人工智能“理解”话语了吗 ——《我们赖以生存的意义》读书笔记(上)
(PS. 本文首发于知乎~ 地址在这)
“这是一本关于你如何理解语言的书。”
前不久花了一周的时间读完《我们赖以生存的意义》(英文名《Louder Than Words》)觉得非常有意思。看完后对关于语言学和认知心理学中一些模糊的问题,尤其“如何理解我们对世界的认知”也有了更清晰的了解。
如今对话机器人已经随处可见,并且随着NLP技术的发展,给用户的感受是越来越“聪明”,也出现了像华智冰这样能“说话”又能“创作”视频、音频、诗词的高级模型。在感慨科技进步的同时,又不乏有“好可怕,AI成精了”之类的评论。所以它们真的理解了那些话语的意义吗?我认为这本书的内容也对如何看待这个问题提供了一定的帮助。
本篇整理了书中许多有趣的内容和大部分实验结论,权当分享和推荐~
一、总述
我们每天都会听到和读到成千上万的字词,很自然地理解这些话描述的是谁、描述了怎样的情况,甚至可以推测和思考出文字中并没有提到的事,并予以恰当的回应。而我们几乎不会留意到自己在做什么。虽然大脑内部持续而不知疲倦地进行着复杂的工作,而就我们主观感受而言,只是顺利而流畅地理解了语言。
我们几乎可以用语言传达我们想表达的任何信息,这是因为人类的语言是开放式的,这一点与只能传达诸如“食物在哪里、敌人来了”之类的动物语言有极大的区别。我们用语言理解世界、与他人互动,甚至三言两语就能改变想法、影响行为。
那么,语言的意义是如何产生和运作的?
为回答这个问题,首先需要解释的是,什么是“意义”?意义的解释有以下两点:
定义本身,用特定语言给出的一段描述
真实世界中的某种事物,也即“心智定义”(mental definition)
举个例子。对于“限速”这个词,它的中文定义是“规定某路段的行车速度范围”,对应于真实世界中,也就是指开车的时候不能开得太快,这时也许会开始想像自己坐在车里小心地驾驶、一边留意着路边限速标志牌的场景,知道如果超速了就可能会面临罚单。这些就是“限速”的意义。
在进一步解释“意义是如何产生的”之前,先来看个小故事:
北极熊爱吃海豹肉,而且爱吃新鲜的。因此,对于一头北极熊来说,学会活捉海豹是非常重要的。若是在陆地上捕猎,北极熊常常会像猫一样跟踪自己的猎物,肚皮贴地快速前行,直到足够逼近,这才一跃而起,伸出爪子,露出獠牙。北极熊几乎可以完美地将自己隐身于冰天雪地的环境中,视觉欠发达的海豹在这方面显然落了下风,但海豹也有它的优势,那就是动作很快。
19世纪遇到过北极熊的水手们都说,他们发现北极熊会做一件非常聪明的事来提高自己活捉一头海豹的胜算。根据他们的说法,当北极熊悄然逼近自己的猎物时,它们会用爪子遮住自己的鼻头,这会让它们变得更不易被察觉。也就是说,北极熊在捕猎时会捂住自己的鼻子。
阅读这段话时,你在做什么呢?
你把目光聚焦在每一个字上,这些字又组成了词,你认出了一些熟悉的词,比如“熊”和“海豹”,或者“捕猎”和“雪”。
在你的脑海中,那些句子描述的画面变得生动起来:一头北极熊正肚皮贴地,蹑手蹑脚地爬过雪地,一边机智而又看起来有点诡异地用爪子捂住自己的鼻子。如果想象得再深入一些,你甚至可以在自己的脑海中“看”到发生在北极的这一幕。
随着进一步理解,你还会补上那些从未在句子里明确提到的细节,推理出为什么北极熊会遮掩它们黑色的鼻头——为了让自己和雪的颜色融为一体,因此把不是白色的地方遮住。
所以我们是怎么做到理解这段文字的?
思想语言假说认为,对于我们已经知道的每一个词,我们都在头脑中为它设立了一个条目,可以清晰地用思想语言来描述它的定义。这是当下关于意义与心智已经达成的最重要、也最有影响力的思想之一。
这个意思也就是说,我们头脑中有一大堆编码,运作起来仿佛像是指针一样,每个语言文字都有对应的编码,而这个编码又指向了某个现实事物。比如“北极熊”这个中文单词,对应着脑海中一个或许叫“9us&”的神奇编码,它指的是那些白色的毛茸茸的北极熊。
但这就有个问题。思想语言,也就是这组编码单词是从哪里来的?换句话说,我们是怎么知道思想语言里各词的意思的?如果思想语言是在我们学习语言时习得的,但明明又要用思想语言来理解语言,这形成了悖论;如果不是在学习语言时习得,这说明所有不同语言的人生下来脑海里就有这一套相同的编码体系?似乎也不太合理。
另一个问题是,就算我们用这套思想语言编码识别并排列出了能够正确表达的语言,这能代表理解了意义吗?
假设你坐在一个密闭房间里,有人从门缝里塞进来一张卡片,上面写的是中文,而你恰巧对中文一窍不通。于是你翻开一本经过精心设计的书,这本书在你要查的每一个汉字旁边都有另外一些汉字。你照着抄下这一堆汉字,写在卡片上从门缝传了出去。因为你不懂中文,所以你对这张卡片上写了什么一无所知,但房间外面的人是懂中文的,他们看到卡片上用中文组织的句子正确地回答了字条上的内容,就会认定房间里一定有一个精通中文的人。那么问题是:这可以证明你懂中文吗?在这个例子里,汉字就好比思想语言的单词,仅仅是正确识别并组织排列了某种语言的字符并不足以生成意义,哪怕这些字符确实是指代存在于真实世界中的事物,这并不能证明你理解了这一事物。
与思想语言假说对立抗衡的另一观点是具身模拟假说。这一假说认为,我们对语言的理解就是通过在我们的脑海中进行模拟,感受这些语言所描述的事物若换成我们自己亲身去体验会是怎样的。并且,用于生成意义的大脑部位也恰巧就是用于感知和完成具体动作的部位。
这些模拟体验包括了视觉、听觉、味觉、嗅觉等等,比如我们可以想象出亲人的面容、歌曲的旋律、蛋糕的味道、薰衣草的香气,以及站在家门前掏出钥匙转动门把的一系列场景和动作。按照具身模拟假说,意义不只是抽象的心理符号,还是一种创作过程,也就是在脑海中构建虚拟体验,通过模拟画面、声音和动作来生成意义。
也就是说,我们对意义的感知能力其实是基于其他系统的。虽然视觉、听觉这些感知和运动系统并不是人类所独有,但与其他物种所不同的是,我们能够用特殊的方式去使用这些系统。因此,理解意义是如何运作的,才得以理解我们“何以为人”。
书中详细描述了大量实验,用以证明具身模拟假说的正确性,而其中许多实验结果都是用思想语言假说无法解释的。本文不在此具体介绍实验,仅做一篇结论整理。
二、具身模拟,构建心理意象
我们知道,对于篮球、网球等诸多运动,一般来说,训练得越多则表现得越好。比如,想要提高投篮水平,那就先投个几千个球再说吧,正所谓熟能生巧。然而实地训练又有着成本高、过度训练会导致运动员身体受伤等问题。于是20世纪80年代的球类运动教练琢磨出一个新方法:别打球了,就地躺下,开始默想。
试一试闭上眼睛,想象自己是如何调动身体做出一连串动作完成投球的。神奇的是,默想之后的球员真的会比没有做默想的人更有可能投出一个好球。这种想象也被称作“心理意象”“可视化默想”或“心理彩排”。现在,默想已经成为体育心理学的一个标准组成部分。
当我们开始默想动作,并有意识、有目的地启动心理意象时,实则正是在调用大脑深处那些用于实际操控身体完成相应动作的部位。当默想手持篮球的时候,大脑中负责控制手部动作的部位也会忙碌起来。也就是说,想象完成动作的时候,大脑所做的工作就跟在现场练习时做的工作是一样的。唯一的区别只是在于,想象时的大脑活跃水平比起真正运动时的略低,像是行动的一道浅淡的影子。即使躺下默想的人一动不动,运动皮层也是处于激活状态的,只是负责动作协调的小脑没有活跃起来,因此身体没有动。
除了运动想象之外,还有听觉想象、味觉想象、体觉想象(比如皮肤受到挤压的感觉)等等,都分别动用了大脑用于感知画面、声音、气味、触感的不同部位。
然而,心理意象也不都是好事,它能够干扰或加强我们对世界的实际感知,这就是“派基效应”。比如你在教室上课的时候饿了,开始想象家里饭桌上摆着一顿丰盛的晚餐,于是可能就看不到黑板上写了什么。这时候如果是在开车,也可能会看不到路况也注意不到旁边的车辆。这表明想象是会干扰视觉的。我们会将真实看见的东西和在大脑中构建的视觉想象混为一谈,或者将两者整合。
不过,想象也还是非常有用。古希腊人有一种“轨迹记忆法”。假设我们要记下以下这串词“水、画、刀、森林、心脏、咖啡、船、鼻子”。当然,可以选择死记硬背直到滚瓜烂熟。但如果用轨迹记忆法是这样记的:想象你在一个熟悉的环境里沿着一个既定路线移动,一边走时一路看到这些物品。比如你进了家门,在桌上看见一杯水,然后走到客厅看到墙上的画,又走到厨房看到一把刀……如果物体和位置的联系安排清晰,能够很真切想象得出来,就会很容易记住,这也是得益于大脑对想象的机制和行动的感知是一样的。
三、心智之眼,视觉与理解
如果我说:“别想那只大象。”
这时候你在想什么?是不是仿佛看到了一只大耳朵长鼻子的...大象。
视觉是我们收集信息的最主要方式,与头脑内活动的联系也最为紧密。只要一提到某个物体,就会不自觉在脑海中唤起一个相应的视觉模拟。这是因为,我们需要用视觉系统来理解关于可见事物的语言。
那么视觉系统的工作方式是怎样的呢,换句话说,大脑是如何处理“看到”的?
当睁开双眼,视觉信号从眼睛到达大脑后部的初级视觉皮层。在这里,视线中的物体的不同属性被区别开,汇入不同的信息流,分别向两个方向进行激活:辨认看到的是什么的“什么”路径、辨认具体处于什么方位的“哪里”路径。
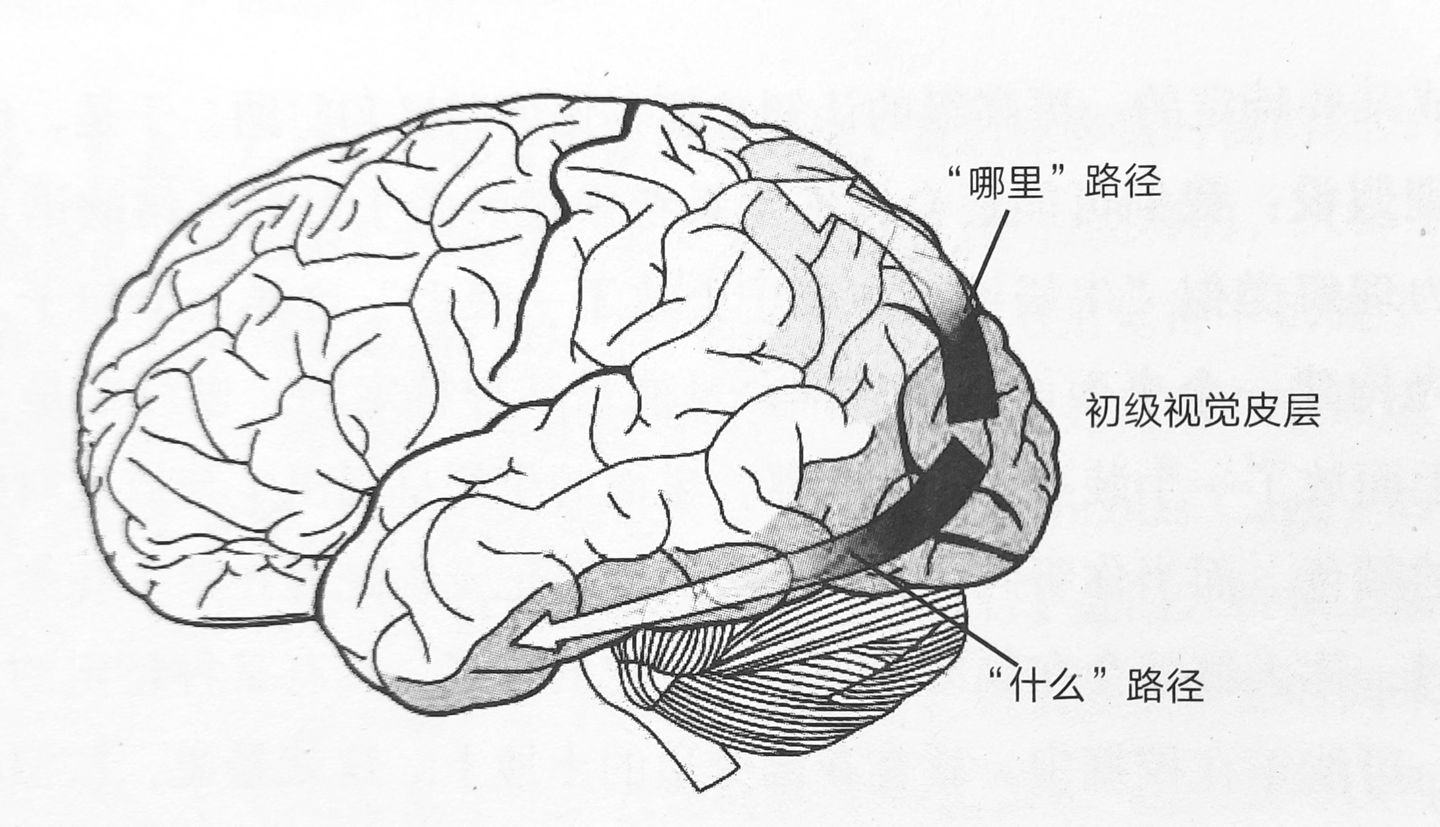
视觉系统的工作方式:“是什么”“在哪里”
在理解文字时,会对句中提到的物体自动构建带有可感知细节的视觉具身模拟。包括物体的放置朝向(“把钉子敲在墙上”“把钉子敲到地面”)、外形(“鹰在巢里”“鹰在天上”)、颜色(“天晴时的天空”“暴雨时的天空”),这是由“什么”路径处理得到的;以及方位(“房间角落的柜子”“客厅中间的皮球”)、往哪个方向运动(“山羊在攀登”“降落伞从天而降”),这是“哪里”路径负责处理的。有趣的是,在理解关于运动的文字时也会真实发生眼动。
我们对意义的理解至少有一部分发生在脑海中的心智之眼,每当听说或读到这些句子的时候,就会以沉浸式体验者视角在脑海里心理模拟这些物体或场景,从而“看”到那些细节。
四、多模态视角
来看看这份稳赢掰手腕比赛的绝招:
首先,把胳膊肘尽量往前靠,朝向你的对手,这么做能让你的前臂伸得更直,这样一来你的手就会高出对手一点点,而因此获得杠杆优势。接着,在你伸手去握对方的手时,不要用你的大拇指环绕对方手掌根部,而要沿着对方手的方向再往上握一点,把对方的大拇指抓在手里。开始掰手腕时,将手腕向自己这边掰,这会让对方的手向后翻,从而带给你更大的杠杆优势。这样,你就有机会战胜比你强壮的对手了。
不知道你在阅读这些文字时是否也像我一样,凭空想象了老半天,甚至把手搁在桌面上试了下,试图记下来以后备用。
所以我们是如何做到在看到字句后将其转化为调用身体完成动作的指令的?而且即便这些文字描述省略了大量了细节,我们也能够通过推理补充,意识到自己大概要怎么做才能完成动作。
这是由于,我们在理解语言的过程中会以沉浸式体验者视角在脑海里创建场景,不仅限于视觉,而是多模态的,以被描述的视角做运动模拟,进而感受自己做起来大概是什么情况。
人体的不同部位是由大脑内不同区域的神经元负责控制的,做不同的动作会激发不同部位的神经元。并且,当看到他人做动作时,也会激发负责做该动作的神经元,只是激活的程度更低。

处理关于不同部位的句子时,大脑激活的区域
我们通过运动模拟来理解关于肢体动作的语言,这个过程用到的就是实际在做这些动作时负责协调和执行的大脑系统。正由于是同一套系统,所以能够辨认、预测和理解他人的肢体动作。因此也带来了“兼容问题”,也就是说,在做某个动作时要做到理解需要用到同个身体部位的语句会变得更困难。比如,试一试在说话的时候想象咀嚼、在开车向右打方向盘的时候想象投篮。忙碌的动作占用了同一片区的系统,想象这个动作变得比不做动作时困难了。但是一边开车一边吹口哨、一边看这篇文章一边抖腿,都非常的轻松自如。
也因为多模态的体验便于我们理解语言的意思,我们对现实中更容易交互的物品的词语,比更不容易交互的词语理解起来更快。比如理解“腰带、盘子、葡萄”这样的词语,会比“云朵、洪水、池塘”更迅速。
五、语法的作用
某位在玩《吃豆人》游戏的朋友突然说道,“那个蓝色的怪就要抓住我的吃豆人了!”知道这个游戏的你很容易就理解听懂了。如果他说的是“那个我的就要吃豆人抓住蓝色的怪了”,你一定十分摸不着头脑。
我们已经知道,大脑能通过“是什么”和“在哪里”路径来认知语言中描述的物体在颜色、外形、位置、运动状态的具体表征。但句中哪个状态描述的是哪个不同物体,也即“捆绑问题”是怎么被解决呢?比如在这句话中,我们知道“吃豆人”是被抓的那一方、“怪”是抓人的那一方、“蓝色”指的是怪而不是吃豆人。
原因是,前面那句话使用了正确的语法。
句子就像一棵植物:字词是饱满的叶子,作为功能单元;而语法是由枝干构成的支撑框架,使叶子各得其所。如此这般将信息用正确的方式整合到了一起。
正如前面所说,语法的一个功能就是将单词按照规则正确地组织起来。这类关于“句子的整体结构怎样规划某个主体在某个事件里扮演什么角色”的知识,在语言学中叫作论元结构构式。在上述例子中,就是一种及物构式:名词短语1 - 动词 - 名词短语2,代入就是“蓝色的怪 - 就要抓住 - 我的吃豆人”。再比如,还有双宾语构式的句子结构,名词短语1 - 动词 - 动词短语2 - 名词短语3,可以代入“防守员 - 踢给 - 己方守门员 - 球”。
此外,语法的第二个功能是表达句子意义。比如,在一些句式可用于推理句中动词的意义。举例而言,对于句子“Lyn crutch her apple so Tom would not starve.”和“Lyn crutch Tom her apple so he would not starve.”里的“crutch(拐杖)” 一般作为名词,在这里做动词。前一句的“crutch”表达了对宾语苹果施加动作的意思,可能是指用拐杖戳开苹果成两半;而后者表达的是持有物转交,也就是把苹果用拐杖叉给Tom。两个句子的组成成分一样,区别只是在于前一个句子是及物构式,而后者是双宾语构式。由此可见,不同的语法构式本身也贡献了一定的意义。
语法的第三个功能是调节具身模拟的方式。我们已经知道,对于描述不同名词短语的句子,我们会对此有着不同的具身模拟。比如对“司机焦急地等着红绿灯”我们会采用旁观者视角,仿佛看到一辆汽车停在十字路口的画面。而句子“你焦急地等着红绿灯”,我们会采用参与者视角,仿佛坐在车里的驾驶座上透过玻璃看着前方的路口。实际上,除此之外,不同的语法催生的具身模拟也有区别。它提示的不是“什么需要模拟”,而是“如何进行模拟”。例如“约翰在关抽屉”和“约翰关上了抽屉”,前者采用进行时的句子里,具身模拟倾向于注意动作发生的过程,而后者采用完成时,我们会更多地关注到结束状态。