【是什么】
KNN 即 k_近邻算法(k- nearest neighbor) ,就是寻找K个邻居作为该样本的特征,近朱者赤,近墨者黑,你的邻居是什么特征,那么就认为你也具备该特征;核心公式为:
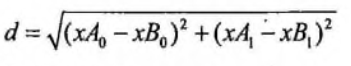
数据来源:https://github.com/apachecn/AiLearning/blob/master/data/2.KNN/datingTestSet2.txt
读取数据转换成矩阵
# 提取文件中的数据 转换成矩阵 def file2matric(filename): """ disc: param: filename: 导入数据文本 return: 数据矩阵 """ f = open(filename,'r',encoding= 'utf-8') # 获取文件的行数 lines_list = f.readlines() num_of_lines = len(lines_list) # 创建存放标签的列表 class_label_list = [] # 生成对应的空矩阵 zeros(2,3) 就是生成2行3列的0矩阵 returnMat = np.zeros((num_of_lines,3)) # 将文本中的数据放到矩阵中 for i in range(num_of_lines): lines = lines_list[i].strip().split(' ') # 将文本中的前3个数据放到矩阵中 returnMat[i,:] = lines[0:3] # 将标签存到列表中 class_label_list.append(int(lines[-1])) # print(returnMat) return returnMat, class_label_list
利用 matplotlib 绘制散点图
def DrawScatter(dataMat,label_list): # 导入中文字体,及字体大小 zhfont = FontProperties(fname='C:/Windows/Fonts/simsun.ttc', size=14) # 绘制绘图窗口 2行2列 fig,ax = plt.subplots(2,2,figsize=(13,8)) # 不同标签赋予不同颜色 label_color = [] for i in label_list: if i == 1: label_color.append('black') elif i == 2: label_color.append('orange') elif i == 3: label_color.append('red') # 开始绘制散点图 设定散点尺寸与透明度 scatter_size = 12 scatter_alpha = 0.5 # ===================散点图======================== ax[0][0].scatter(dataMat[:,0], dataMat[:,1],color = label_color,s = scatter_size ,alpha = scatter_alpha) ax[0][1].scatter(dataMat[:, 1], dataMat[:, 2], color=label_color, s=scatter_size , alpha=scatter_alpha) ax[1][0].scatter(dataMat[:, 0], dataMat[:, 2], color=label_color, s=scatter_size , alpha=scatter_alpha) # 坐标轴标题 title_list = ['每年获得的飞行常客里程数和玩视频游戏所消耗时间占比', '每年获得的飞行常客里程数和每周消费的冰激淋公升数', '玩视频游戏所消耗时间占比和每周消费的冰激淋公升数'] x_name_list = ['每年获得的飞行常客里程数','玩视频游戏所消耗时间占比','每周消费的冰激淋公升数'] y_name_list = ['玩视频游戏所消耗时间占比','每周消费的冰激淋公升数','每年获得的飞行常客里程数'] #设置图例 didntLike = mlines.Line2D([], [], color='black', marker='.', markersize=6, label='didntLike') smallDoses = mlines.Line2D([], [], color='orange', marker='.', markersize=6, label='smallDoses') largeDoses = mlines.Line2D([], [], color='red', marker='.', markersize=6, label='largeDoses') p = 0 for i in range(2): for j in range(2): if p > 2: break # 设置坐标轴名称和标题 plt.setp(ax[i][j].set_title(u'%s'%(title_list[p]),FontProperties = zhfont),size=9, weight='bold', color='red') plt.setp(ax[i][j].set_xlabel(u'%s'%(x_name_list[p]),FontProperties = zhfont), size=7, weight='bold', color='black') plt.setp(ax[i][j].set_ylabel(u'%s'%(y_name_list[p]),FontProperties = zhfont), size=7, weight='bold', color='black') p+=1 # 添加图例 ax[0][0].legend(handles=[didntLike, smallDoses, largeDoses]) ax[0][1].legend(handles=[didntLike, smallDoses, largeDoses]) ax[1][0].legend(handles=[didntLike, smallDoses, largeDoses]) plt.show()

对数据进行归一化处理
由于不同数据的范围波动不同,在权重一样的情况下,需要进行归一化,即将数据转换成0-1之间
# 对矩阵进行归一化处理 def dataNorm(dataMat): """ :param dataMat: :return: 归一化后的数据集 归一化公式: Y = (X - Xmin)/(Xmax - Xmin) """ # max(0) min(0) 求出每列的最大值和最小值 d_min = dataMat.min(0) d_max = dataMat.max(0) # 计算极差 d_ranges = d_max - d_min # 创建输出矩阵 normDataSet = np.zeros(np.shape(dataMat)) print(normDataSet) # 获得矩阵行数 .shape 获取矩阵的大小 3x3 m = dataMat.shape[0] # 计算 (X - Xmin) 这部分 首先要创建Xmin矩阵 将d_min扩展到m行 # 需要使用np.tile 函数进行扩展 将d_min扩展成m行1列 变成m x 3 矩阵 normDataSet = dataMat - np.tile(d_min,(m,1)) print(normDataSet) # 计算Y normDataSet = normDataSet / np.tile(d_ranges,(m,1)) print(normDataSet) return normDataSet
创建分类函数与分类器(kNN算法的实现)
(ps:每次都需要将测试数据与所有训练数据进行对比,感觉比较繁琐)
def classfy_fun(test_data, train_data, labels, k): """ :param test_data: 测试集 :param train_data: 训练集 :param labels: 训练集标签 :param k: KNN 算法参数 选择距离最小的个数 :return: 分类结果 """ # 计算训练集的矩阵行数 train_size = train_data.shape[0] # 接下来按照欧氏距离进行元素距离计算 公式 # 将测试集扩充成与训练集相同行数 求差 diffMat = np.tile(test_data,(train_size,1)) - train_data # 将差值矩阵的每个元素平方 sq_diffMat = diffMat**2 # 差值平方矩阵每行元素相加 axis = 1 是按行相加 sum_diffMat = sq_diffMat.sum(axis = 1) # 对新的求和矩阵进行开方 得到距离值 distances = sum_diffMat ** 0.5 # 获得距离值中从小到大值的索引 sorted_distant = distances.argsort() # 定义一个字典 存放标签 与 出现的数量 class_count = {} for i in range(k): # 找出前k个距离值最小的对应标签 temp_label = labels[sorted_distant[i]] # 将标签作为 key 存放到字典中 出现次数作为 value class_count[temp_label] = class_count.get(temp_label,0) + 1 # 将字典按照value 大小进行排序 sort_class_count = sorted(class_count.items(),key = operator.itemgetter(1)) return sort_class_count[0][0] pass # 创建分类器函数 def dating_class_test(): # 首先获取文件,将文件分成测试集和训练集 dating_Mat, dating_label = file2matric('datingdata.txt') # 设置测试集的比例 test_ratio = 0.1 # 数据归一化 normMat = dataNorm(dating_Mat) #获得矩阵的行数 m = normMat.shape[0] # 计算测试集的数量 numTestData = int(m * test_ratio) # 错误分类的数量 error_count = 0.0 for i in range(numTestData): class_result = classfy_fun(dating_Mat[i,:], dating_Mat[numTestData:m,:], dating_label[numTestData:m],4 ) print("分类结果:%s,实际分类:%s"%(class_result,dating_label[i])) if class_result != dating_label[i]: error_count += 1 # print("错误识别的数量:%f" %error_count) print("正确率:%f%% " %((1 - error_count / numTestData)*100))

从结果看 识别率还是很低的,目前k值为4 ,可以改变k值看看正确率的变化
完整代码


1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 """ 4 【KNN 实战】 5 6 """ 7 import numpy as np 8 import matplotlib.pyplot as plt 9 import matplotlib.lines as mlines 10 from matplotlib.font_manager import FontProperties 11 import operator 12 13 # 提取文件中的数据 转换成矩阵 14 def file2matric(filename): 15 """ 16 disc: 17 param: filename: 导入数据文本 18 return: 数据矩阵 19 """ 20 f = open(filename,'r',encoding= 'utf-8') 21 # 获取文件的行数 22 lines_list = f.readlines() 23 num_of_lines = len(lines_list) 24 # 创建存放标签的列表 25 class_label_list = [] 26 # 生成对应的空矩阵 zeros(2,3) 就是生成2行3列的0矩阵 27 returnMat = np.zeros((num_of_lines,3)) 28 # 将文本中的数据放到矩阵中 29 for i in range(num_of_lines): 30 lines = lines_list[i].strip().split(' ') 31 # 将文本中的前3个数据放到矩阵中 32 returnMat[i,:] = lines[0:3] 33 # 将标签存到列表中 34 class_label_list.append(int(lines[-1])) 35 36 # print(returnMat) 37 return returnMat, class_label_list 38 39 def DrawScatter(dataMat,label_list): 40 # 导入中文字体,及字体大小 41 zhfont = FontProperties(fname='C:/Windows/Fonts/simsun.ttc', size=14) 42 # 绘制绘图窗口 2行2列 43 fig,ax = plt.subplots(2,2,figsize=(13,8)) 44 # 不同标签赋予不同颜色 45 label_color = [] 46 for i in label_list: 47 if i == 1: 48 label_color.append('black') 49 elif i == 2: 50 label_color.append('orange') 51 elif i == 3: 52 label_color.append('red') 53 # 开始绘制散点图 设定散点尺寸与透明度 54 scatter_size = 12 55 scatter_alpha = 0.5 56 # ===================散点图======================== 57 ax[0][0].scatter(dataMat[:,0], dataMat[:,1],color = label_color,s = scatter_size ,alpha = scatter_alpha) 58 ax[0][1].scatter(dataMat[:, 1], dataMat[:, 2], color=label_color, s=scatter_size , alpha=scatter_alpha) 59 ax[1][0].scatter(dataMat[:, 0], dataMat[:, 2], color=label_color, s=scatter_size , alpha=scatter_alpha) 60 61 # 坐标轴标题 62 title_list = ['每年获得的飞行常客里程数和玩视频游戏所消耗时间占比', 63 '每年获得的飞行常客里程数和每周消费的冰激淋公升数', 64 '玩视频游戏所消耗时间占比和每周消费的冰激淋公升数'] 65 x_name_list = ['每年获得的飞行常客里程数','玩视频游戏所消耗时间占比','每周消费的冰激淋公升数'] 66 y_name_list = ['玩视频游戏所消耗时间占比','每周消费的冰激淋公升数','每年获得的飞行常客里程数'] 67 #设置图例 68 didntLike = mlines.Line2D([], [], color='black', marker='.', 69 markersize=6, label='didntLike') 70 smallDoses = mlines.Line2D([], [], color='orange', marker='.', 71 markersize=6, label='smallDoses') 72 largeDoses = mlines.Line2D([], [], color='red', marker='.', 73 markersize=6, label='largeDoses') 74 75 p = 0 76 for i in range(2): 77 for j in range(2): 78 if p > 2: 79 break 80 # 设置坐标轴名称和标题 81 plt.setp(ax[i][j].set_title(u'%s'%(title_list[p]),FontProperties = zhfont),size=9, weight='bold', color='red') 82 plt.setp(ax[i][j].set_xlabel(u'%s'%(x_name_list[p]),FontProperties = zhfont), size=7, weight='bold', color='black') 83 plt.setp(ax[i][j].set_ylabel(u'%s'%(y_name_list[p]),FontProperties = zhfont), size=7, weight='bold', color='black') 84 p+=1 85 # 添加图例 86 ax[0][0].legend(handles=[didntLike, smallDoses, largeDoses]) 87 ax[0][1].legend(handles=[didntLike, smallDoses, largeDoses]) 88 ax[1][0].legend(handles=[didntLike, smallDoses, largeDoses]) 89 plt.savefig('.\123.png', bbox_inches='tight') 90 plt.show() 91 92 # 对矩阵进行归一化处理 93 def dataNorm(dataMat): 94 """ 95 :param dataMat: 96 :return: 归一化后的数据集 97 归一化公式: Y = (X - Xmin)/(Xmax - Xmin) 98 """ 99 # max(0) min(0) 求出每列的最大值和最小值 100 d_min = dataMat.min(0) 101 d_max = dataMat.max(0) 102 # 计算极差 103 d_ranges = d_max - d_min 104 # 创建输出矩阵 105 normDataSet = np.zeros(np.shape(dataMat)) 106 print(normDataSet) 107 # 获得矩阵行数 .shape 获取矩阵的大小 3x3 108 m = dataMat.shape[0] 109 # 计算 (X - Xmin) 这部分 首先要创建Xmin矩阵 将d_min扩展到m行 110 # 需要使用np.tile 函数进行扩展 将d_min扩展成m行1列 变成m x 3 矩阵 111 normDataSet = dataMat - np.tile(d_min,(m,1)) 112 print(normDataSet) 113 # 计算Y 114 normDataSet = normDataSet / np.tile(d_ranges,(m,1)) 115 116 print(normDataSet) 117 return normDataSet 118 119 def classfy_fun(test_data, train_data, labels, k): 120 """ 121 122 :param test_data: 测试集 123 :param train_data: 训练集 124 :param labels: 训练集标签 125 :param k: KNN 算法参数 选择距离最小的个数 126 :return: 分类结果 127 """ 128 # 计算训练集的矩阵行数 129 train_size = train_data.shape[0] 130 # 接下来按照欧氏距离进行元素距离计算 公式 131 # 将测试集扩充成与训练集相同行数 求差 132 diffMat = np.tile(test_data,(train_size,1)) - train_data 133 # 将差值矩阵的每个元素平方 134 sq_diffMat = diffMat**2 135 # 差值平方矩阵每行元素相加 axis = 1 是按行相加 136 sum_diffMat = sq_diffMat.sum(axis = 1) 137 # 对新的求和矩阵进行开方 得到距离值 138 distances = sum_diffMat ** 0.5 139 # 获得距离值中从小到大值的索引 140 sorted_distant = distances.argsort() 141 # 定义一个字典 存放标签 与 出现的数量 142 class_count = {} 143 for i in range(k): 144 # 找出前k个距离值最小的对应标签 145 temp_label = labels[sorted_distant[i]] 146 # 将标签作为 key 存放到字典中 出现次数作为 value 147 class_count[temp_label] = class_count.get(temp_label,0) + 1 148 # 将字典按照value 大小进行排序 149 sort_class_count = sorted(class_count.items(),key = operator.itemgetter(1)) 150 return sort_class_count[0][0] 151 pass 152 # 创建分类器函数 153 def dating_class_test(): 154 155 # 首先获取文件,将文件分成测试集和训练集 156 dating_Mat, dating_label = file2matric('datingdata.txt') 157 # 设置测试集的比例 158 test_ratio = 0.1 159 # 数据归一化 160 normMat = dataNorm(dating_Mat) 161 #获得矩阵的行数 162 m = normMat.shape[0] 163 # 计算测试集的数量 164 numTestData = int(m * test_ratio) 165 # 错误分类的数量 166 error_count = 0.0 167 168 for i in range(numTestData): 169 class_result = classfy_fun(dating_Mat[i,:], dating_Mat[numTestData:m,:], 170 dating_label[numTestData:m],4 ) 171 print("分类结果:%s,实际分类:%s"%(class_result,dating_label[i])) 172 if class_result != dating_label[i]: 173 error_count += 1 174 # print("错误识别的数量:%f" %error_count) 175 print("正确率:%f%% " %((1 - error_count / numTestData)*100)) 176 177 def main(): 178 # reMat, label = file2matric('datingdata.txt') 179 # DrawScatter(reMat,label ) 180 # dataNorm(reMat) 181 # 测试分类情况 182 dating_class_test() 183 pass 184 185 186 if __name__ =='__main__': 187 main()