为何需要分布式锁
Martin Kleppmann 是英国剑桥大学的分布式系统的研究员,之前和 Redis 之父 Antirez 进行过关于 RedLock(红锁,后续有讲到)是否安全的激烈讨论。
Martin 认为一般我们使用分布式锁有两个场景:
- 效率:使用分布式锁可以避免不同节点做了重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
分布式锁的一些特点
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点?
分布式锁的特点如下:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
常见的分布式锁
我们了解了一些特点之后,我们一般实现分布式锁有以下几个方式:
- MySQL
- ZK
- Redis
- 自研分布式锁:如谷歌的 Chubby。
下面分开介绍一下这些分布式锁的实现原理。
MySQL
首先来说一下 MySQL 分布式锁的实现原理,相对来说这个比较容易理解,毕竟数据库和我们开发人员在平时的开发中息息相关。
对于分布式锁我们可以创建一个锁表:
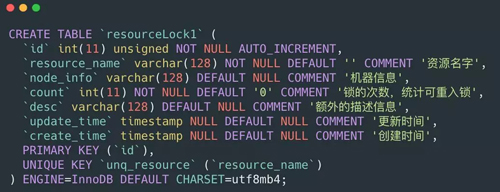
这个锁的数据结构主要是唯一键resource_name(机器ip+线程名)和count(统计可重入锁)。
前面我们所说的 lock(),trylock(long timeout),trylock() 这几个方法可以用下面的伪代码实现。
lock()
lock 一般是阻塞式的获取锁,意思就是不获取到锁誓不罢休,那么我们可以写一个死循环来执行其操作:

mysqlLock.lcok 内部是一个 sql,为了达到可重入锁的效果,我们应该先进行查询,如果有值,需要比较 node_info (某个节点的信息)是否一致。
这里的 node_info 可以用机器 IP 和线程名字(因为同一个服务器节点,它的多线程之间也存在竞争锁)来表示,如果一致就增加可重入锁 count 的值,如果不一致就返回 false。如果没有值就直接插入一条数据。
伪代码如下:
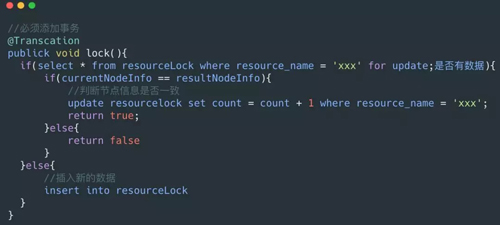
需要注意的是这一段代码需要加事务@Transaction,必须要保证这一系列操作的原子性。
tryLock() 和 tryLock(long timeout)
tryLock() 是非阻塞获取锁,如果获取不到就会马上返回,代码如下:

tryLock(long timeout) 实现如下:
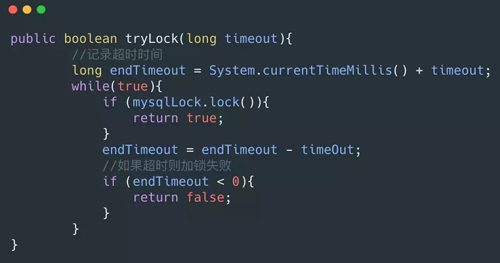
mysqlLock.lock 和上面一样,但是要注意的是 select … for update 这个是阻塞的获取行锁,如果同一个资源并发量较大还是有可能会退化成阻塞的获取锁。
unlock()
unlock 的话如果这里的 count 为 1 那么可以删除,如果大于 1 那么需要减去 1。可重入锁的值。

锁超时
我们有可能会遇到我们的机器节点挂了,那么这个锁就不会得到释放,我们可以启动一个定时任务,通过计算一般我们处理任务的时间。
比如是 5ms,那么我们可以稍微扩大一点,当这个锁超过 20ms 没有被释放我们就可以认定是节点挂了然后将其锁直接释放。
MySQL 小结:
- 适用场景:MySQL 分布式锁一般适用于当资源不存在数据库中;如果存在于数据库中比如订单,可以直接对这条数据加行锁,不需要我们上面多的繁琐的步骤;比如一个订单,我们可以用 select * from order_table where id = 'xxx' for update 进行加行锁,那么其他的事务就不能对其进行修改;这是悲观锁。
- 优点:理解起来简单,不需要维护额外的第三方中间件(比如 Redis,ZK)。
- 缺点:虽然容易理解但是实现起来较为繁琐,需要自己考虑锁超时,加事务等等。性能局限于数据库,一般对比缓存来说性能较低。对于高并发的场景并不是很适合。
乐观锁
前面我们介绍的都是悲观锁,这里想额外提一下乐观锁,在我们实际项目中也是经常实现乐观锁,因为我们加行锁的性能消耗比较大,通常我们对于一些竞争不是那么激烈。
但是其又需要保证我们并发的顺序执行使用乐观锁进行处理,我们可以对我们的表加一个版本号字段。
那么我们查询出来一个版本号之后,update 或者 delete 的时候需要依赖我们查询出来的版本号,判断当前数据库和查询出来的版本号是否相等,如果相等那么就可以执行,如果不等那么就不能执行。
这样的一个策略很像我们的 CAS(Compare And Swap),比较并交换是一个原子操作。这样我们就能避免加 select * for update 行锁的开销。