Stacked Cross Attention for Image-Text Matching
2020-03-06 15:13:08
Paper: https://arxiv.org/pdf/1803.08024.pdf
Code: https://github.com/kuanghuei/SCAN
Project: https://kuanghuei.github.io/SCANProject/
1. Stacked Cross Attention Network
本文提出了一个 Stacked Cross Attention Network 将 words 和 image regions 映射到一个共同的 embedding space 来预测整张图和一个句子之间的相似性。作者首先用 bottom-up attention 来检测和编码图像区域,提取其 feature。与此同时,也对 word 进行单词映射。然后用 Stacked Cross Attention 来推理对齐后的 image region 和 word feature 之间的 image-sentence similarity。
1.1. Stacked Cross Attention:
Stacked Cross Attention 的输入有两个:一个是 image features V = {v1, v2, ... , vk},每一个图像特征编码了图像中的一个区域;另外一个是单词特征组合是 E = {e1, e2, ... , en},每一个单词特征编码了句子中的一个单词。输出是 image-pair 之间的相似性得分。本文定义了两种互补的形式:Image-Text 以及 Text-Image 的版本。
Image-Text Stacked Cross Attention:这种形式的模型涉及到两个阶段的 attention,如图 2 所示。
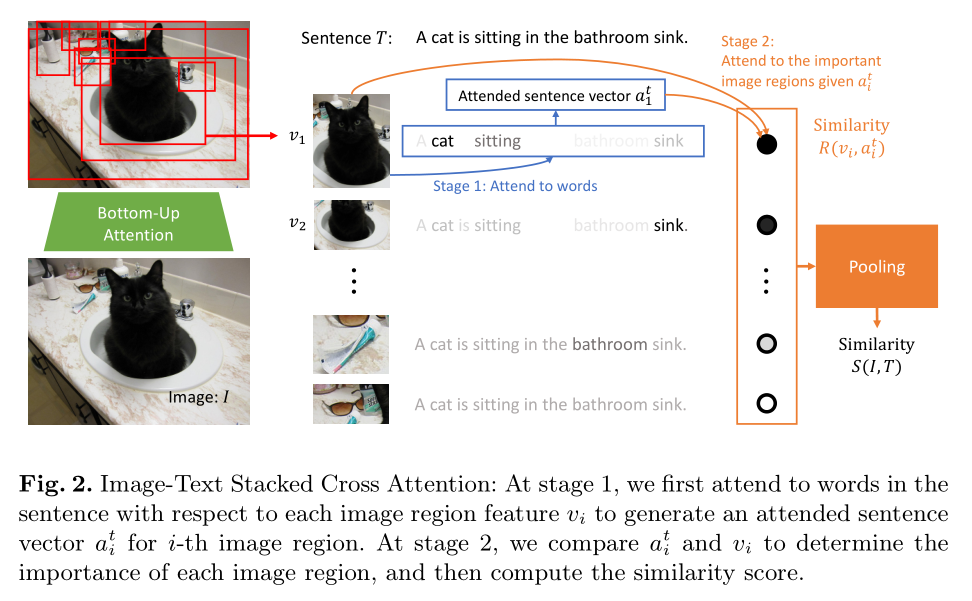
首先,用对应每一个图像区域来 attend 句子中的单词。第二阶段中,其对比了每一个图像区域和对应 attended 句子向量,从而确定图像区域的重要性。具体来说,给定图像 I 及其 k 个检测的区域,一个带有 n 个单词的句子 T,我们首先计算所有图像对之间的余弦相似性:
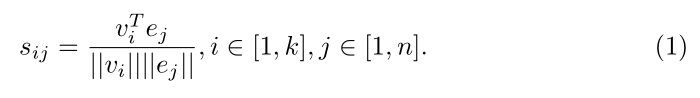
此处,sij 代表了 第 i 个region 和 第 j 个word 之间的相似性。经验表明,将该相似性得分进行归一化处理后为:
![]()
为了用对应图像区域对 word 进行 attend,此处作者给 word representation 进行了加权组合:
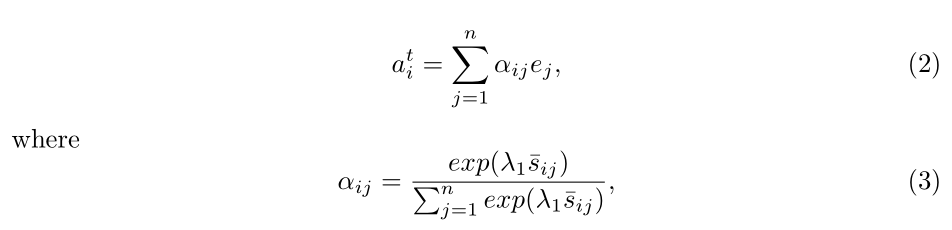
给定句子向量,为了确定每一个图像区域的重要性,作者定义了第 i 个 region 和 句子之间的相关性作为 attended sentence vector 和 image region feature vi 之间的余弦相似性:
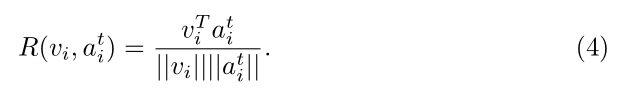
受到 speech recognition 中最小化分类误差的启发,图像 I 和 句子 T 之间的相似性可以用 Log-SumExp pooling 来计算:
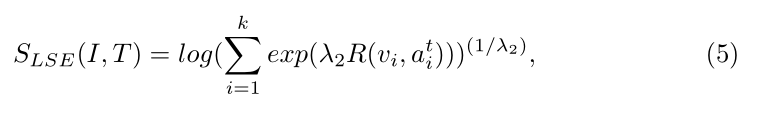
其中 $lambda_2$ 是一个超参数,决定了图像区域特征 和 attend 之后句子向量之间最相关的 pairs 的重要性。作者定义 ![]() 为:
为:
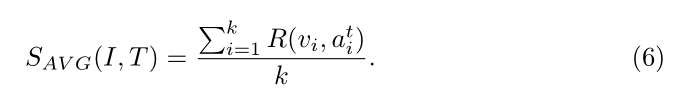
本质上来说,如果 region i 在句子中没有被提及,那么,其 feature vi 将不会和对应的 attended 句子向量相似,因为这样就不会收集较好的信息来计算 $a_i^t$。所以,对比 $a^t_i$ 和 vi 决定了区域 i 对于句子来说是否重要。
Text-Image Stacked Cross Attention:
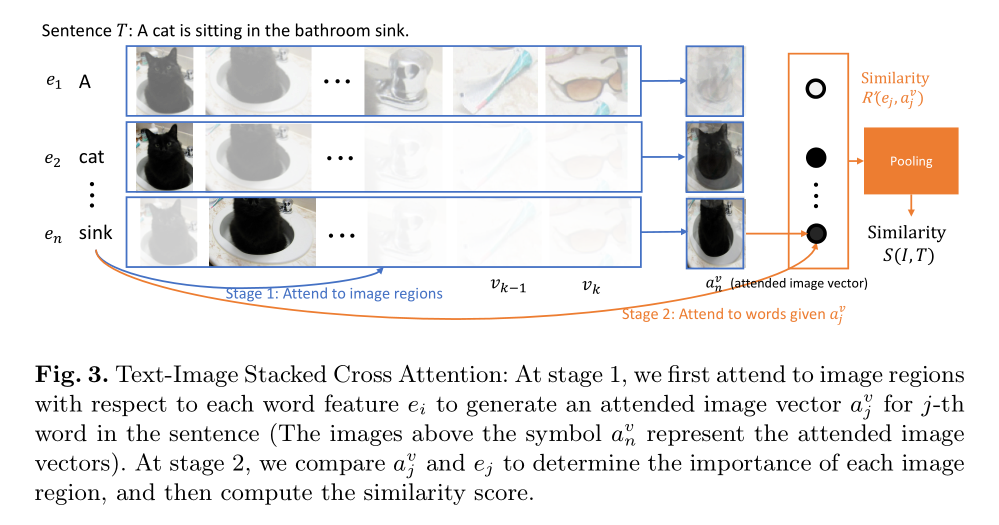
类似的操作。
1.2. Alignment Objective:
对于 Image-Text matching 来说,通常采用 triplet loss,之前的方法也采用了 hinge-based triplet ranking loss:
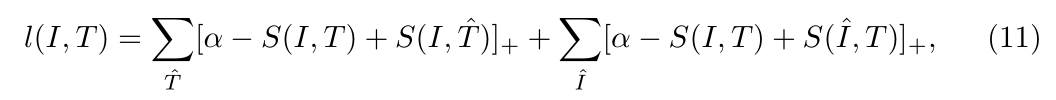
其中,S 代表相似性得分函数,即 $S_{LSE}$。给定一个图像 I,第一个 sum 考虑到了所有的 negative samples;给定一个句子 T,第二个 sum 考虑到了所有的 negative images。实际上,为了计算效率起见,一般只考虑 mini-batch 中的 hard negatives,而不是将所有的 negative samples 都加起来。在本文中,作者聚焦于一个 mini-batch 中的 hardest negatives,对于一个 positive pair (I, T),hardest negatives 可以通过如下的方式给定:
![]()
所以,本文的三元组损失函数可以表达为:
![]()
1.3. Representing Images with Bottom-Up Attention:
给定一张图像 I,本文的目标是用一系列的图像来表示,即:V = {v1, v2, ... , vk},这样就使得每一个图像特征编码了一个区域。关于图像区域的定义是通用的,然而,本文聚焦于物体级别。本文将显著性物体的检测作为一种 bottom-up attention,并且用 Faster RCNN model 来实现。Faster RCNN 模型是一种两阶段的物体检测框架。在第一个 RPN 的阶段,用anchor 机制生成多种样式的 bounding box。在第二个阶段,从 feature map 上得到 RoIs 的 feature,以进行后续 region-wise classification 和 bounding box regression。在 RPN 和 final stages 都会进行 classification 和 localization 的多任务的训练。本文将 Faster RCNN 和 Resnet-101 进行组合,并且在 Visual Genomes 上进行预训练。为了用丰富的语义信息学习特征表示,模型预测 attribute classes 和 instance classes,instance classes 包含物体和其他难以定位的东西,如:stuff 像:sky, grass, building;attributes 像 furry。
对于每一个选中的区域 i,$f_i$ 是从该区域中得到的 mean-pooled convolutional feature,这样就使得 image feature vector 的维度变为 2048。作者添加了一个 fc layer 将 $f_i$ 转换为 h-dimensional 的向量:

所以,图像完整的表示是一组 embedding vectors v = {v1, v2, ..., vk},其中每一个 $v_i$ 表示一个显著区域,k 是 regions 的个数。
1.4. Representing Sentences:
为了连接视觉和语言,作者将 language 映射到和 image regions 相同维度的语义向量。给定一个句子 T,最简单的方法是将每一个单词进行单独的映射。然而,这种方法没有考虑到句子中的任何语义信息。所以,作者采用 RNN 模型对这些单词按照他们的内容进行再编码。对于句子中的每一个单词,作者用 one-hot vector 对其进行编码,然后根据一个映射矩阵 We 对其进行 embedding,得到一个 300-D 的向量。$x_i = W_e w_i$,然后利用一个双向 GRU 将 vector 进行映射,这会考虑到句子两个方向的信息。作者将前向和反向得到的编码 feature 拼接到一起当做是句子的最终表达:
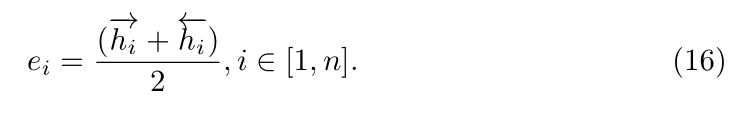
2. Experiment: