Hadoop-HA机制
HA概述
high available(高可用)
所谓HA(high available),即高可用(7*24小时不中断服务)。
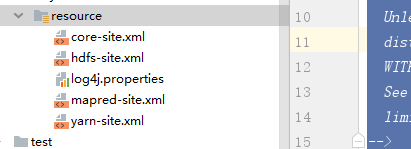
实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
高可靠:hdfs多个副本
最大的作用解决:单点故障存在的问题
单点故障原因:
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
NameNode故障解决
HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器
HA的运作机制(重点)
涉及组件:
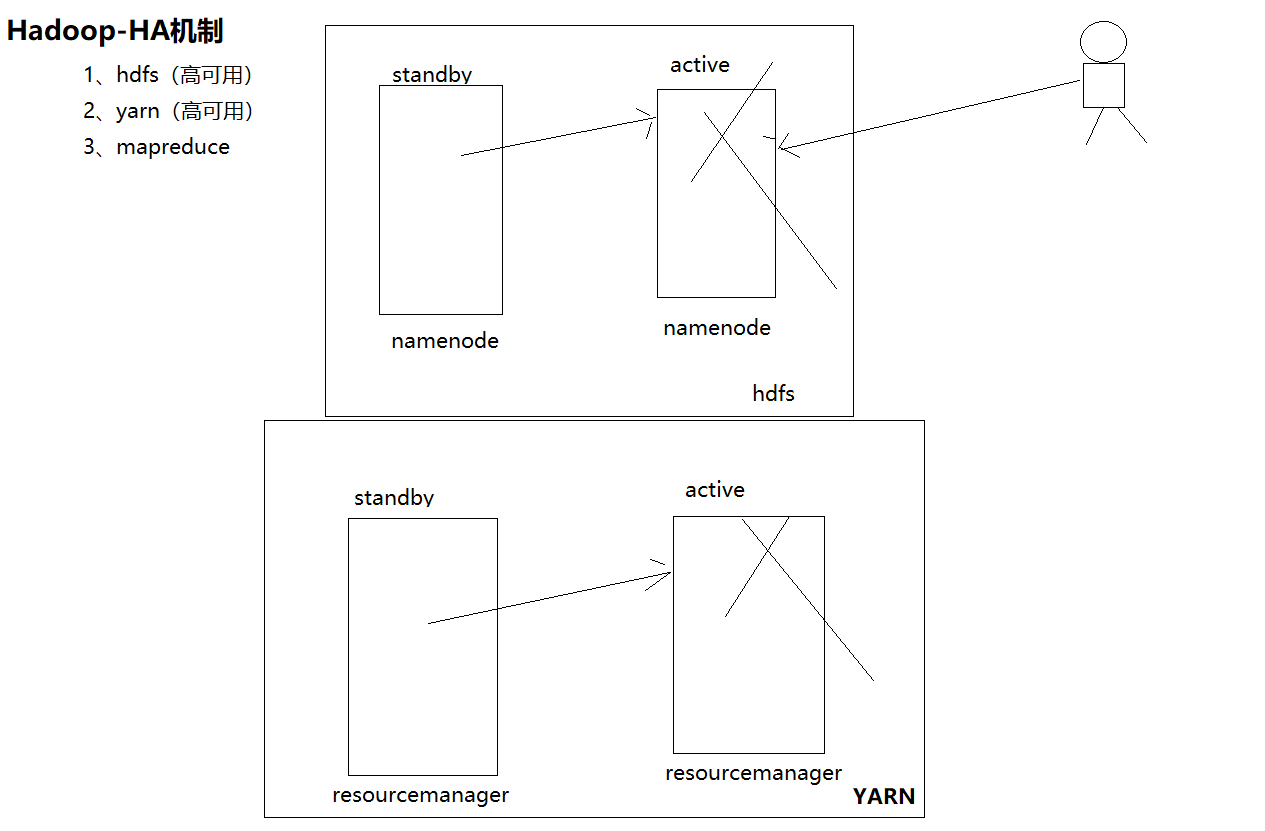
1、zookeeper:协调主备namenode的切换
2、qjournal:主备namenode的数据同步
3、zkfc:它zookeeper的客户端应用,主要检测namenode的健康状态
4、active namenode:激活的namenode
5、standby namenode:备用的namenode
HDFS-HA工作要点
元数据管理方式需要改变
需要一个状态管理功能模块
必须保证两个NameNode之间能够ssh无密码登录。
隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
元数据管理方式
内存中各自保存一份元数据
Edits日志只有Active状态的namenode节点可以做写操作
两个namenode都可以读取edits
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,
利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生
故障转移工作机制
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程。
Zookeeper作用
故障检测
集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
现役NameNode选择
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
健康监测
active选择
jdbcClient访问Ha集群环境
package com.gec.demo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class HdfsClientApp { public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException { Configuration configuration=new Configuration(); FileSystem fileSystem= FileSystem.get(new URI("hdfs://bi/"),configuration,"hadoop"); // 2 把本地文件上传到文件系统中 fileSystem.copyFromLocalFile(new Path("D:/hello.txt"), new Path("/hello1.copy.txt")); // 3 关闭资源 fileSystem.close(); } }
注意要将以下配置文件copy到resource文件夹中。否则会报错!!!