1、初始化列表
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 int main() 7 { 8 std::vector<int> v1{1, 2, 3}; 9 10 std::cout << "v1 size : " << v1.size() << std::endl; 11 12 return 0; 13 }
上述程序用C++03标准是编不过去的。
2、auto 自动类型推导
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 int main() 7 { 8 std::vector<int> v1{1, 2, 3, 4}; 9 10 //c++ 03 11 for(std::vector<int>::iterator it = v1.begin(); it != v1.end(); it++) 12 std::cout << *it << " "; 13 std::cout << std::endl; 14 15 // c++ 11 16 for(auto it = v1.begin(); it != v1.end(); it++) 17 std::cout << *it << " "; 18 std::cout << std::endl; 19 20 21 return 0; 22 }
如果不使用auto自动类型推导的话,则需要自己写复杂的类型。
3、foreach 写法
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 int main() 7 { 8 std::vector<int> v1{1, 2, 3, 4}; 9 10 //c++ 03 11 for(std::vector<int>::iterator it = v1.begin(); it != v1.end(); it++) 12 std::cout << *it << " "; 13 std::cout << std::endl; 14 15 //c++ 11 read only 16 for(auto i : v1) 17 std::cout << i << " "; 18 std::cout << std::endl; 19 20 for(const auto& i : v1) 21 std::cout << i << " "; 22 std::cout << std::endl; 23 24 for(auto& i : v1) 25 i = 3; 26 for(auto i : v1) 27 std::cout << i << " "; 28 std::cout << std::endl; 29 30 31 return 0; 32 }
foreach写法。
4、nullptr代替了C++03 的NULL
5、enum class 代替了C++03的enum
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 enum type1{a, b, c}; 7 8 9 int main() 10 { 11 // 虽然a的类型被定义为type1,但是引用a的时候可以直接引用,也就是说这里的enum是弱类型的,加不加都一样 12 if(a == 0) 13 std::cout << "type1::a == 0" << std::endl; 14 15 return 0; 16 }
弱类型测试,运行结果:

可以看到我们在main函数中直接使用a也是可以的,也就是说enum定义的type1是弱类型,所以如果多个enum中定义了相同的符号就会报符号冲突的错误。
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 // 非强类型的作用域 7 // C中的匿名enum, 两种枚举类型都有a枚举常量,而且作用域相同,发生了冲突 8 //enum type1{a, b, c}; 9 //enum type2{a, d, e}; 10 11 enum type1{a, b, c}; 12 enum type2{d, e, f}; 13 14 enum type3{h=1, i=0xFFFFFFFFFLL}; 15 16 int main() 17 { 18 // 不同的enum类型可以互相比较,因为编译器首先将enum转换为int类型,再做的比较 19 if(type1::a == type2::d) 20 std::cout << "type1::a == type2::d" << std::endl; 21 22 // 占用的存储空间及符号不确定 23 std::cout << sizeof(type3::h) << std::endl; 24 std::cout << sizeof(type3::i) << std::endl; 25 26 return 0; 27 }
如果type1和type2中定义相同名字的成员则会报错,因为enum是弱类型的。非强类型作用域。
两种不同enum常量比较没有意义,但是编译器先将enum常量转换成int类型后再比较,不会报错
运行结果:

可以看出打印的大小都是8,因为b是一个比较大的数,所以按最大的来。
C++11中enum的强作用域:
1 #include <iostream> 2 3 using namespace std; 4 5 enum class type4:int{a, b, c}; // 指定底层类型 6 enum class type5{a, b, c}; // 不指定底层类型 7 8 9 int main() 10 { 11 type4 t = type4::a; //必须指定强类型名称 12 type4 p = a; 13 14 return 0; 15 }
12行的a没有指定强类型,编译报错。

不同类型之间也不能直接赋值。
1 #include <iostream> 2 3 using namespace std; 4 5 enum class type4:int{a, b, c}; // 指定底层类型 6 enum class type5{a, b, c}; // 不指定底层类型 7 8 9 int main() 10 { 11 type4 t = type4::a; //必须指定强类型名称 12 //type4 p = a; //这里a没有写作用域,编译报错 13 14 // 相同类型可以比较 15 if(t < type4::b) 16 std::cout << "t < type4::b" << std::endl; 17 18 // 非相同类型,不可隐式类型转换,编译报错 19 //if(t < type5::b) 20 // std::cout << "t < type5::b" << std::endl; 21 22 //可以强制类型转换 23 if((int)t < int(type5::b) ) 24 std::cout << "(int)t < int(type5::b)" << std::endl; 25 26 return 0; 27 }
上面是强类型的测试,不会有隐式类型转换。
指定底层类型:
1 #include <iostream> 2 3 using namespace std; 4 5 enum class type6:char{a=1, b=2}; 6 enum class type7:unsigned int{a=0xFFFFFFFF}; 7 8 int main() 9 { 10 std::cout << "sizeof(type6::a) = " << sizeof(type6::a) << std::endl; 11 std::cout << "sizeof(type7::a) = " << sizeof(type7::a) << std::endl; 12 13 return 0; 14 }
运行结果:

6、override关键字标识符
在子类中如果想重写某个虚函数,那么后面最好跟上override关键字,这样如果函数签名不小心写错的话,编译器会检查出来。
如果不写override关键字那么编译器检查不出来,这样的话相当于重新定义了一个函数,可能会引发bug。
7、final关键字
指示一个类或者虚函数不能再被重写
8、关键字default标识
强制编译器生成默认构造函数。
1 #include <iostream> 2 3 using namespace std; 4 5 class test 6 { 7 public: 8 test(int a) 9 { 10 data = a; 11 } 12 13 test() = default; 14 15 private: 16 int data; 17 }; 18 19 int main() 20 { 21 test t; 22 23 return 0; 24 }
我们定义了一个类并且定义了构造函数,这个时候默认构造函数是会被隐藏的。如果不写第13行,那么第21行是编译不过去的,因为第21行会调用默认
构造函数,但是默认构造函数被隐藏了,所以会报错。 加上第13行强制生成一个默认构造函数就好了。
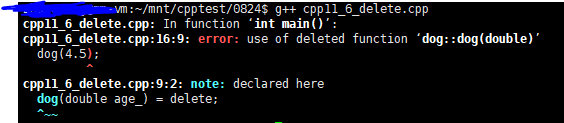
9、关键标识delete
delete放在函数后面,便是函数不能再被调用
1 #include <iostream> 2 3 class dog { 4 public: 5 dog(int age_) { 6 age = age_; 7 } 8 9 dog(double age_) = delete; 10 11 int age; 12 }; 13 14 int main(){ 15 dog(2); 16 dog(4.5); 17 18 return 0; 19 }
如果不加第9行,第16行是可以编译过的,因为4.5这个double类型会被强制转换为int类型而调用第5行的构造函数。
如果加上第9行,表示删掉这个构造函数,这样就不会进行隐式类型转换了,而是编译直接报错。
10、lambda 函数
1 #include <iostream> 2 3 int main(){ 4 std::cout << [](int x, int y) {return x + y; }(3, 5) << std::endl; 5 }
lambda表达式方便定义一些小函数,使程序更优雅。
11、智能指针
shared_ptr、unique_ptr、weak_ptr
12、tuple元组
tuple容器,表示元组容器,可以用于函数返回多个返回值。
tuple容器,可以使用直接初始化和make_tuple初始化,访问元素使用get<>()方法,注意,get里面的位置信息必须是常量表达式。
可以通过std::tuple_size<decltype(t)>::value获取元素数量,std::tuple_element<0, decltype(t)>::type获取元素类型。
如果tuple类型进行比较,则需要保持元素数量相同,类型可以比较(相同类型,或者可以相互转换的类型)。
无法使用for类似的方法遍历tuple容器,因为get<>()方法无法使用变量获取值。
1 #include <iostream> 2 #include <tuple> 3 4 using namespace std; 5 6 std::tuple<std::string, int> get_tuple() 7 { 8 std::string s("test_tuple1"); 9 int a{2020}; 10 11 std::tuple<std::string, int> t = make_tuple(s, a); 12 13 return t; 14 } 15 16 17 int main() 18 { 19 std::tuple<int, double, std::string> t1(64, 128.0, "test_tuple2"); 20 std::tuple<std::string, std::string, int> t2 = std::make_tuple("test_tuple3", "test_tuple4", 200); 21 22 // 测试返回元素个数 23 size_t num = std::tuple_size<decltype(t1)>::value; 24 std::cout << "t1 size : " << num << std::endl; 25 26 // 获取第一个值的元素类型 27 std::tuple_element<1, decltype(t1)>::type v1 = std::get<1>(t1); 28 auto v2 = std::get<1>(t1); 29 std::cout << "v1 : " << v1 << std::endl; 30 std::cout << "v2 : " << v2 << std::endl; 31 32 // tuple的比较 33 std::tuple<int, int> ti(24, 48); 34 std::tuple<double, double> td(28.0, 56.0); 35 36 if(ti < td) 37 std::cout << "ti < td" << std::endl; 38 else 39 std::cout << "ti >= td" << std::endl; 40 41 42 // 测试tuple的返回值 43 auto ret = get_tuple(); 44 45 std::cout << "first : " << std::get<0>(ret) << " , second : " << std::get<1>(ret) << std::endl; 46 47 return 0; 48 }
运行结果:
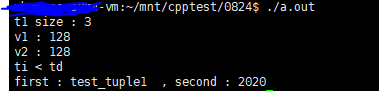
get也可以用在pair和array上。
get可能返回引用和常引用。这个跟参数的类型有关,使用时仔细查官方文档。
13、pair的使用
pair是将两个数据合成一个数据,当需要这样的需求时就可以使用pair,如stl中的map就是将key和value放在一起来保存。另一个应用是,当一个函数需要返回2个数据的时候,可以选择pair。
1 #include <iostream> 2 #include <utility> 3 4 using namespace std; 5 6 int main() 7 { 8 std::pair<int, float> pair1 = make_pair(18, 3.14f); 9 10 std::cout << pair1.first << " " << pair1.second << std::endl; 11 pair1.first = 20; 12 pair1.second = 6.28f; 13 14 std::cout << pair1.first << " " << pair1.second << std::endl; 15 16 std::pair<float, double> pair2(3.14f, 6.28f); 17 std::cout << pair2.first << " " << pair2.second << std::endl; 18 19 return 0; 20 }
运行结果:

上面程序中可以看到pair的两种构造方式。
14、定义常量 constexpr
对于修饰object来说,const并未区分出编译期常量和运行期常量, 而constexpr限定在了编译期常量
对于修饰函数来说,constexpr修饰的函数,返回值不一定是编译期常量。 # It is not a bug, It is a feature。
程序:
1 #include <iostream> 2 #include <array> 3 4 using namespace std; 5 6 constexpr int foo(int i) 7 { 8 return i + 5; 9 } 10 11 int main() 12 { 13 int i = 10; 14 std::array<int, foo(5)> arr; // Ok 15 16 std::cout << "arr size : " << arr.size() << std::endl; 17 18 foo(i); // Call is Ok 19 20 //std::array<int, foo(i)> arr1; // Error 21 22 return 0; 23 }
上面的程序中14行的foo(5)可以在编译期确定,而array的第二个模板参数正好需要常量,所以可以编译通过。
第20行foo(i)无法在编译期确定,所以编译会报错。
constexpr修饰的函数,简单的来说,如果其传入的参数可以在编译时期计算出来,那么这个函数就会产生编译时期的值。但是,传入的参数如果不能在编译时期计算出来,那么constexpr修饰的函数就和普通函数一样了。不过,我们不必因此写两个版本,所以如果函数体适用于constexprh函数的条件,可以尽量加上constexpr。
而检测constexpr函数是否产生编译时期值的方法很简单,就是利用std::array需要编译期常值才能编译通过的小技巧。这样的话,即可检测你所写的函数是否真的产生编译期常值了。
15、decltype和auto
auto能让编译器通过初始值来进行类型推演,从而获得定义变量的类型,所以auto定义的变量必须有初始值。
auto会忽略引用,会忽略顶层const,如果希望推断出auto类型是一个顶层const,需要明确指出,例:const auto f = xxx;
当我们希望从表达式中推断出要定义的变量,但却不想用表达式的值去初始化变量,还有可能函数的返回类型为某表达式的值类型。这时候用auto就显得无力了。这时需要使用decltype,它的作用是选择并返回操作数的数据类型,在此过程中,编译器只是分析表达式并得到它的类型,却不进行实际的计算表达式的值。
decltype和auto在推导类型时还有一些深坑,需要查阅文档。
decltype还有一个用途就是在c++11引入的后置返回类型。
https://www.cnblogs.com/Excr/p/12516095.html
decltype推导规则:
- 如果e是一个没有带括号的标记符表达式或者类成员访问表达式,那么的decltype(e)就是e所命名的实体的类型。此外,如果e是一个被重载的函数,则会导致编译错误。
- 否则 ,假设e的类型是T,如果e是一个将亡值,那么decltype(e)为T&&
- 否则,假设e的类型是T,如果e是一个左值,那么decltype(e)为T&。
- 否则,假设e的类型是T,则decltype(e)为T。
16、后置返回类型
1 #include <iostream> 2 using namespace std; 3 4 template <typename _Tx, typename _Ty> 5 auto multiply1(_Tx x, _Ty y) 6 { 7 return x*y; 8 } 9 10 11 /* 12 template <typename _Tx, typename _Ty> 13 auto multiply1(_Tx x, _Ty y)->decltype(x * y) 14 { 15 return x*y; 16 } 17 */ 18 19 20 int main() 21 { 22 auto ret = multiply1(30, 50); 23 24 std::cout << "ret : " << ret << std::endl; 25 26 return 0; 27 }
上面的代码用c++11标准是编译不过去的。报错如下:

使用C++14标准是可以编译通过的。
如果非要使用C++11标准编译,那么需要使用后置返回类型。
1 #include <iostream> 2 using namespace std; 3 4 /* 5 template <typename _Tx, typename _Ty> 6 auto multiply1(_Tx x, _Ty y) 7 { 8 return x*y; 9 } 10 */ 11 12 template <typename _Tx, typename _Ty> 13 auto multiply1(_Tx x, _Ty y)->decltype(x * y) 14 { 15 return x*y; 16 } 17 18 int main() 19 { 20 auto ret = multiply1(30, 50); 21 22 std::cout << "ret : " << ret << std::endl; 23 24 return 0; 25 }
这样使用C++11标准就可以编译通过了。
17、完美转发
1 #include <iostream> 2 3 using namespace std; 4 5 template<typename T> 6 void PrintT(T& t) 7 { 8 cout << "lvaue" << endl; 9 } 10 11 template<typename T> 12 void PrintT(T && t) 13 { 14 cout << "rvalue" << endl; 15 } 16 17 template<typename T> 18 void TestForward(T && v) 19 { 20 PrintT(v); 21 PrintT(std::forward<T>(v)); 22 PrintT(std::move(v)); 23 } 24 25 void Test() 26 { 27 TestForward(1); 28 std::cout << std::endl; 29 int x = 1; 30 TestForward(x); 31 std::cout << std::endl; 32 TestForward(std::forward<int>(x)); 33 } 34 35 int main() 36 { 37 Test(); 38 39 return 0; 40 }
forward作用于一个变量,非左值引用,就返回右值引用。如果是左值引用,则返回原来的类型,也就是左值引用。
运行结果:
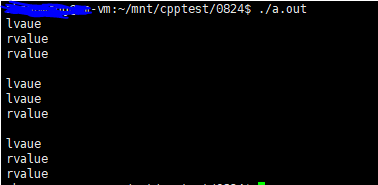
第32行的forward<int>(x),因为x是非左值引用,所以调用完forward之后表达式就变成了右值引用。
参考:https://www.cnblogs.com/qicosmos/p/3376241.html
引用折叠:
https://blog.csdn.net/douzhq/article/details/89504508
完美转发是目标,也就是保证传入函数的参数是什么类型,转发给子函数时就是什么类型。
引用折叠是人为定义出来的规则,具体由forward来实现,最终达到完美转发的目标。
https://blog.csdn.net/beyongwang/article/details/54025439?utm_source=blogxgwz6
18、可变参数模板