【Game Engine Architecture 6】
1、Data-Parallel Computations
A GPU is a specialized coprocessor designed specifically to accelerate those computations that involve a high degree of data parallelism. It does so by combining SIMD parallelism (vectorized ALUs) with MIMD parallelism (by employing a form of preemptive multithreading). NVIDIA coined the term single instruction multiple thread (SIMT) to describe this SIMD/MIMD hybrid design, all GPUs employ the general principles of SIMT parallelism in their designs.
In order for a computational task to be well-suited to execution on a GPU, the computations performed on any one element of the dataset must be independent of the results of computations on other elements.


void DotArrays_ref(unsigned count, float r[], const float a[], const float b[]) { for (unsigned i = 0; i < count; ++i) { // treat each block of four floats as a // single four-element vector const unsigned j = i * 4; r[i] = a[j+0]*b[j+0] // ax*bx + a[j+1]*b[j+1] // ay*by + a[j+2]*b[j+2] // az*bz + a[j+3]*b[j+3]; // aw*bw } }
Upper code, the computation performed by each iteration of this loop is independent of the computations performed by the other iterations.
2、Compute Kernels
GPGPU compute kernels are typically written in a special shading language which can be compiled into machine code that’s understandable by the GPU. Some examples of shading languages include DirectX’s HLSL (high-level shader language), OpenGL’s GLSL, NVIDIA’s Cg and CUDA C languages, and OpenCL.
Some shading languages require you to move your kernel code into special source files, separate from your C++ application code. OpenCL and CUDA C, however, are extensions to the C++ language itself.
OpenCL、CUDA C 扩展了 C++,使得可以在C++文件中编写 kernel函数。
As a concrete example, here’s our DotKernel() function written in CUDA C:
__global__ void DotKernel_CUDA(int count, float* r, const float* a, const float* b) { // CUDA provides a magic "thread index" to each // invocation of the kernel -- this serves as // our loop index i size_t i = threadIdx.x; // make sure the index is valid if (i < count) { // treat each block of four floats as a // single four-element vector const unsigned j = i * 4; r[i] = a[j+0]*b[j+0] // ax*bx + a[j+1]*b[j+1] // ay*by + a[j+2]*b[j+2] // az*bz + a[j+3]*b[j+3]; // aw*bw } }
You’ll notice that the loop index i is taken from a variable called threadIdx within the kernel function itself. The thread index is a “magic” input provided by the compiler, in much the same way that the this pointer “magically” points to the current instance within a C++ class member function.
3、Executing a Kernel
here’s how we’d kick off our compute kernel in CUDA C:
void DotArrays_gpgpu2(unsigned count, float r[], const float a[], const float b[]) { // allocate "managed" buffers that are visible // to both CPU and GPU int *cr, *ca, *cb; cudaMallocManaged(&cr, count * sizeof(float)); cudaMallocManaged(&ca, count * sizeof(float) * 4); cudaMallocManaged(&cb, count * sizeof(float) * 4); // transfer the data into GPU-visible memory memcpy(ca, a, count * sizeof(float) * 4); memcpy(cb, b, count * sizeof(float) * 4); // run the kernel on the GPU DotKernel_CUDA <<<1, count>>> (cr, ca, cb, count); // wait for GPU to finish cudaDeviceSynchronize(); // return results and clean up memcpy(r, cr, count * sizeof(float)); cudaFree(cr); cudaFree(ca); cudaFree(cb); }
cudaDeviceSynchronize():// wait for gpu to finish
cudaMallocManaged()://allocate "managed" buffers that are visible to both CPU and GPU
cudaFree():// free memory from cudaMallocManaged
The first argument G in the angled brackets tells the driver how many thread groups (known as thread blocks in NVIDIA terminology) to use when running this compute kernel. A compute job with a single thread group is constrained to run on a single compute unit on the GPU. A compute unit is esssentially a core within the GPU—a hardware component that is capable of executing an instruction stream. Passing a larger number for G allows the driver to divide the workload up across more than one compute unit.
4、GPU Threads and Thread Groups
a thread group is comprised of some number of GPU threads. a GPU is comprised of multiple compute units, each of which contains some number of SIMD units.
GPU 由 compute unit 组成,每个 compute unit 包含一些 SIMD units。compute unit 可以想象成 cpu core,拥有一些vpu(SIMD)。
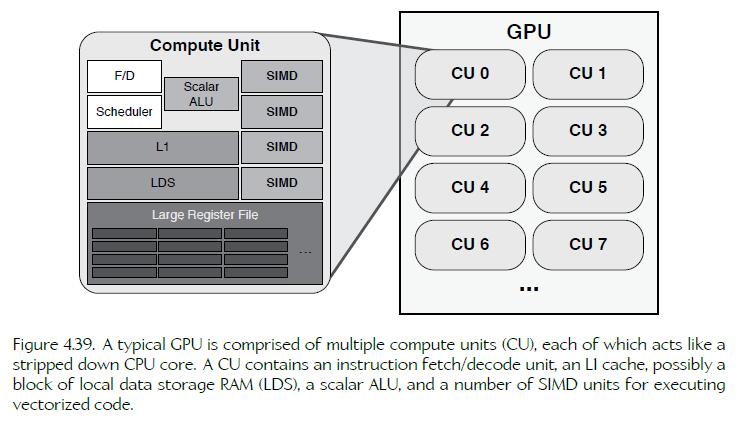
For example, SIMDs may 16 lanes wide.
The CU is not capable of speculative or out-of-order execution—it simply reads a stream of instructions and executes them one by one, using the SIMD units to apply each instruction to 16 elements of input data in parallel.
To execute a compute kernel on a CU, the driver first subdivides the input data buffers into blocks consisting of 64 elements each. For each of these 64-element blocks of data, the compute kernel is invoked on one CU. Such an invocation is called a wavefront (also known as a warp in NVIDIA speak). When executing a wavefront, the CU fetches and decodes the instructions of the kernel one by one. Each instruction is applied to 16 data elements in lock step using a SIMD unit. Internally, the SIMD unit consists of a four-stage pipeline, so it takes four clock cycles to complete. So rather than allow the stages of this pipeline to sit idle for three clock cycles out of every four, the CU applies the same instruction three more times, to three more blocks of 16 data elements. This is why a wavefront consists of 64 data elements, even though the SIMDs in the CU are only 16 lanes wide.
the term “GPU thread” actually refers to a single SIMD lane. You can think of a GPU thread, therefore, as a single iteration of the original nonvectorized loop that we started with, before we converted its body into a compute kernel. Alternatively, you can think of a GPU thread as a single invocation of the kernel function, operating on a single input datum and producing a single output datum.
a GPU thread 可想象成迭代次数或 kernel 调用次数。
5、From SIMD to SIMT
SIMT a form of preemptive multithreading to time-slice between wavefronts. any one instruction in the program might end up having to access memory, and that introduces a large stall while the SIMD unit waits for the memory controller to respond.
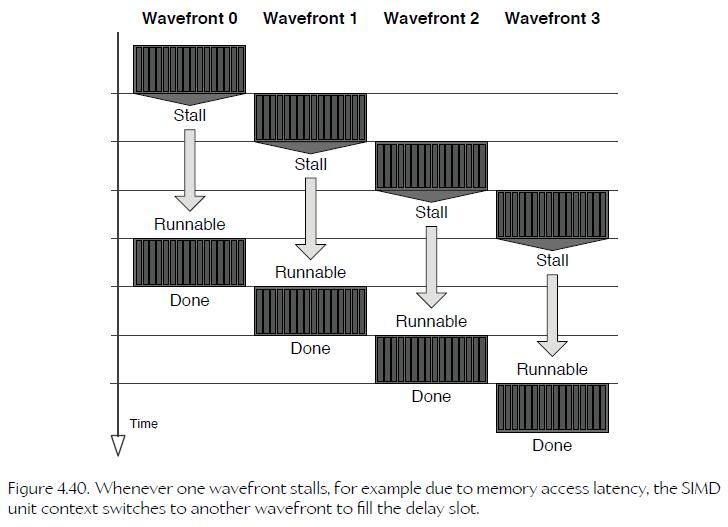
To eliminate the cost of saving registers during context switches, each SIMD unit contains a very large register file. The number of physical registers in this register file is many times larger than the number of logical registers available to any one wavefront (typically on the order of ten times larger).
This means that the contents of the logical registers for up to ten wavefronts can be maintained at all times in these physical registers. And that in turn implies that context switches can be performed between wavefronts without saving or restoring any registers whatsoever.
每个 SIMD 的 register file 拥有十倍于 logic register 的 physical register,所以 SIMD 在切 context 时,根本不需要 saving or restoring registers。
6、Cylindrical coordinates
This system employs a vertical “height” axis h, a radial axis r emanating out from the vertical, and a yaw angle theta (q). In cylindrical coordinates, a point P is represented by the triple of numbers (Ph, Pr, Pq).

7、Left-Handed versus Right-Handed Coordinate Systems
It is easy to convert from left-handed to right-handed coordinates and vice versa. We simply flip the direction of any one axis, leaving the other two axes alone.
8、Dot Product and Projection
• the dot product (a.k.a. scalar product or inner product), and
• the cross product (a.k.a. vector product or outer product).
The dot product is commutative (i.e., the order of the two vectors can be reversed) and distributive over addition:
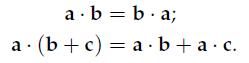
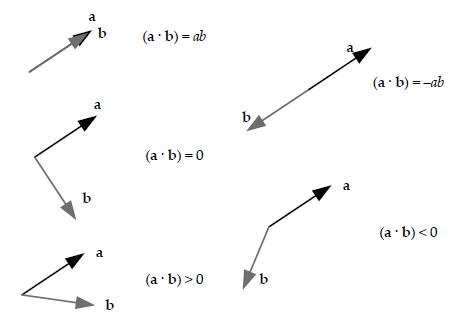
For any two arbitrary vectors a and b, game programmers often use the following tests, as shown in Figure 5.11:
• Collinear. (a b) = |a| |b|= ab (i.e., the angle between them is exactly 0 degrees—this dot product equals +1 when a and b are unit vectors).
• Collinear but opposite. (a b) = -ab (i.e., the angle between them is 180 degrees—this dot product equals +1 when a and b are unit vectors).
• Perpendicular. (a b) = 0 (i.e., the angle between them is 90 degrees).
• Same direction. (a b) > 0 (i.e., the angle between them is less than 90 degrees).
• Opposite directions. (a b) < 0 (i.e., the angle between them is greater than 90 degrees).
点到平面的高度:

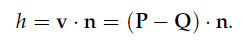
9、Cross Product
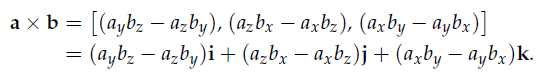
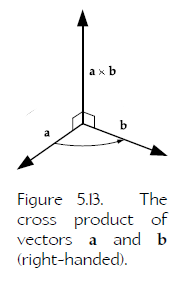

When converting from a right-handed system to a left-handed system or vice versa, the numerical representations of all the points and vectors stay the same, but one axis flips.
左右手坐标系下,cross product 的数值相同,只是表现上会轴相反。
Properties of the Cross Product:

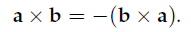

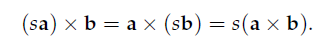
The Cartesian basis vectors are related by cross products as follows:
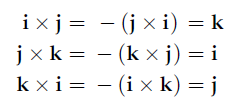
10、Pseudovectors and Exterior Algebra,伪矢量,外代数
cross product doesn’t actually produce a vector—it produces a special kind of mathematical object known as a pseudovector. The surface normal of a triangle (which is calculated using a cross product) is also a pseudovector
exterior algebra or Grassman algebra, which describe how vectors and pseudovectors work and allow us to calculate areas of parallelograms (in 2D), volumes of parallelepipeds (in 3D), and so on in higher dimensions.
Grassman algebra is to introduce a special kind of vector product known as the wedge product, denoted A^ B. A pairwise wedge product yields a pseudovector and is equivalent to a cross product, which also represents the signed area of the parallelogram formed by the two vectors.
Doing two wedge products in a row, A ^ B ^ C, is equivalent to the scalar triple product A (B xC) and produces another strange mathematical object known as a pseudoscalar. which can be interpreted as the signed volume of the parallelepiped
formed by the three vectors.
11、Linear Interpolation of Points and Vectors
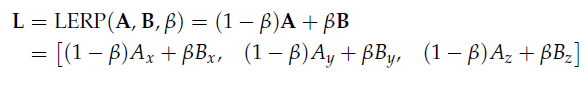
12、Matrices
An affine matrix is a 4x4 transformation matrix that preserves parallelism of lines and relative distance ratios, but not necessarily absolute lengths and angles. An affine matrix is any combination of the following operations: rotation,
translation, scale and/or shear.
13、Matrix Multiplication
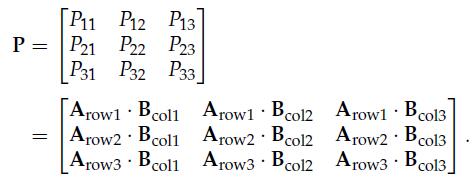
Matrix multiplication is not commutative. In other words, the order in which matrix multiplication is done matters:
14、Representing Points and Vectors as Matrices
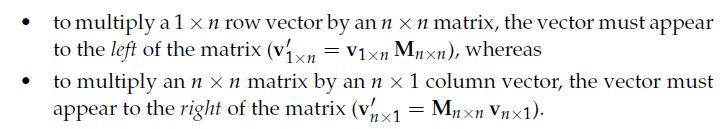
15、Matrix Inversion
The inverse of a matrix A is another matrix (denoted A^-1) that undoes the effects of matrix A.
all affine matrices (combinations of pure rotations, translations, scales and shears) do have inverses.

16、Transposition
the inverse of an orthonormal (pure rotation) matrix is exactly equal to its transpose.

17、Homogeneous Coordinates

When a point or vector is extended from three dimensions to four in this manner, we say that it has been written in homogeneous coordinates. A point in homogeneous coordinates always has w = 1.
18、Transforming Direction Vectors
homogeneous (four-dimensional) coordinates can be converted into non-homogeneous (three-dimensional) coordinates by dividing the x, y and z components by the w component:

19、Atomic Transformation Matrices
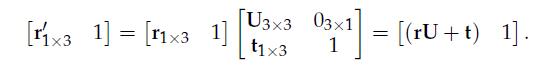
20、Translation
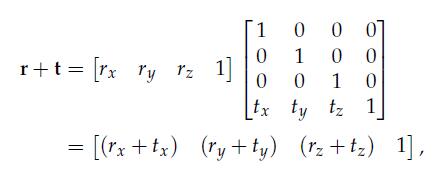
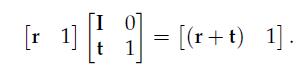
To invert a pure translation matrix, simply negate the vector t (i.e., negate tx, ty and tz).
21、Rotation

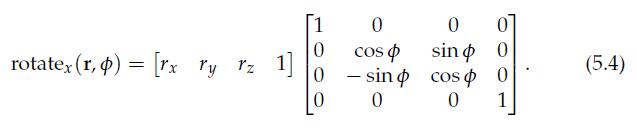

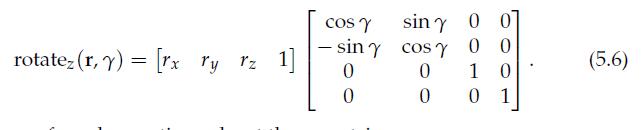
上面三个 xyz 旋转,对角线都是 cos,cos,1,另一个对角线是 sin,-sin,旋转方向后面轴的 sin为正,旋转方向前面轴的sin为-。
22、Scale

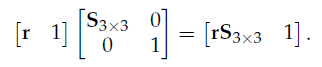
Scale 的逆矩阵不能通过 transpose 来求,因为 scale后,每一个轴向量不再是 unit vector,不满足 orthonormal 性质,所以无法通过 transpose 来求 逆矩阵。
• When a uniform scale matrix Su and a rotation matrix R are concatenated, the order of multiplication is unimportant (i.e., SuR = RSu). This only works for uniform scale!
23、4x3 Matrices
As such, game programmers often omit the fourth column to save memory. You’ll encounter 4 x 3 affine matrices frequently in game.
24、Coordinate Spaces
We said above that a point is a vector whose tail is fixed to the origin of some coordinate system. This is another way of saying that a point (position vector) is always expressed relative to a set of coordinate axes.
25、Model Space
• pitch is rotation about L or R,
• yaw is rotation about U, and
• roll is rotation about F.
26、Building a Change of Basis Matrix

• iC is the unit basis vector along the child space x-axis, expressed in parent-space coordinates;
• jC is the unit basis vector along the child space y-axis, in parent space;
• kC is the unit basis vector along the child space z-axis, in parent space; and
• tC is the translation of the child coordinate system relative to parent space.
27、Transforming Normal Vectors
Special care must be taken when transforming a normal vector to ensure that both its length and perpendicularity properties are maintained.
In general, if a point or (non-normal) vector can be rotated from space A to space B via the 3x3 matrixMA->B, then a normal vector n will be transformed from space A to space B via the inverse transpose of that matrix.
if the matrix MA->B contains only uniform scale and no shear, then the angles between all surfaces and vectors in space B will be the same as they were in space A.
28、Quaternions
a matrix is not always an ideal representation of a rotation, for a number of reasons:
1) We need nine floating-point values to represent a rotation, which seems excessive considering that we only have three degrees of freedom— pitch, yaw and roll.
费空间。
2)Rotating a vector requires a vector-matrix multiplication, which involves three dot products, or a total of nine multiplications and six additions. We would like to find a rotational representation that is less expensive to calculate, if possible
费CPU,计算量大。
3)to find rotations that are some percentage of the way between two known rotations is difficult.
不便插值。

29、Unit Quaternions as 3D Rotations
So the unit quaternion q can be written as:
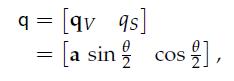
a is a unit vector along the axis of rotation, and q is the angle of rotation.
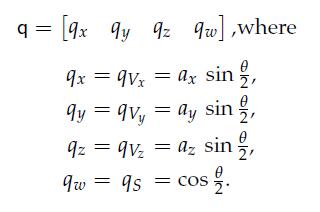
30、Quaternion Multiplication
Given two quaternions p and q representing two rotations P and Q, respectively, the product pq represents the composite rotation (i.e., rotation Q followed by rotation P).
四元数乘积 PQ 的含意为,先应用P,再应用Q。
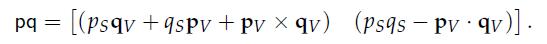
31、Conjugate and Inverse.
Conjugate:

negate the vector part but leave the scalar part unchanged.
Inverse quaternion:


32、Conjugate and Inverse of a Product
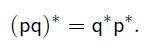
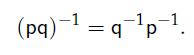
33、Rotating Vectors with Quaternions
Therefore, the rotated vector v′ can be found as follows:
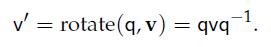
when quaternion is unit, we can use conjugate:
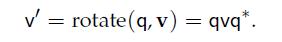
34、Quaternion Concatenation

35、Quaternion-Matrix Equivalence
If we let q = [qV qS] = [qVx qVy qVz qS] =[ x y z w], then we can find R as follows:

36、Rotational Linear Interpolation
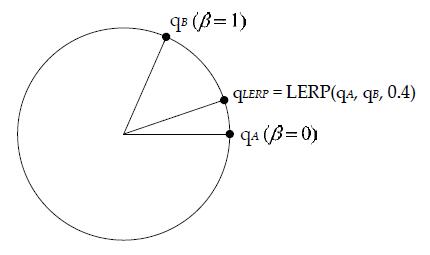

The resultant interpolated quaternion had to be renormalized.
37、Spherical Linear Interpolation
LERP 的 beta 平滑插值,但并不代表 quaternion 平滑插值。实际上,beta 的平滑插值,会导致 quaternion 两头变化慢,中间变化快的问题。
SLERP 可以解决上面的问题。
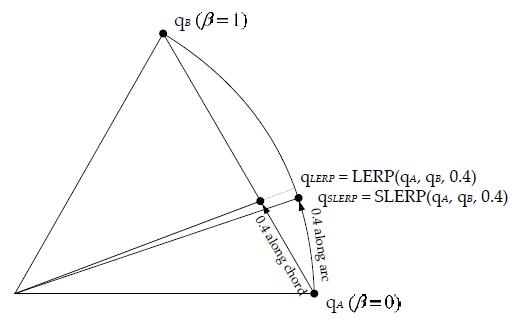
![]()
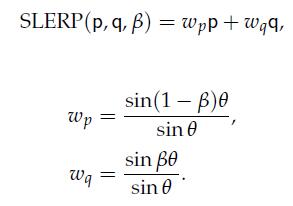
38、To SLERP or Not to SLERP
Jonathan Blow wrote a great article positing that SLERP is too expensive, and LERP’s quality is not really that bad—therefore, he suggests, we should understand SLERP but avoid it in our game engines.
On the other hand, some of my colleagues at Naughty Dog have found that a good SLERP implementation performs nearly as well as LERP. (For example, on the PS3’s SPUs, Naughty Dog’s Ice team’s implementation of SLERP takes 20 cycles per joint, while its LERP implementation takes 16.25 cycles per joint.)
39、Euler Angles
Euler angles are prone to a condition known as gimbal lock.
Another problem with Euler angles is that the order in which the rotations are performed around each axis matters. The order could be PYR, YPR, RYP and so on, and each ordering may produce a different composite rotation. So the rotation angles [ qY qP qR ] do not uniquely define a particular rotation—you need to know the rotation order to interpret these numbers properly
40、3 x 3 Matrices
It does not suffer from gimbal lock.
However, rotation matrices are not particularly intuitive.
41、Axis + Angle
The benefits of the axis+angle representation are that it is reasonably intuitive and also compact.
42、Quaternions
it permits rotations to be concatenated and applied directly to points and vectors via quaternion multiplication.
43、
44、