在以前的练习中,我们讨论了归档重做日志文件,对归档重做日志文件进行了备份并用于恢复操作,利用这些文件可以把改变传递到一个备用数据库中并将一个表空间及时恢复到一个特定的时间点。你是否考虑到什么方法可以直接观察一个Oracle重做日志文件的内部结构?从Oracle8i开始可以是用LogMiner工具查看一个或者多个日志文件的内容,包括一些数据字典视图和存储过程。在本练习中将练习安装LogMiner,并使用LogMiner来查看和分析数据库重做日志文件的内容。
当Oracle改变数据块时,它把重做信息写入当前的联机重做日志文件。重做日志文件包括更改时间、对象标识符、更改的SCN号、数据块发生的操作和其他的重要信息,该文件不但包括使用者对数据块所做的更改,也包括回退段中恢复块的更改。Oracle在数据字典中使用数字标识符来标识对象的相关信息,例如为一个表制定一个对象号,并且每列有一个列标志符,每列都有一个相应的数据类型标识符,表示该列是varchar2、date、number等变量。使用LogMiner,可以读出重做文件的内容,然后重新产生或恢复产生原始重做信息的SQL表达式,使用数据字典文件,LogMiner将Oracle对象标识符翻译成可以看得懂的表和列。
在进行本练习之前对相关数据进行解释:
- 当前数据库(Current database):当LogMiner使用产生日志文件的服务器来分析重做日志文件时,重做日志文件来自当前数据库;
- 外部数据库(Foreign database):当LogMiner可以分析异于当前数据库的其他数据库产生的重做日志文件,该数据库就是有一个外部数据库;
- 字典文件(Dictionary file):LogMiner使用字典文件将Oracle内部对象标识与表名称、列、数据类型以及其他对象关联起来,需要注意的是字典文件必须由创建重做日志文件的数据库产生。
很多情况下需要使用LogMiner:如数据库表中的数据莫名其妙被修改了,使用LogMiner可以检查哪个改变的运行细节,也可以使用LogMiner来撤销这些更改;可以使用LogMiner检查一个或多个表中SQL改变发生的次数,从而检查表上的工作量;通过进一步检查,LogMiner可以指出一个错误的DROP TABLE或者一个DDL语句发生的准确时间和SCN。
使用LogMiner需要理解以下要点:
- 可以在一个已经加载或者未加载的数据库上使用LogMiner;
- 分析一个来自外来数据库重做日志文件时,当前数据库的块大小必须和外部数据库一样的或者更大,因为在热备份模式,表空间中一个块的首次改变作为一个单独的重做记录在重做流中创建一个完整的镜像。如果LogMiner使用较小的块尺寸的数据库读取重做会发生错误,因为单独的重做记录无法放入一个块中;
- 虽然LogMiner不解释重做日志的DDL语句,如DROP TABLE这样的DDL语句,但仍旧会在数据字典创建DML,这些字典DML语句可以用来检查对数据库发布的DDL命令;
- LogMiner不会重构原始的无日志的SQL操作,但在数据字典上的DML操作结果将记录到日志文件里;
- 虽然LogMiner可以偶然用来日志文件分析,但不能当做常规意义上使用的一种功能,特别是一个产生庞大数量重做信息的数据库挖掘重做信息,使用LogMiner分析庞大数量的重做信息是一件非常耗费时间的事情;
- 如果LogMiner用来从其他数据库的日志文件里挖掘信息,无论原数据库还是被分析的数据库都必须在使用相同的硬件平台和操作系统,而且原数据库和被分析数据库必须使用相同的字符集;
- LogMiner无法分析某些数据库对象或数据类型产生的重做,例如:按索引组织的表、成簇的表/索引、非标量数据类型和链接的行;
- 尽管可以创建数据字典DML,但LogMiner无法从直接的路径插入操作中生成原始的SQL;
- LogMiner将显示为提交的事务,因为重做日志包含提交的和未提交的数据。
练习18:分析重做文件
通过LogMiner读取重做日志事务涉及使用Oracle提供的包过程、数据字典视图和一个数据字典外部文件。下面是应用LogMiner分析重做日志文件的操作过程:使用LogMiner存储过程创建一个外部数据字典文件;然后使用另一个存储过程创建一个分析重做文件的列表;最后,执行另一个存储过程来启动LogMiner。在完成这些步骤以后,从一个显示日志文件内容的数据字典视图里进行选择,当查询这个视图时,Oracle读取日志文件,然后以特定格式返回结果,一旦分析列出的日志文件,就调用另一个存储过程停止LogMiner。
|
类型 |
过程名 |
用途 |
|
过程 |
Dbms_logmnr_d.build |
创建一个数据字典文件 |
|
过程 |
Dbms_logmnr.add_logfile |
在类表中增加日志文件以供分析 |
|
过程 |
Dbms_logmnr.start_logmnr |
使用一个可选的字典文件和前面确定要分析日志文件来启动LogMiner |
|
过程 |
Dbms_logmnr.end_logmnr |
停止LogMiner分析 |
|
视图 |
V$logmnr_dictionary |
显示用来决定对象ID名称的字典文件的信息 |
|
视图 |
V$logmnr_logs |
在LogMiner启动时显示分析的日志列表 |
|
视图 |
V$logmnr_contents |
LogMiner启动后,可以使用该视图在SQL提示符下输入SQL语句来查询重做日志的内容 |
在本练习中,将观察SCOTT.EMP表中一行记录的特定改变的详细情况,然后看到如何通过分析一个特定表上记录改变操作的重做日志文件来检查这个表数据库更改操作,最后将学会怎样为一个特定的DROP TABLE命令确定准确的时间和SCN。
步骤一:创建数据字典文件
使用LogMiner创建数据字典是一个可选步骤,字典文件极大增加了日志文件内容的可读性。
数据字典建立Oracle内部对象ID数据到表、列以及其他数据类型名称之间的对应关系,数据字典是一个文本文件,相当于数据字典的相关部分。本步骤中将创建一个数据字典文件,然后指示LogMiner应用该文件把内容的数据翻译成步骤四中分析日志文件能够识别的名称。
- 字典文件应该和日志文件的日期一致,如果LogMiner分析的一个对象无法在字典文件中找到,LogMiner将无法显示数据库对象的表和列的名称;
- 建立字典文件的数据库必须和建立日志文件的数据库相同,例如,不能使用克隆数据库中的字典文件来分析PRACTICE数据库中的日志文件。
在建立数据字典文件之前,PRACTICE数据库必须写到服务器硬盘的一个目录下。Oracle10g之前数据库参数文件内设置UTL_FILE_DIR这个参数运行为Orace可以使用的PL/SQL文件I/O定义一个或多个目录,可以在这个参数文件里连续地分行输入UTL_FILE_DIR,以定义更多的目录,如下所示:

为了创建一个数据字典文件,可以执行DBMS_LOGMNR_D包中的BUILD过程,该过程查询当前的数据库字典表,然后创建一个包含其内容基于文本的文件。该文件在调用的过程目录中生成,执行的过程如下:
 该过程执行后,在D:\oracle\CODE\chap10目录下打开文件dictionary.ora,浏览其内容。
该过程执行后,在D:\oracle\CODE\chap10目录下打开文件dictionary.ora,浏览其内容。 
步骤二:产生数据库操作
本步骤中进行的操作将在步骤五进行分析验证。
首先确认在TINA.DATE_LOG表中生成行记录。
其次,改变SCOTT.EMP表的一行记录,使用下面的SQL语句改变其中一个雇员的薪水和佣金:
2 SQL>UPDATE emp SET sal=3000, comm=5000 where empno=7844;
3 SQL>COMMIT;

使用SQL*PLUS命令”SET TIME ON”,记录这些SQL命令运行的时间,set time on 命令生效后给SQL提示增加一个时间值,如下所示:

UPDATE和DROP(字典中对应的DML)语句的重做信息将保存在当前联机重做日志文件中,从v$log视图中找出日志文件的序号,最后做一个日志切换使当前联机日志归档。运行LogMiner来分析这个新归档的日志文件,试验一下是否能从这个日志中找到关于SQL更新和删除表的信息。
2 SQL>ALTER SYSTEM SWITCH LOGFILE;
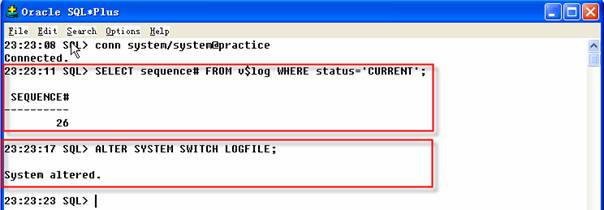
在本练习讨论中,日志切换前的当前日志序号是26,因此日志切换期间产生的归档日志文件的名称是ARC00026_0707328257.001。
步骤三:分析指定日志文件
LogMiner需创建一个可供分析日志文件列表来分析指定的日志文件,使用Oracle提供的DBMS_LOGMNR包中的ADD_LOGFILE过程来添加日志文件,增加的日志文件显示在v$logmnr_logs视图里。
2 SQL>SELECT db_name, thread_sqn, filename FROM v$logmnr_logs;

前一个任务中SQL所做的改变保存在序号为26的日志文件中,在LogMiner分析前添加该日志文件和前面的两个文件。
2 dbms_logmnr.add_logfile(logfilename=>'D:\oracle\PRACTICE\ARCHIVE\ARC00024_0707328257.001', options=>dbms_logmnr.NEW);
3 dbms_logmnr.add_logfile(logfilename=>'D:\oracle\PRACTICE\ARCHIVE\ARC00025_0707328257.001', options=>dbms_logmnr.ADDFILE);
4 dbms_logmnr.add_logfile(logfilename=>'D:\oracle\PRACTICE\ARCHIVE\ARC00026_0707328257.001', options=>dbms_logmnr.ADDFILE);
5 END;
6 /

Add_logfile过程第一次调用时,选项设置为dbms_logmnr.NEW,这就创建了供LogMiner分析新的日志文件列表;之后调用add_logfile过程,使用ADDFILE选项为新建立的列表添加文件。每次使用NEW选项时,任何在此之前添加的文件将从该列表删除。
查询v$logmnr_logs视图将看到已经添加到列表中文件:

可以在DBMS_LOGMNR.ADD_LOGFILE过程中指定REMOVEFILE选项来删除重做日志文件,在本练习中序号100的日志文件没有包含寻找的重做信息,因此可以将序号100的日志文件从分析的列表中删除:

步骤四:启动LogMiner
准备好字典文件和日志文件列表后,准备启动LogMiner:

可以为该过程有选择地制定其他几个参数,可以指定分析开始的SCN或结束的SCN;可以制定分析开始时间或结束是时间。如果必须分析大量的归档日志或者只想查看很少一段时间内的重做,这两个参数很有帮助。
步骤五:分析重做日志文件内容
在V$LOGMNR_CONTENTS视图中,包含日志文件ARC00024_0707328257.001和ARC00025_0707328257.001内容,当查询V$LOGMNR_CONTENTS视图时,包括在V$LOGMNR_CONTENTS的日志文件将顺序读出,并以V$LOGMNR_CONTENTS视图定义的行结构返回数据(该视图有53列)。所有日志文件内容不是永久存放在一个表或者内存中,因此每次选择有关V$LOGMNR_CONTENTS内容时,日志文件都被扫描。如果需要多次检查大量的日志文件来寻找需要的内容,那么最好使用CREATE TABLE AS SELECT(CTAS)命令制作一个结果的表。
|
列名称 |
描述 |
|
OPERATION |
重做记录中记录的操作(INSERT、UPDATE、DELETE等) |
|
TIMESTAMP |
数据改变发生的日期和时间 |
|
SCN |
特定数据变化的系统变更号 |
|
SEG_OWNER |
段所有者名称(如果段发生变更) |
|
SEG_NAME |
数据发生改变的段名称 |
|
SEG_TYPYE |
数据发生改变的段类型 |
|
TABLE_SPACE_NAME |
变化段的表空间名称 |
|
ROW_ID |
特定数据变化行的ID |
|
USER_NAME |
执行数据改变的用户名 |
|
SESSION_INFO |
数据发生变化时用户进程信息 |
|
SQL_REDO |
可以为重做记录重做指定行变化的SQL语句 |
|
SQL_UNDO |
可以为重做记录回退或恢复指定行变化的SQL语句 |
在该步骤中,将使用PRACTICE数据库中的重做信息完成三件事情:
- 确定数据改变的细节,确认一个雇员薪水更改的细节;
- 完成容量分析,检查TINA.DATE_LOG表的工作量;
- 确定DDL命令的详细情况,定位SCN和删除表的时间。
检查数据更改的细节
数据库里的数据可能因为意想不到的原因或者因为错误而发生改变,在重做日志文件中可以找到这些更改的细节。在本练习中,可能有报告显示一个雇员的薪水和佣金发生了改变,经理告诉你,有一个名叫Turner的销售员的薪水和佣金发生改变了,她希望你能查出发生什么事以及改变前的薪水和佣金数,她还想知道更多的细节,比如是谁做了这些改变以及改变是如何发生。
回答她的问题,需要查找设计SCOTT.EMP表的所有SQL语句,该表有一个表示当前薪水的SAL列和表示佣金的COMM列,要找到所有涉及这个表的SQL,可以运行如下SELECT语句:
2 FROM v$logmnr_contents
3 WHERE seg_name='EMP'
4 AND seg_owner='SCOTT'
5 AND seg_type_name='TABLE';
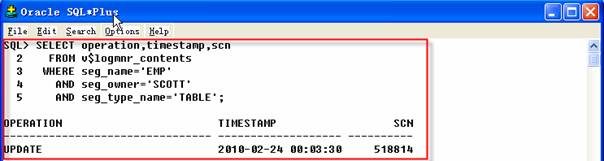
可以看出结果,在1月10日上午10:42对SCOTT.EMP表执行了更新操作,要找出该表所有的具体改变,最好查看SQL_REDO和SQL_UNDO列:
2 FROM v$logmnr_contents
3 WHERE seg_name='EMP'
4 AND seg_owner='SCOTT'
5 AND seg_type_name='TABLE';

SQL_REDO列定义了特定的SQL语句,可以使你得到与步骤二中SQL同样的结果;SQL_UNDO列包括的SQL允许撤销SQL_REDO的改变,实际上,它表示更改前的数据值。找到了数据的更改和更改发生的时间,还想弄清楚谁做了这个更改?查看V$LOGMNR_CONTENTS的USERNAME列和SESSION_INFO列,在这些列中,将知道有用的会话信息,可以帮助进一步解释Tuner的薪水是如何改变的。
2 FROM v$logmnr_contents
3 WHERE seg_name='EMP'
4 AND seg_owner='SCOTT'
5 AND seg_type_name='TABLE';
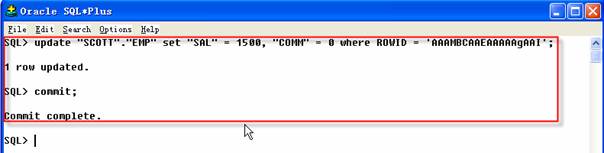
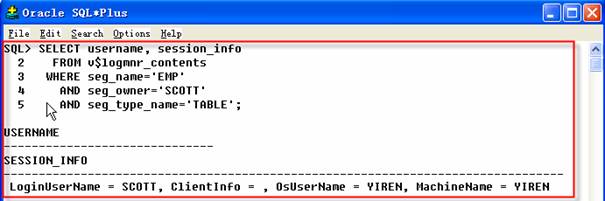 可以看到某人使用用户名SCOTT登录并执行更新操作,知道该嫌疑人使用名叫YIREN的操作系统登录名叫YIREN机器上。你可以把这个信息报告给经理,同时使用SQL_UNDO列的内容把数据恢复到改变以前的数值,检查当前存在表内该行的内容,确保他没有改变后续的时间。
可以看到某人使用用户名SCOTT登录并执行更新操作,知道该嫌疑人使用名叫YIREN的操作系统登录名叫YIREN机器上。你可以把这个信息报告给经理,同时使用SQL_UNDO列的内容把数据恢复到改变以前的数值,检查当前存在表内该行的内容,确保他没有改变后续的时间。
2 SQL>COMMIT;
执行容量分析
作为DBA需要做一些性能调整或容量计划,要完成该任务可能设计到使用许多不同的工具和程序,LogMiner是用来检查数据库表发生活动非常合适的工具。例如,LogMiner帮助调查表中DML次数和频率,虽然使用表审计来实现同样的功能,但当更新表的时候使用LogMiner不会减低运行时间性能,而是用表审计会导致运行时间能能开销过大。
下面我们查询一下TINA.DATE_LOG表的SQL操作,启动LogMiner检查这个表执行插入、更新和删除的次数。下面这个非常简单的例子为分析数据表上DML操作提供了一些思路和方法:
2 FROM v$logmnr_contents
3 WHERE seg_name='EMP'
4 AND seg_owner='SCOTT'
5 GROUP BY operation, to_char(timestamp, 'HH');

查询的结果显示,DATE_LOG每小时增加6行记录。
当必须分析大量中作信息时,要在全面分析和分析速度之间进行权衡。添加到LogMiner列表中待分析的日志文件越多,可以分析的重做信息也就越多,然而LogMiner列表太多或者太大的日志文件,访问V$LOGMNR_CONTENTS视图将会花费更长的时间。
寻找DDL命令的细节
就像本练习所做的一样,在前面练习模拟了一个一位删除表的操作,在那些练习中我们曾经提到要知道错误删除表的时间比较困难。使用LogMiner可以推算出删除表语句的确切时间和SCN,可以将这个时间或者SCN用于不完全数据库恢复或者表空间时时检点恢复(TSPITR)。
如前所述,LogMiner只是将重做日志信息翻译成数据处理语言(插入、更新、删除),在V$LOGMNR_CONTENTS视图中将不会找到DROP TABLE语句。既然在DROP TABLE语句在数据字典表上运行了DML,那么可以从SYS.OBJ$和SYS.TAB$数据字典表中搜索发生删除操作的视图。
2 FROM v$logmnr_contents
3 WHERE operation='DELETE' and timestamp >= to_date('2010-02-23 23:20:00', 'yyyy-MM-dd HH24:mi:ss')
4 and timestamp <= to_date('2010-02-23 23:23:00', 'yyyy-MM-dd HH24:mi:ss')
5 GROUP BY seg_name, operation, scn, timestamp
6 ORDER BY scn;
从以上SQL结果可以看出,在'2010-02-23 23:23:00,一个对象,一个表和四个列(SCOTT.BONUS有四列)从数据字典删除了。这个数据字典对象删除操作可能就是删除bonus表语句,接下来可以查看DROP TABLE命令的SQL_REDO:
在SQL_REDO列的输出中有OBJ#,这个和OBJ#相关联的数值和存放在数据字典表TAB$.OBJ#红的Oracle ID一致。要将删除表和执行删除表的SQL语句发生的时间时间和SCN联系到一起,需要删除表在何时删除以及表中包含多少列,使用这个信息,就可以找出准确的时间以及用户信息。通过文本编辑器打开字典文件,查找单词BONUS,将看到如下插入语句:
如果没有在字典文件中找到相关BONUS的记录,就不可能在数据库中已有这个表的情况下创建这个字典文件,如果是这种情况,就必须根据自己的判断拼凑被删除表的数据。在SQL_REDO列内的OBJ#数值和第一次为删除表而插入到数据字典文件的数值完全相同,如果把这些信息关联起来,就可以确信删除表的时间为2010-2-23 23:21:52,SCN号为521934,如果必要,使用这些数值可以执行TSPITR。
简而言之,可以通过将数据字典文件的对象编码与删除操作发生的SYS.OBJ$数据字典表的SQL_REDO列的对象标识符向匹配,已找到删除表命令发生的时间和SCN。
步骤六:关闭LogMiner
使用LogMiner后,需要释放该程序使用的资源,当完成LogMiner工作后,V$LOGMNR_CONTENTS的内容就不再可用,如果需要更进一步分析重做日志文件的内容,使用V$LOGMNR_CONTENTS视图内容创建一个永久的数据库表将非常有帮助。

一旦完成重做日志的检查,运行DBMS_LOGMNR中的END_LOGMNR。
结束LogMiner时,释放为重做日志分析分配的会话内存