关于REST
Resource:资源,即数据(前面说过网络的核心)。比如 books;
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词GET、PUT、POST等来实现。
以前的网页都是前后端融合到一体的。但近年来随着移动互联网的发展,各种类型的客户端层出不穷,导致需要很多种接口才能满足需求。这样不利于开发工作。故前后端分离模式应运而生。
而RESTful 风格的API提供了一套统一的接口来满足Web,IOS,Android的需求,非常适合于前后端分离的项目。
RESTful风格的API的好处:
看Url就知道要什么;
看http method就知道干什么;
看http status code就知道结果如何。
下面使用django原生形式实现前后端分离的RESTful架构的API。
正常情况下,如果使用django去写一个图书管理的后端,需要很多接口。包括查询所有图书的接口,查询指定图书的接口,新增图书接口,修改图书的接口,删除图书的接口。这里用CBV类视图来实现。
根据路由后面有没有带pk/id可将这些接口分为两类,即不带pk的列表视图和带pk的详情视图。
列表视图内有get查询所有图书的接口和post新增单一图书的接口。如下:
1 class BookListView(View): 2 """列表视图""" 3 4 def get(self,request): 5 """查询所有图书接口""" 6 # 1、查询所有图书模型 7 books = Book.objects.all() 8 # 2、遍历查询集,取出里面的每个书籍模型对象,转化为字典 9 book_list = [] 10 for book in books: 11 book_dict = { 12 'nid':book.nid, 13 'name':book.name, 14 'price':book.price, 15 'author':book.author 16 } 17 book_list.append(book_dict) 18 # 3、响应 19 return JsonResponse(book_list,json_dumps_params={'ensure_ascii':False},safe=False) # 将字典序列化为json 20 # JsonResponse类的data参数默认为字典,safe参数默认为true,如果不是字典则应该设置safe=False 21 # 注意:json_dumps_params参数默认为None,此时如果响应的字典中包含中文,则在客户端显示的是Unicode字符集的16进制码位,如u8c; 22 # 如果想要显示中文,则应将ensure_ascii的默认参数True改为False。 23 24 def post(self,request): 25 """新增图书接口""" 26 # 要先在settings.py中关闭CSRF验证 27 # 1、获取json格式的请求数据的字节流,由utf-8编码的16进制表示 如x6c 28 json_bytes = request.body 29 # print(request.body) 30 # for k,v in request.environ.items(): # 打印请求头信息 31 # print(k,v) 32 # 2、将字节流转化为json格式的字符串 33 json_str = json_bytes.decode() 34 # 3、将字符串转化为json格式的字典 35 json_dict = json.loads(json_str) 36 # 4、新增模型数据 37 book = Book( 38 name=json_dict['name'], 39 price=json_dict['price'], 40 author=json_dict['author'] 41 ) 42 # 5、保存模型 43 book.save() 44 # 6、响应字典 45 jd = { 46 'nid':book.nid, 47 'name':book.name, 48 'price':book.price, 49 'author':book.author 50 } 51 return JsonResponse(jd,json_dumps_params={'ensure_ascii':False},status=201)
详情视图
1 class BookDetailView(View): 2 """详情视图""" 3 def get(self,request,pk): 4 """查询指定的图书接口""" 5 # 1、获取指定pk的模型对象; 6 try: 7 book = Book.objects.get(nid=pk) # id超出范围的异常处理 8 except Book.DoesNotExist: 9 print('查询数据不存在') 10 return HttpResponse("查询数据不存在", status=404) 11 12 # 2、将模型对象转换为字典; 13 book_dict = { 14 'nid':book.nid, 15 'name':book.name, 16 'price':book.price, 17 'author':book.author 18 } 19 # 3、响应字典给前端 20 return JsonResponse(book_dict,json_dumps_params={"ensure_ascii":False}) 21 22 def put(self,request,pk): 23 """修改指定的图书接口""" 24 # 1、获取指定pk的模型对象 25 try: 26 book = Book.objects.get(nid=pk) # id超出范围的异常处理 27 except Book.DoesNotExist: 28 return HttpResponse("要修改的数据不存在", status=404) 29 # 2、获取并将请求的数据转换为json字典 30 book_dict = json.loads(request.body.decode()) 31 # 3 、修改模型对象并保存 32 book.name = book_dict['name'] 33 book.price = book_dict['price'] 34 book.author = book_dict['author'] 35 book.save() 36 # 4、将修改后的模型对象转换为字典 37 book_modified_dict = { 38 'nid': book.nid, 39 'name': book.name, 40 'price': book.price, 41 'author': book.author 42 } 43 # 5、响应字典 44 return JsonResponse(book_modified_dict,json_dumps_params={'ensure_ascii':False}) 45 46 def delete(self,request,pk): 47 try: 48 book = Book.objects.get(nid=pk) 49 except Book.DoesNotExist: 50 return HttpResponse('要删除的数据不存在',status=404) 51 book.delete() 52 return HttpResponse(status=204) # 请求执行成功,但没有数据返回
DRF实现接口
用drf来实现上面的图书接口,总共10行代码:
1、在urls.py中注册路由:

2、新建ser.py,添加序列化器:
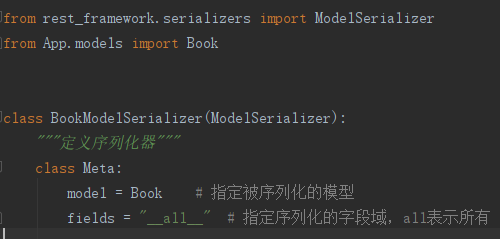
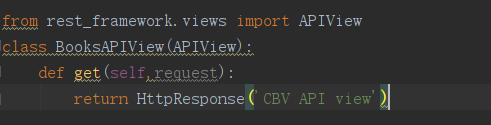
3、在views.py中写入类视图:

浏览器访问:
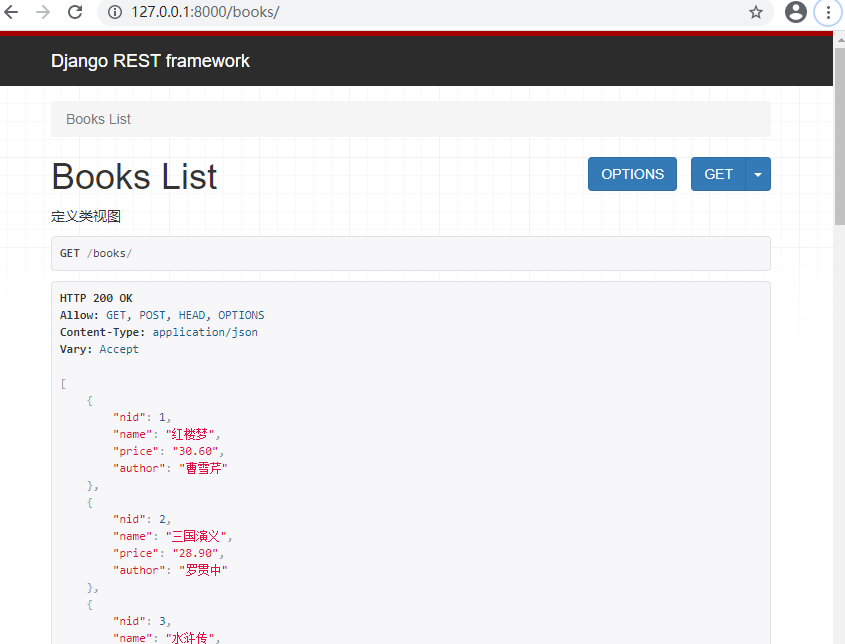

为何如此简洁的代码就能实现接口功能呢?这就因为dfr内部对数据之间的转换进行了一系列的封装,这就涉及到序列化和反序列化。
序列化和反序列化
当需要给前端响应模型数据时,需要将模型数据序列化成前端需要的格式。
当需要将用户发送的数据存储到数据库时,就要将数据如字典、json、xml等反序列化成Django中的数据库模型类对象再保存。
这就是在开发RESTful API时,在视图中要做的最核心的事情。
。。。
DRF实例-book
查看部分源码

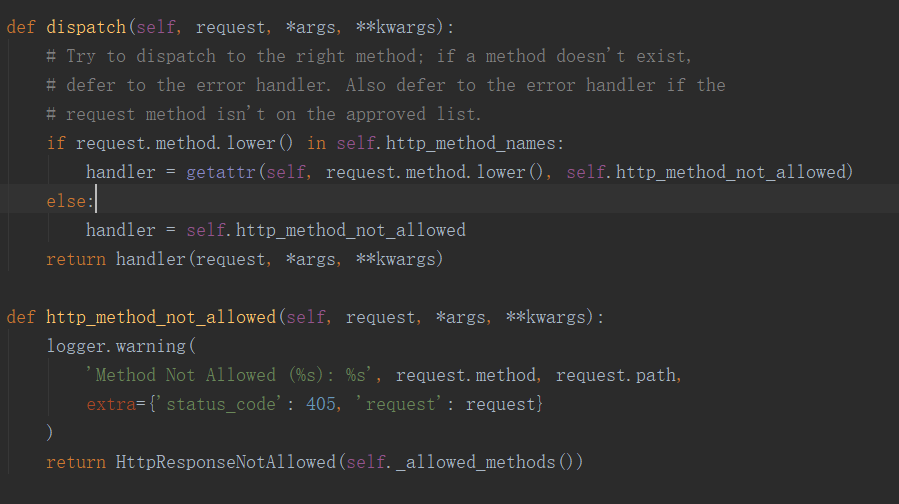


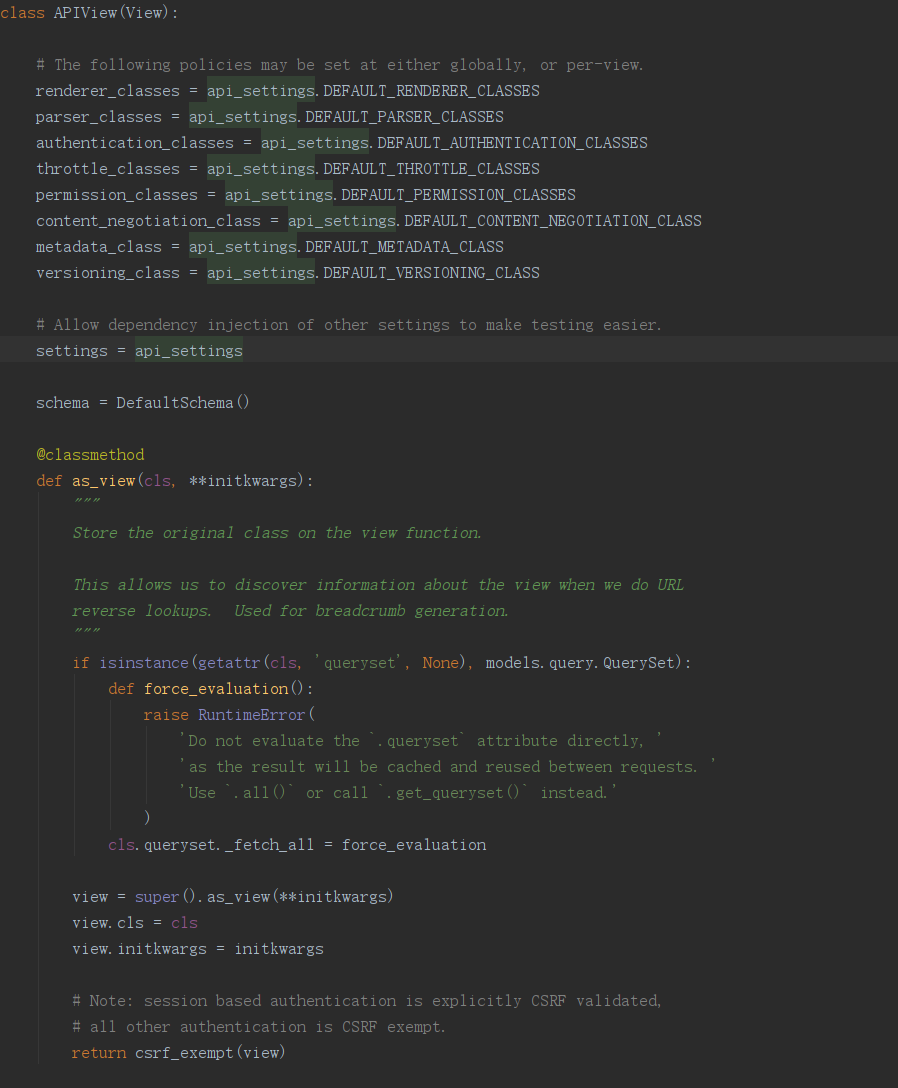

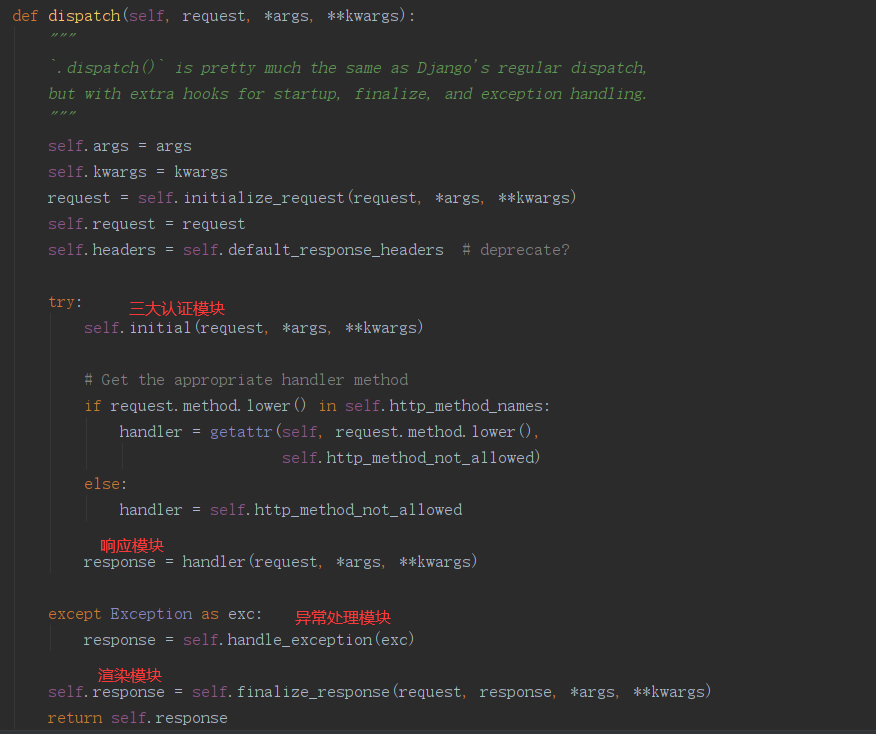
1 def dispatch(self, request, *args, **kwargs):
2 """
3 `.dispatch()` is pretty much the same as Django's regular dispatch,
4 but with extra hooks for startup, finalize, and exception handling.
5 """
6 self.args = args
7 self.kwargs = kwargs
8 request = self.initialize_request(request, *args, **kwargs)
9 self.request = request
10 self.headers = self.default_response_headers # deprecate?
11
12 try:
13 self.initial(request, *args, **kwargs)
14
15 # Get the appropriate handler method
16 if request.method.lower() in self.http_method_names:
17 handler = getattr(self, request.method.lower(),
18 self.http_method_not_allowed)
19 else:
20 handler = self.http_method_not_allowed
21
22 response = handler(request, *args, **kwargs)
23
24 except Exception as exc:
25 response = self.handle_exception(exc)
26
27 self.response = self.finalize_response(request, response, *args, **kwargs)
28 return self.response
request = self.initialize_request(request, *args, **kwargs) 这句代码对原来的request进行了初始化封装,加入了很多东西如请求解析内容。使得现在的request不再是HttpRequest的对象,而是rest_framework/request.py模块里的Request类的对象。
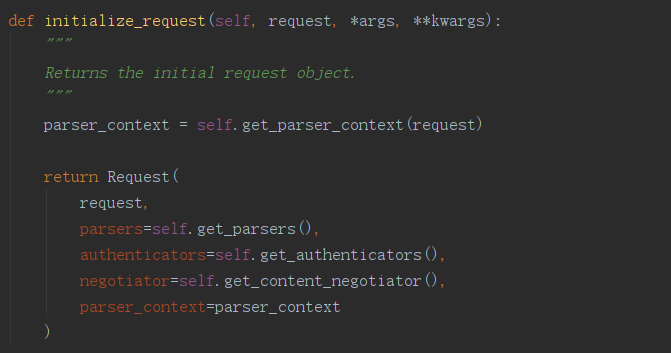
在Request类中,原本请求的request对象变成了类的一个受保护属性_request(不能通过from xx import xx的方式导入)。
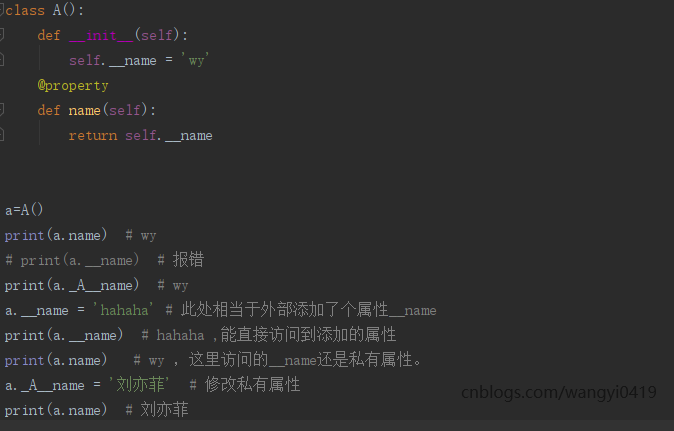
补充:类中的私有属性__y是不能被类的对象和子类直接引用的,因为在python中,是通过改名的方式实现属性的私有的,python会在内部会将类A的私有属性__y改名为_A__y。所以使用对象a.__y是找不到该属性的,而使用a._A__y是可以操作__y属性的。 这种语言特性叫做名称改写。

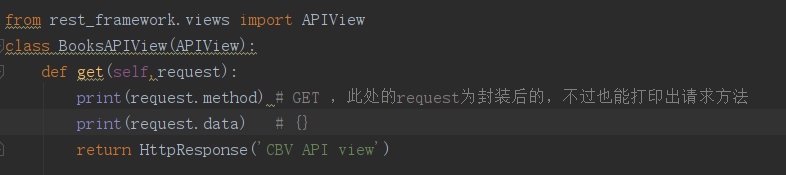
此时如果在类视图中print(request.method)会有什么结果?答案是能够正常获取到了请求的方法。为什么封装后request也能获得请求的方法?因为类Request对__getattr__方法进行了重写,当我们获取请求方法找不到时就会调用这个内建方法,而此时又重写了,在重写后的__getattr__里,又通过反射来获取到了self._request的属性,也就是原生request的method属性。
参考:https://www.cnblogs.com/wangyi0419/p/12592492.html
补充反射:
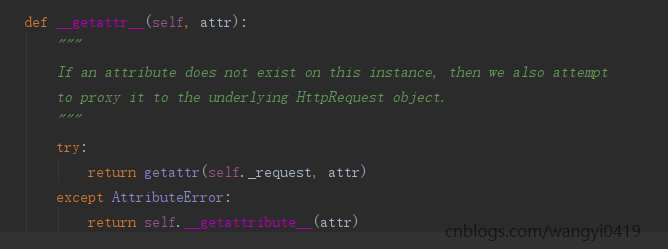
问题:这里的except中的 return self.__getattribute__(attr)我没看懂什么意思,self不是不能直接调用__getattrbute__()吗?
data看起来像个属性,但其实是一个被@property装饰器装饰过的方法。他能返回多种格式的请求数据。
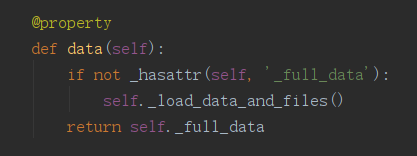
补充一下装饰器@property的作用:
第一:@property是为了让人方便的像调用属性一样去调用方法,不用带();
第二:与所定义的属性配合使用,这样可以防止属性被修改。让外部直接调用给定的方法名,而不知道该方法返回的真正的属性名。从而达到了隐藏属性名的作用,让用户进行使用的时候不能随便更改。
python默认的成员函数和成员变量都是公开的。可以通过加双下划线将属性变为私有,不过私有不绝对,也是可以通过_类名__属性名的方式访问和修改的。