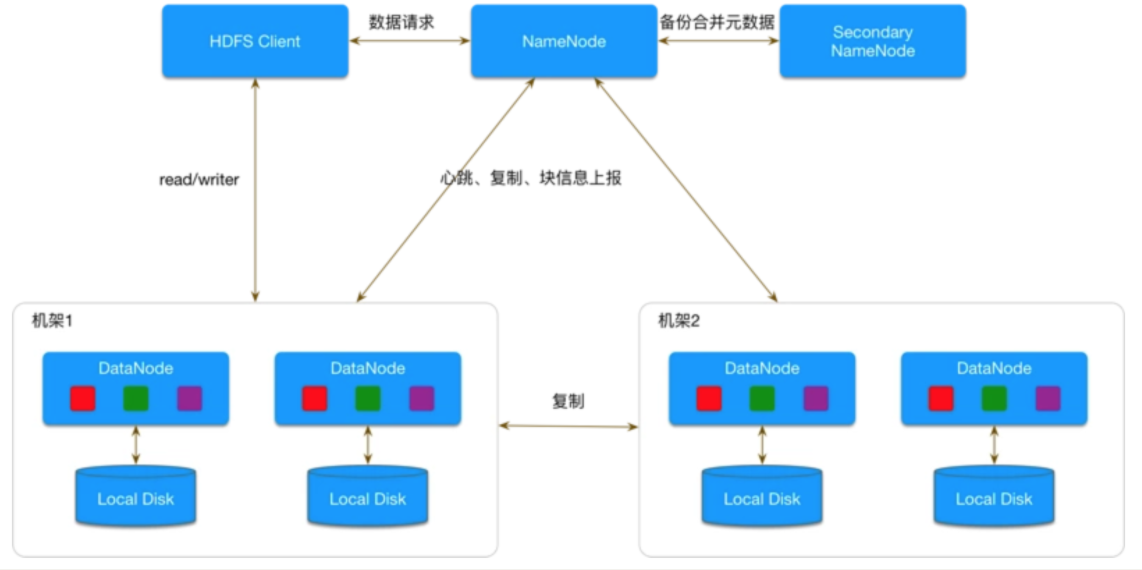
首先,再回顾一下HDFS的架构图
HDFS写数据流程
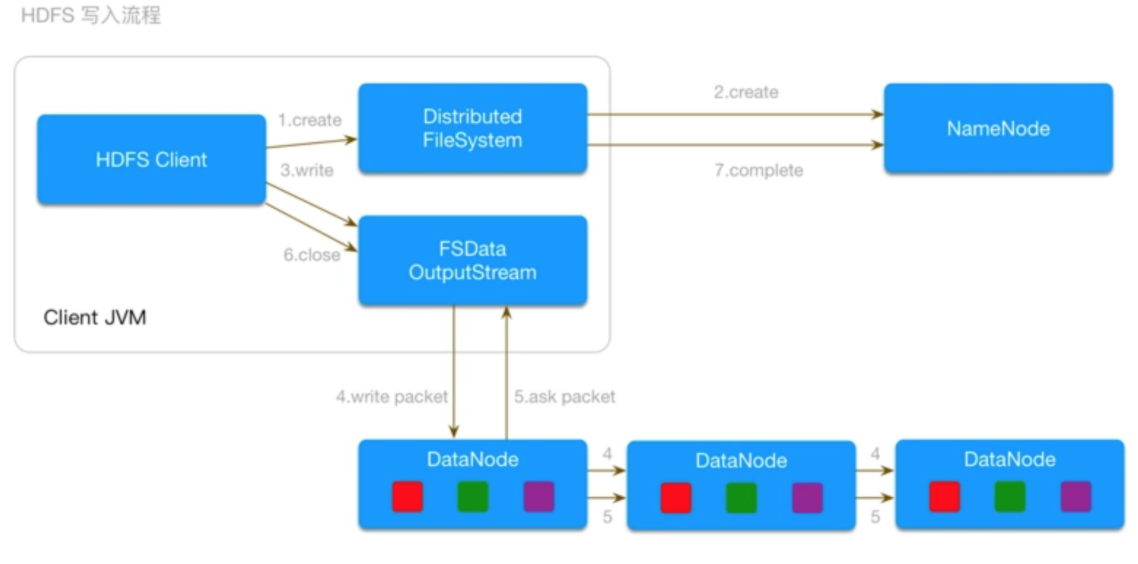
- 客户端发送请求,调用DistributedFileSystem API的create方法去请求namenode,并告诉namenode上传文件的文件名、文件大小、文件拥有者。
- namenode根据以上信息算出文件需要切成多少块block,以及block要存放在哪个datanode上,并将这些信息返回给客户端。
- 客户端调用FSDataInputStream API的write方法首先将其中一个block写在datanode上。
- 每一个block多个副本(默认3个),由已经上传了block的datanode产生新的线程,按照放置副本规则往其它datanode写副本。(并不是由客户端分别往3个datanode上写3份,这样的优势就是快。)
- 写完后返回给客户端一个信息,然后客户端在将信息反馈给namenode。更新元数据。
HDFS读流程
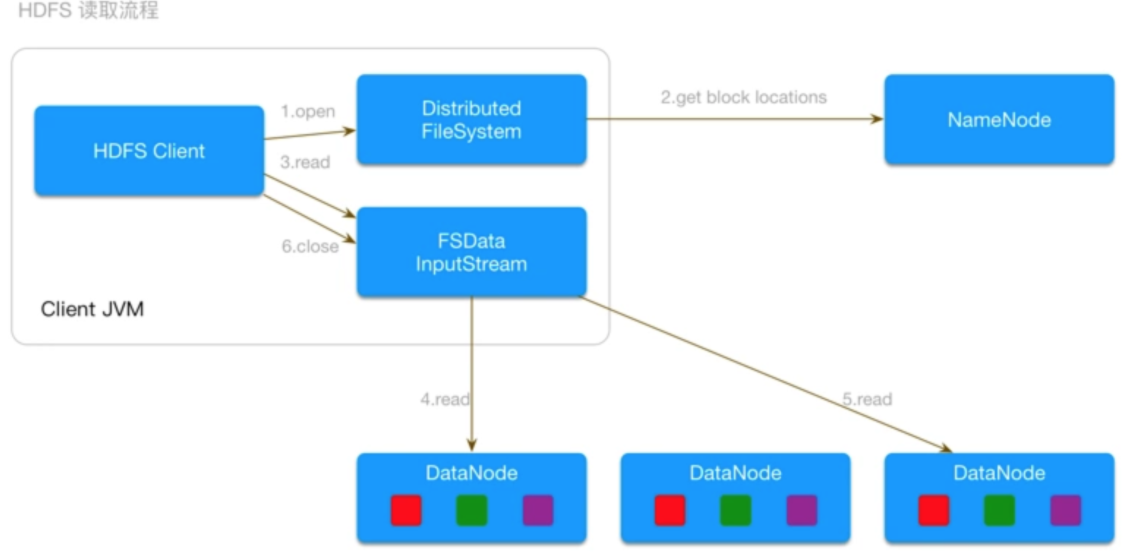
- 客户端通过调用FileSystem对象中的open()方法来读取需要的数据
- DistributedFileSystem会通过RPC协议调用NameNode来查找文件块所在的位置
NameNode只会返回所调用文件中开始的几个块而不是全部返回。对于每个返回的块,都包含块所在的DataNode的地址。随后,这些返回的DataNode会按照Hadoop集群的拓扑结构得出客户端的距离,然后再进行排序。如果客户端本身就是DataNode,那么它就从本地读取文件。其次,DistributedFileSystem会向客户端返回一个支持定位的输入流对象FSDataInputStream,用于给客户端读取数据。FSDataInputStream包含一个DFSInputStream对象,这个对象来管理DataNode和NameNode之间的IO
-
当以上步骤完成时,客户端便会在这个输入流上调用read()方法
-
DFSInputStream对象中包含文件开始部分数据块所在的DataNode地址,首先它会连接文件第一个块最近的DataNode,随后在数据流中重复调用read方法,直到这个块读完为止。
-
当第一个块读取完毕时,DFSInputStream会关闭连接,并查找存储下一个数据块距离客户端最近的DataNode,以上这些步骤对客户端来说都是透明的。
-
当完成所有块的读取时,客户端则会在DFSInputStream中调用close()方法。