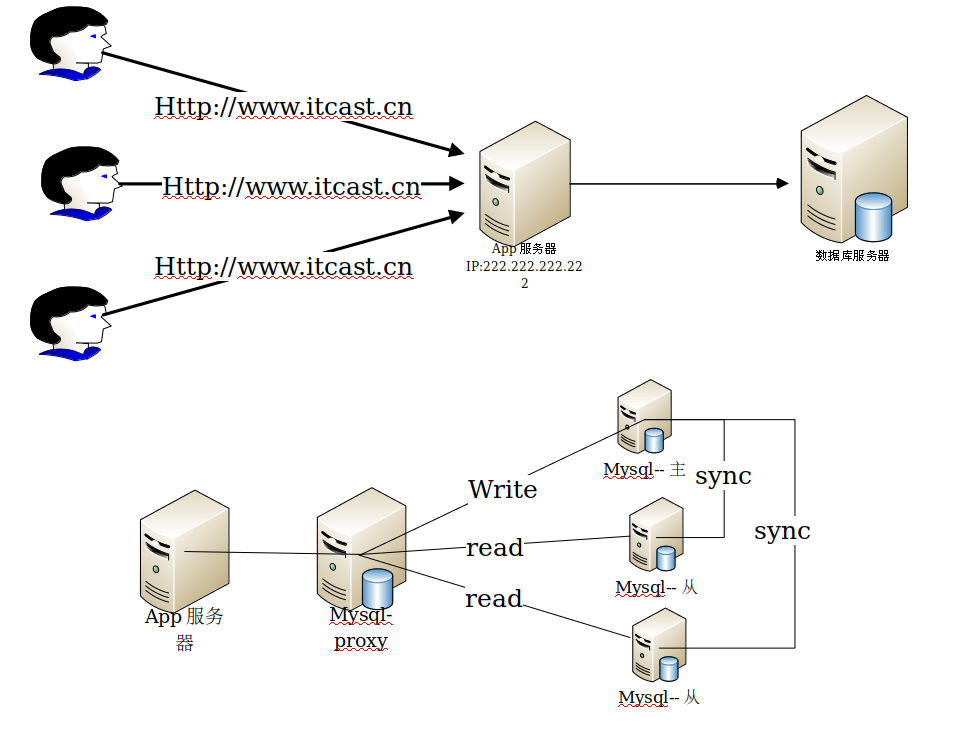
大量用户直接访问一台Tomcat服务器:
初期解决方案:
系统或服务器级别的解决方案
1:增大服务器的CPU。
2:增加内存条。
3:增加硬盘个数,对硬盘做Raid5。
4:换掉免费的Tomcat,使用商用weblogic(美国Oracle公司出品的)
5:增加到二块网卡。
6:聘请系统架构师优化Linux内核
甚至花高价直接购买高性能服务器
随着业务的不断增加,服务器性能很快又到达瓶颈
应用级别的解决方案
1:网页HTML 静态化(需要CMS项目支持)
2:图片服务器分离(常用解决方案)
3:缓存(常用解决方案)
4:镜像(下载较多)
能否增加服务器数量?

随之出现更多问题
问题1:用户访问IP多了 怎么解决?
问题2:数据库出现瓶颈 怎么办?
DNS:
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。DNS协议运行在UDP协议之上,使用端口号53。
画图说明
1:经过DNS解析
2:不经过DNS解析
解决IP多--DNS
DNS服务器可以解决IP多了的问题
http://www.itcast.cn : 192.168.1.100
192.168.1.101
192.168.1.102
……更多
缺点:虽然循环复用 DNS 是一个普遍使用的在 Web 服务器上负载平衡的解决方案,但是,该方式有它自身的缺陷。循环复用 DNS将传入的 IP 请求映射到定义的一系列循环形式的服务器。一旦发生服务器故障,循环复用 DNS 继续把请求发送到这个故障服务器,一直到把该服务器从 DNS 中移走为止。这样许多用户必须等到 DNS 连接超时以后才能成功地访问目标网站
用户访问IP多了 怎么解决
采用负载均衡技术(终级解决方案)
由于目前现有网络的各个核心部分随着业务量的提高,访问量和数据流量的快速增长,其处理能力和计算强度也相应地增大,使得单一的服务器设备根本无法承担。在此情况下,如果扔掉现有设备去做大量的硬件升级,这样将造成现有资源的浪费,而且如果再面临下一次业务量的提升时,这又将导致再一次硬件升级的高额成本投入,甚至性能再卓越的设备也不能满足当前业务量增长的需求。
针对此情况而衍生出来的一种廉价有效透明的方法以扩展现有网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性的技术就是负载均衡(Load Balance)。
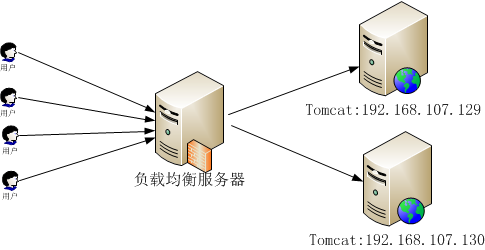
负载在均衡工作原理:
总结:负载均衡功能
1.转发请求
2:故障移除
3:恢复添加
负载均衡种类
1)一种是通过硬件来进行解决,常见的硬件有NetScaler、F5、Radware和Array等商用的负载均衡器,但是它们是比较昂贵的
2)一种是通过软件来进行解决的,常见的软件有LVS、Nginx、apache等,它们是基于Linux系统并且开源的负载均衡策略
负载均衡--软件解决
1:apache
2:nginx
3: lvs
Apache + JK
Apache是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件
JK是apache提供的一款为解决大量请求而分流处理的开源插件
Nginx
Nginx(发音同 engine x)是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。由俄罗斯的程序设计师Igor Sysoev(伊戈尔·西索夫)所开发,供俄国大型的入口网站及搜索引擎Rambler(漫步者)(俄文:Рамблер)使用。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:新浪、网易、 腾讯等。
优点:
1:可运行linux,并有 Windows 移植版。
2:在高连接并发的情况下,Nginx是Apache服务器不错的替代品Nginx在美国是做虚拟主机生意的老板们经常选择的软件平台之一。能够支持高达 50,000 个并发连接数的响应
LVS:
LVS的英文全称是Linux Virtual Server,即Linux虚拟服务器。它是我们国家的章文嵩博士的一个开源项目。在linux内核2.6中,它已经成为内核的一部分,在此之前的内核版本则需要重新编译内核。
网络七层
什么是网络七层?
可画图说明。

理解网络七层之后,有助于同学们理解LVS的优势,对比nginx 与 lvs 区别
为什么选择LVS? 优势
1、抗负载能力强,因为lvs工作方式的逻辑是非常之简单,而且工作在网络4层仅做请求分发之用,没有流量,所以在效率上基本不需要太过考虑。在我手里的 lvs,仅仅出过一次问题:在并发最高的一小段时间内均衡器出现丢包现象,据分析为网络问题,即网卡或linux2.4内核的承载能力已到上限,内存和 cpu方面基本无消耗。
2、配置性低,这通常是一大劣势,但同时也是一大优势,因为没有太多可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率。
3、工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体是非常稳定的。
4、无流量,上面已经有所提及了。lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5、基本上能支持所有应用,因为lvs工作在4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等等。
LVS 对比 Nginx
负载度
2:网络的依赖
3:稳定度
4:服务器性能要求
效率最高的负载均衡技术
调度器的实现技术中,IP负载均衡技术是效率最高的,IP虚拟服务器软件(IPVS)是在linux内核中实现的。
IPVS软件实现了三种IP负载均衡技术
1:VS/NAT
2: VS/TUN
3: VS/DR
VS/NAT
Virtual Server via Network Address Translation(VS/NAT)
通过网络地址转换,调度器重写请求报文的目标地址,根据预设的调度算法,将请求分派给后端真实服务器;真实服务器的响应报文通过调度器时,报文源地址被重写再返回给客户,完成整个负载调度过程。
但通常在流量比较大的情况下会造成调度器的瓶颈。因为服务数据的返回必须通过调度器出去。
可以画个图来说明一下!
VS/TUN
Virtual Server via IP Tunneling(VS/TUN)
采用NAT技术时,由于请求和响应报文都必须经过调度器地址重写,当客户请求越来越多时,调度器的处理能力将成为瓶颈。为了解决这个问题,调度器 把请求报文通过IP隧道转发至真实服务器,而真实服务器将响应直接返回给客户,所以调度器只处理请求报文。由于一般网络服务应答比请求报文大许多,采用 VS/TUN技术后,集群系统的最大吞吐量可以提高10倍。
但是目前支持TUN 只有Linux系统
VS/DR
Virtual Server via Direct Routing(VS/DR)
VS/DR通过改写请求报文的MAC地址,将请求发送到真实服务器,而真实服务器将响应直接返回给客户。同VS/TUN技术一样,VS/DR技术 可极大地提高集群系统的伸缩性。这种方法没有IP隧道的开销,对集群中的真实服务器也没有必须支持IP隧道协议的要求,但是要求调度器与真实服务器都有一 块网卡连在同一物理网段上。也就是说,在这种结构中,数据从外部到内部真实服务器的访问会通过调度器进来,但是真实服务器对其的应答不是通过调度器出去。 即在大多数情况下,真实服务器可以通过各自的网关或者专用的网关对数据进行外发,从而降低调度器负载。
LVS中提供了八种不同的调度算法
1:轮叫调度(Round-Robin Scheduling)
2: 加权轮叫调度(Weighted Round-Robin Scheduling)
3:最小连接调度(Least-Connection Scheduling)
4:加权最小连接调度(Weighted Least-Connection Scheduling)
5:基于局部性的最少链接(Locality-Based Least Connections Scheduling)
6:带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
7:目标地址散列调度(Destination Hashing Scheduling)
8:源地址散列调度(Source Hashing Scheduling)
9:最短预期延时调度(Shortest Expected Delay Scheduling)
10:不排队调度(Never Queue Scheduling)
对应: rr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq
加权轮叫调度(WeightedRound-RobinScheduling)
调度器通过"加权轮叫"调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
加权最小连接调度(WeightedLeast-ConnectionScheduling)
在集群系统中的服务器性能差异较大的情况下,调度器采用"加权最少链接"调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值
搭建负载均衡的环境---准备
系统:Centos6 (三台)
负载均衡:LVS + keepalived
服务器1:Http
服务器2:Http
ip配置
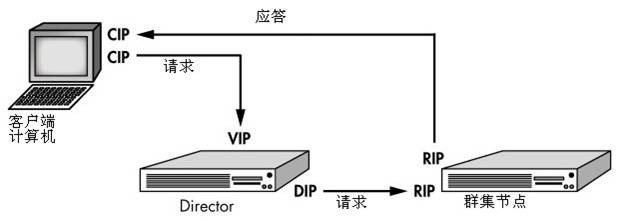
1、VIP(virtual ip):用来提供virtual server服务的ip地址。分别绑定在Director一个物理网卡上(对外接收请求包)和RS的回环设备上(回环设备需要绑定两个ip,一个是127.0.0.1,另一个就是vip)。
2、DIP(director ip):与vip绑定在一个物理网卡上,用来转发请求包到RS的RIP对应的mac上,此设备可以通过arp请求获取RIP对应的mac地址。
3、RIP(real server ip):绑定在RS上的一个物理网卡上,用来接收从Directory转发过来的请求包。
一:realserver服务器IP绑定配置
在两台realserver服务器安装并配置(本课演示用Linux自带Http服务进行演示),建立测试网页,先使用实际IP进行访问测试,能正常访问后,进行如下操作:
二:realserver服务器IP绑定配置
在前面的文章中介绍DR模式时提到:负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。
但实际上客户端访问时,IP都是指向的负载均衡器的ip(也就是LVS的VIP),如何能让真是服务器处理IP头为VIP的请求,这就需要做下面的操作,将VIP绑定到真实服务器的lo网口(回环),为了防止IP广播产生IP冲突,还需关闭IP广播。
三:编辑开机启动脚本
[root@web1 ~]# vim /etc/init.d/realserver
问题:
没有realserver?
touch一个realserver即可
脚本在《开机启动脚本》文档中
四:设置脚本开机启动并立即启动
[root@web1 ~]# chkconfig realserver on
[root@web1 ~]# service realserver start
如果启动正确
RealServer Start OK
五:开始搭建负载均衡
1:安装 ipvsadm keepalived
命令:yum –y install ipvsadm keepalived
2:配置 keepalived
命令:vi /etc/keepalived/keepalived.conf
六:keepalived.conf
global_defs { # notification_email { # admin@toxingwang.com # } # notification_email_from master@toxingwang.com # smtp_server smtp.exmail.qq.com # smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.107.127 } } virtual_server 192.168.107.127 80 { delay_loop 6 lb_algo wrr lb_kind DR nat_mask 255.255.255.0 persistence_timeout 0 protocol TCP real_server 192.168.107.129 80 { weight 3 TCP_CHECK { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } real_server 192.168.107.130 80 { weight 3 TCP_CHECK { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } }
七:启动keepalived服务
[root@lvs1 ~]# service keepalived start
注:由于keepalived配置文件有语法错误也能启动,因此看到启动了lvs服务,不代表配置文件没有错误,如果遇到lvs不能正常转发,及时跟踪日志进行处理。
八:日志跟踪方法:
1、开两个ssh窗口连接到lvs服务器,第一个窗口运行如下命令:
[root@lvs1 ~]# tail -f /var/log/message
2、第二个窗口重新启动keepalived服务,同时观察窗口1中日志的变化,然后根据日志提示解决即可。
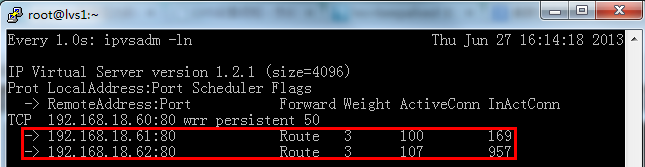
九:测试LVS
在lvs master服务器上运行如下命令:
[root@lvs1 ~]# watch -n 1 ipvsadm -ln
在多台客户端通过浏览器访问VIP或域名(域名需解析到VIP),看能否获取到正确的页面,且同时观察上述窗口的变化。
lvs集群内部网络问题的解决
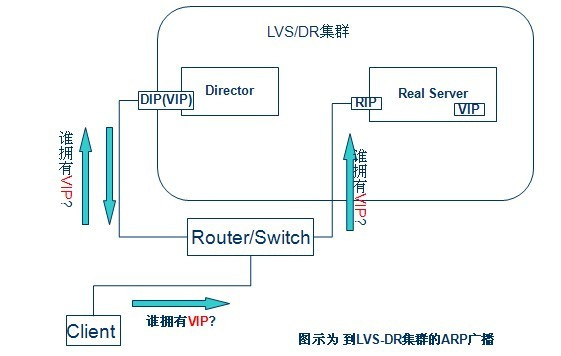
A、vip解决冲突的方式:由于vip分别配置在director和RS上,如果不加限制会导致ip地址冲突,所以需要在RS的回环设备上禁用arp响应( echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore ),同时也要调整发送arp请求时使用哪个ip作为源地址(echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce)。即集群的路由器/交换机在使用arp询问谁有vip地址时,只有director作出响应,RS并不回应此arp请求,所以集群的路由器/交换机并不知道RS上也有VIP地址的配置。这个过程图示如下:
realserver脚本说明
#!/bin/bash #chkconfig: 2345 79 20 #description:realserver SNS_VIP=192.168.1.98 #定义VIP变量 . /etc/rc.d/init.d/functions #导脚本库 case "$1" in #case语句 $1传递给该shell脚本的第一个参数 start) ifconfig lo:0 $SNS_VIP netmask 255.255.255.255 broadcast $SNS_VIP #设置Lo:0 VIP netmask 及广播 /sbin/route add -host $SNS_VIP dev lo:0 ##route del 增加本地路由 echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce sysctl -p >/dev/null 2>&1 # -p <file> (default /etc/sysctl.conf) 将标准信息输入设备空文件 echo "RealServer Start OK" ;; stop) ifconfig lo:0 down route del $SNS_VIP >/dev/null 2>&1 #route del 删除本地路由 echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce echo "RealServer Stoped" ;; *) echo "Usage: $0 {start|stop}" #$0 是脚本本身的名字 exit 1 #表示进程正常退出 esac #case结束 exit 0 #表示进程非正常退出
两个参数说明:
arp_ignore:用来配置对arp请求的响应模式,每种模式表示的含义如下:
0 :(默认值)回应任何网络接口上对任何本地IP地址的arp查询请求
1 :只回答目标IP地址是来访网络接口本地IP地址的ARP查询请求
2 :只回答目标IP地址是来访网络接口本地IP地址的ARP查询请求,且来访IP必须在该网络接口的子网段内
3 :不回应该网络接口的arp请求,而只对设置的唯一和连接地址做出回应
4-7 :保留未使用
8 :不回应所有(本地地址)的arp查询
arp_announce:用来配置发送arp请求的模式,每种模式含义如下:
0:(默认值)使用任何interface上的任何本地地址,在此模式下无论使用哪个接口发送arp请求,arp请求包里的源ip地址在arp层不会做修改,也就是arp请求包里的源ip地址为即将发送ip数据包的源ip地址。
1:避免这个interface的不在目标子网里的本地地址,当ARP请求包里的目的IP地址是需要经过路由达到的时候很有用,此时会检查来访IP是否为所有接口上的子网段内ip之一,如果该来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理。
2:对arp请求包使用最适当的本地IP地址,在此模式下将忽略即将发送IP数据包的源地址,并尝试选择与能与该目的地址通信的本地地址,首先是选择与目标IP地址属于同一子网的接口IP地址。如果没有合适的地址被发现,将选择当前的发送网络接口或其他的有可能接受到该ARP回应的网络接口来进行发送,当内网的机器要发送一个到外部的ip包,那么它就会请求路由器的Mac地址,发送一个arp请求,这个arp请求里面包括了自己的ip地址和Mac地址,而linux默认是使用即将发送ip包的源ip地址作为arp里面的源ip地址(0模式),而不是使用发送设备上面的,如果设置arp_announce为2,则使用发送设备上的ip地址。
keepalived.conf 参数说明
# notification_email { ##下面几行均为全局通知配置,可以实现出现问题后报警,但功能有限,因此注释掉,并采用Nagios监视lvs运行情况 # admin@toxingwang.com # } # notification_email_from master@toxingwang.com # smtp_server smtp.exmail.qq.com # smtp_connect_timeout 30 router_id LVS_DEVEL ##设置lvs的id,在一个网络内应该是唯一的 } vrrp_instance VI_1 { ##设置vrrp组,唯一且同一LVS服务器组要相同 state MASTER ##备份LVS服务器设置为BACKUP interface eth0 # #设置对外服务的接口 virtual_router_id 51 ##设置虚拟路由标识 priority 100 #设置优先级,数值越大,优先级越高,backup设置为99,这样就能实现当master宕机后自动将backup变为master,而当原master恢复正常时,则现在的master再次变为backup。 advert_int 1 ##设置同步时间间隔 authentication { ##设置验证类型和密码,master和buckup一定要设置一样 auth_type PASS auth_pass 1111 } virtual_ipaddress { ##设置VIP,可以多个,每个占一行 192.168.18.60 } } virtual_server 192.168.18.60 80 { delay_loop 6 ##健康检查时间间隔,单位s lb_algo wrr ##负载均衡调度算法设置为加权轮叫 lb_kind DR ##负载均衡转发规则 nat_mask 255.255.255.0 ##网络掩码,DR模式要保障真实服务器和lvs在同一网段 persistence_timeout 50 ##会话保持时间,单位s protocol TCP ##协议 real_server 192.168.18.61 80 { ##真实服务器配置,80表示端口 weight 3 ##权重 TCP_CHECK { ##服务器检测方式设置 keepalived的健康检查方式 有:HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK connect_timeout 5 ##连接超时时间 nb_get_retry 3 ##失败重试次数 delay_before_retry 3 ##失败重试的间隔时间 connect_port 80 ##连接的后端端口 } } real_server 192.168.18.62 80 { weight 3 TCP_CHECK { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } }
遗留问题
如果负载均衡服务器宕机了,怎么办?
演示备机操作
1:Master挂了,无备机,演示
2:Master挂了,备机自动接管
3:Master好了,备机进入待机状态
问题2:数据库出现瓶颈 怎么办?
以Mysql为例:
1:对Mysql进行优化(重点讲解)
2:缓存,主流缓存Memcached,redis…
3: mysql读写分离 + 主从复制
4:Oracle
5:Oracle读写分离 + 主从复制
6:Oracle Partition 分区
7:Oracle RAC集群(终级解决方案)
此方案:非常贵,即使是淘宝,京东这样的大公司,也是很难受的。
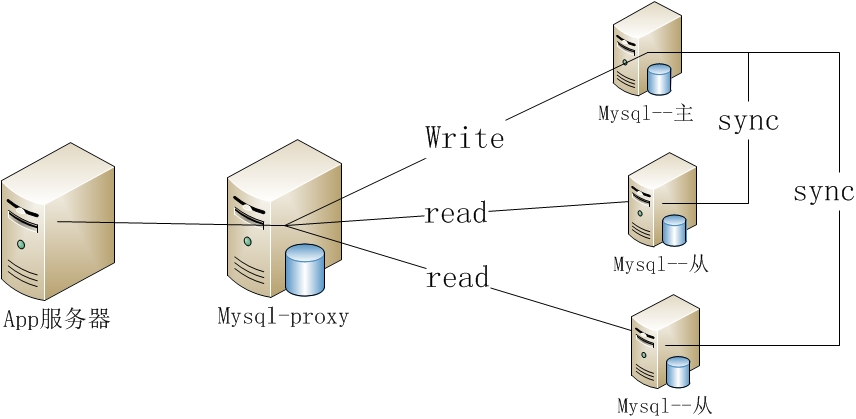
Mysql主从复制与读写分离
MySQL主从复制(Master-Slave)与读写分离(MySQL-Proxy)实践
Mysql作为目前世界上使用最广泛的免费数据库,相信所有从事系统运维的工程师都一定接触过。但在实际的生产环境中,由单台Mysql作为独立的数据库是完全不能满足实际需求的,无论是在安全性,高可用性以及高并发等各个方面。
因此,一般来说都是通过 主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Proxy)来提升数据库的并发负载能力 这样的方案来进行部署与实施的。
开始搭建主从复制
服务器二台:
分别安装二台Mysql数据库
1:安装命令
yum –y install mysql-server
2:配置登陆用户的密码
演示此操作
3:配置允许第三方机器访问本机Mysql
演示此操作
场景描述
主数据库服务器:192.168.1.112,MySQL已经安装,并且无应用数据。
从数据库服务器:192.168.1.115,MySQL已经安装,并且无应用数据。
Mysql配置
1:vi /etc/my.cnf
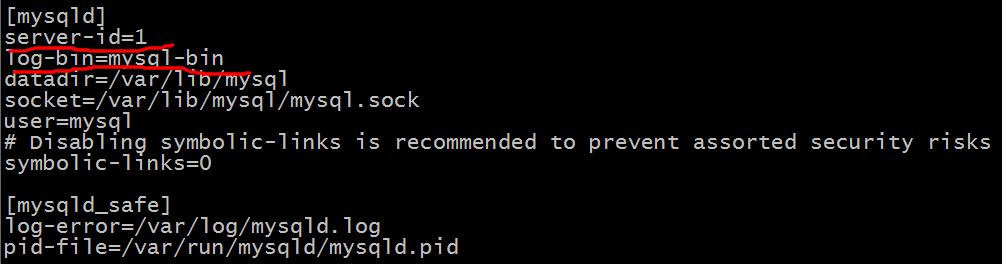
接下来确认slave和master的上的server_id是否正确。可以分别在slave和master上运行 SHOW VARIABLES LIKE 'server_id'; 来查看server_id是否和你配置的一样。
启动Mysql服务器
1:分别重新启动master,slaver的二台mysql服务
2:登陆
3:输入
Mysql> SHOW VARIABLES LIKE 'server_id';
来查看server_id是否和你配置的一样。
4:master输入
Mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000005 | 261 | | |
+------------------+----------+--------------+------------------+
记录下 FILE 及 Position 的值,在后面进行从服务器操作的时候需要用到。
5:配置从服务器
change master to
master_host='192.168.0.104',
master_user='rep1',
master_password='root',
master_log_file='log.000002',
master_log_pos=364;
正确执行后启动Slave同步进程
6:启动slave
mysql> start slave;
7:查看slave状态
mysql> show slave statusG
其中Slave_IO_Running 与 Slave_SQL_Running 的值都必须为YES,才表明状态正常。
测试主从复制
1:先确定主,从库上没有任何自定义表
2:主服务器上的操作
在主服务器上创建数据库itcast_db
mysql> create database itcast_db;
在主服务器上创建表itcast_tb
mysql> create table itcast_tb(id int(3),name char(10));
在主服务器上的表itcast_tb中插入记录
mysql> insert into itcast_tb values (01, "itcast01");
3:从服务器上查看是否已经同步?
失败原因:
1:server_id 配置的一样或是配置的没有更新到Mysql数据中来
2:防火墙拦截了3306端口
3:用户与密码不正确
4:Mysql不允许其它机器访问
开始搭建读写分离
服务器三台:
1:安装二台Mysql数据库(已经安装)
2:安装mysql-proxy,mysql
场景描述:
数据库Master主服务器:192.168.1.112
数据库Slave从服务器: 192.168.1.115
MySQL-Proxy调度服务器:192.168.1.101
以下操作,均是在192.168.1.101即MySQL-Proxy调度服务器上进行的。
Mysql-proxy
1:Mysql安装
2:检查系统所需软件包
通过 rpm -qa | grep name 的方式验证以下软件包是否已全部安装。
gcc* gcc-c++* autoconf* automake* zlib* libxml* ncurses-devel* libmcrypt* libtool* flex* pkgconfig*
libevent* glib* readline*
若缺少相关的软件包,可通过yum -y install方式在线安装,或直接从系统安装光盘中找到并通过rpm -ivh方式安装。
3:编译安装lua
MySQL-Proxy的读写分离主要是通过rw-splitting.lua脚本实现的,因此需要安装lua。
安装Lua
cd /opt/install
wget http://www.lua.org/ftp/lua-5.1.4.tar.gz
tar zvfx lua-5.2.3.tar.gz
cd lua-5.1.4
vi src/Makefile
在 CFLAGS= -O2 -Wall $(MYCFLAGS) 这一行记录里加上-fPIC,更改为 CFLAGS= -O2 -Wall -fPIC $(MYCFLAGS) 来避免编译过程中出现错误。
make linux
make install
安装Mysql-proxy
MySQL-Proxy可通过以下网址获得:
http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/
推荐采用已经编译好的二进制版本,因为采用源码包进行编译时,最新版的MySQL-Proxy对automake,glib以及libevent的版本都有很高的要求,而这些软件包都是系统的基础套件,不建议强行进行更新。
并且这些已经编译好的二进制版本在解压后都在统一的目录内,因此建议选择以下版本:
32位RHEL5平台:
http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.4-linux-rhel5-x86-32bit.tar.gz
64位RHEL5平台:
http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.4-linux-rhel5-x86-64bit.tar.gz
1:测试平台为RHEL5 32位,因此选择32位的软件包
wget http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.3-linux-rhel5-x86-32bit.tar.gz
2:tar xzvf mysql-proxy-0.8.3-linux-rhel5-x86-64bit.tar.gz
3:mv mysql-proxy-0.8.3-linux-rhel5-x86-64bit /opt/mysql-proxy
4:创建mysql-proxy服务管理脚本
mkdir /opt/mysql-proxy/init.d/mysql-proxy
5:cp mysql-proxy /opt/mysql-proxy/init.d/
6:chmod +x /opt/mysql-proxy/init.d/mysql-proxy
7:mkdir /opt/mysql-proxy/run
8:mkdir /opt/mysql-proxy/log
9:mkdir /opt/mysql-proxy/scripts
配置rw-splitting.lua读写分离脚本
最新的脚本我们可以从最新的mysql-proxy源码包中获取
cd /opt/install
wget http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.4.tar.gz
tar xzvf mysql-proxy-0.8.4.tar.gz
cd mysql-proxy-0.8.4
cp lib/rw-splitting.lua /opt/mysql-proxy/scripts
修改读写分离脚本rw-splitting.lua
修改默认连接,进行快速测试,不修改的话要达到连接数为4时才启用读写分离
vim /opt/mysql-proxy/scripts/rw-splitting.lua
=============================
-- connection pool
if not proxy.global.config.rwsplit then
proxy.global.config.rwsplit = {
min_idle_connections = 1, //默认为4
max_idle_connections = 1, //默认为8
is_debug = false
}
end
启动mysql-proxy
1:启动之前编辑启动脚本
/opt/mysql-proxy/init.d/mysql-proxy
--daemon --log-level=debug --log-file=/var/log/mysql-proxy.log --proxy-backend-addresses="192.168.2.131:3306" --proxy-read-only-backend-addresses="192.168.2.132:3306" --proxy-lua-script=/opt/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua
2:直接mysql-proxy/bin/mysql-proxy直接启动
修改完成后,启动mysql-proxy/opt/mysql-proxy/init.d/mysql-proxy start
测试读写分离脚本参数详解:
//定义mysql-proxy服务二进制文件路径 1:PROXY_PATH=/opt/mysql-proxy/bin //定义后端主服务器地址 2:--proxy-backend-addresses=192.168.10.130:3306 //定义lua读写分离脚本路径 3:--proxy-lua-script=/opt/mysql-proxy/scripts/rw-splitting.lua“ //定义mysql-proxy PID文件路径 4: PROXY_PID=/opt/mysql-proxy/run/mysql-proxy.pid --daemon //定义以守护进程模式启动 --keepalive //使进程在异常关闭后能够自动恢复 --pid-file=$PROXY_PID //定义mysql-proxy PID文件路径 --user=mysql //以mysql用户身份启动服务 --log-level=warning //定义log日志级别,由高到低分别有(error|warning|info|message|debug) --log-file=/opt/mysql-proxy/log/mysql-proxy.log //定义log日志文件路径
遗留问题
MySQL-Proxy实际上非常不稳定,在高并发或有错误连接的情况下,进程很容易自动关闭,因此打开--keepalive参数让进程自动恢复是个比较好的办法,但还是不能从根本上解决问题,因此通常最稳妥的做法是在每个App服务器上安装一个MySQL-Proxy供自身使用,虽然比较低效但却能保证稳定性;
大数据量
什么是大数据量?
Mysql变慢
随着每天数据量的增加,Mysql的速度越来越慢
怎么办?
省钱神器
应用级别解决
1:解决Mysql高并发问题
2:解决随着时间,数据量越来越大问题
3:解决Mysql的Master节点单点故障问题
系统级别解决
4:双主解决Mysql备份问题
查看《si架构设计与实践.pptx》
用Oracle