爬虫的基本流程

1.发送请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体、路由等 2.获取响应内容 如果服务器能正常响应,则会得到一个Response 包含:html页面,json,图片 3.解析内容 解析html数据:正则表达式,第三方解析库如bs4 解析json数据:json模块 解析二进制数据:以b的方式写入文件 4.保存数据 数据库 文件
Request请求
1.请求方式 常用的请求方式:GET,POST 其他请求方式:HEAD,PUT,DELETE,OPTHONS 注意:post和get请求最终都会拼接成这种形式:k1=xxx&k2=yyy post请求的参数放在请求体内: (参数可以放在data中传递) 可用浏览器查看,存放于form data内 get请求的参数直接放在url后面 (把参数放在params中传递) 2.请求头 User-agent:请求头中没有user-agent客户端配置,服务端可能将你作为一个非法用户 host cookies:cookie用来保存登录信息 一般做爬虫都会带上请求头 3.请求体 如果是get方式,请求体没有内容 如果是post方式,请求体是form data,通过浏览器查看
注意:
1.登录窗口,文件上传等信息都会附加到请求体内
2.登录,输入错误的用户密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
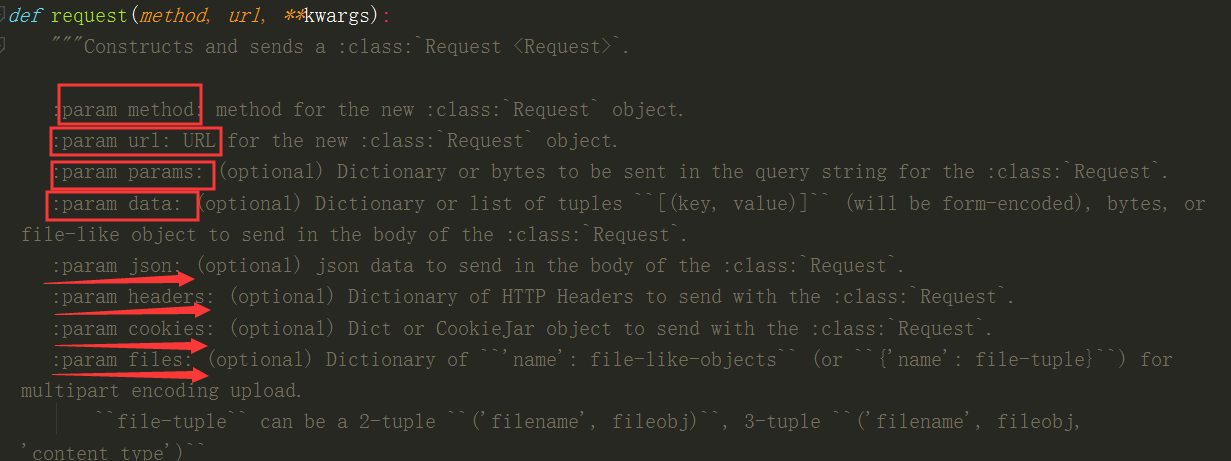
Request源码中显示的可以设置的参数
Response响应
1.响应状态码 200:代表成功 301:代表跳转 404:文件不存在 403:权限 502:服务器错误 2.Response header set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来 3、preview就是网页源代码 最主要的部分,包含了请求资源的内容 如网页html,图片 二进制数据等
总结
1.总结爬虫流程: 爬取--->解析--->存储 2.爬虫所需工具 请求库:request,selenium 解析库:正则,beautifulsoup,pyquery 存储库:文件,MySQL,Mongodb,Redis 3.爬虫常用框架:scrapy